
我要认证
2026-05-08
用大模型读长文档,你是不是也经常被气到,答案看着头头是道,一翻原文全是编的。
其实还真别怪AI模型,问题出在检索上。主流RAG方案用的都是向量检索,先把文档切成小段,算向量存进数据库,提问的时候靠语义相似度去匹配。
因为向量匹配只看词语像不像,不管逻辑对不对。这事在AI圈子里有个说法叫vibe retrieval,凭感觉检索,蒙对了运气好,蒙错了你连错在哪都不知道。
最近有一个挺炸的开源超29600星的PageIndex,颠覆了传统RAG玩法,把这个问题解决了。

开源地址:https://github.com/VectifyAI/PageIndex
PageIndex的核心技术思路是不做向量匹配,不切块,而是让大模型像人一样翻文档。
你拿到一本厚书要查东西,肯定先看目录对吧,锁定章节再往下看小节标题,一层一层缩小范围直到找到具体段落。
PageIndex就是把这个过程教给了大模型。它拿到文档后先自动梳理出一棵完整的结构化目录树,每个节点都有标题、摘要和对应页码。
提问的时候大模型沿着这棵树一步步推理,先定大方向再逐步聚焦,最终精确定位到你需要的那个段落。
相似不等于相关四个字谁都懂,但整个RAG行业一直在向量检索这条路上死磕,没几个人停下来想过这条路本身对不对。
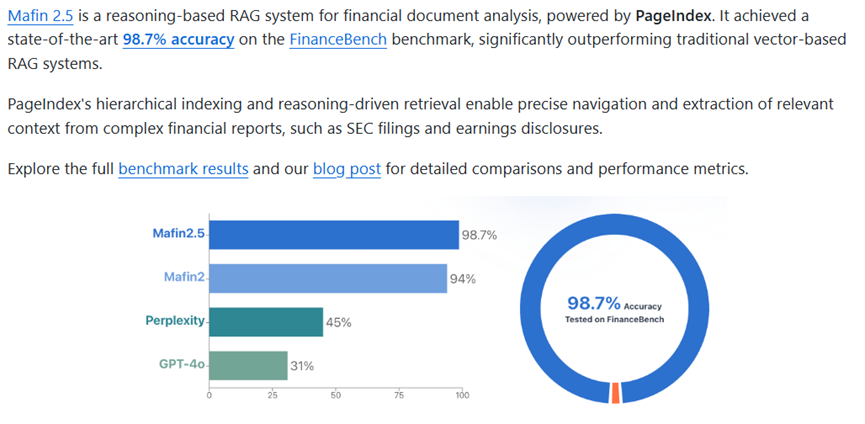
PageIndex直接跳出来说这条路有问题,用推理替代搜索,而且甩出了硬数据。在Finance Bench这个金融文档问答数据集上,准确率干到了98.7%。这个数字放在专业文档分析领域就是碾压。
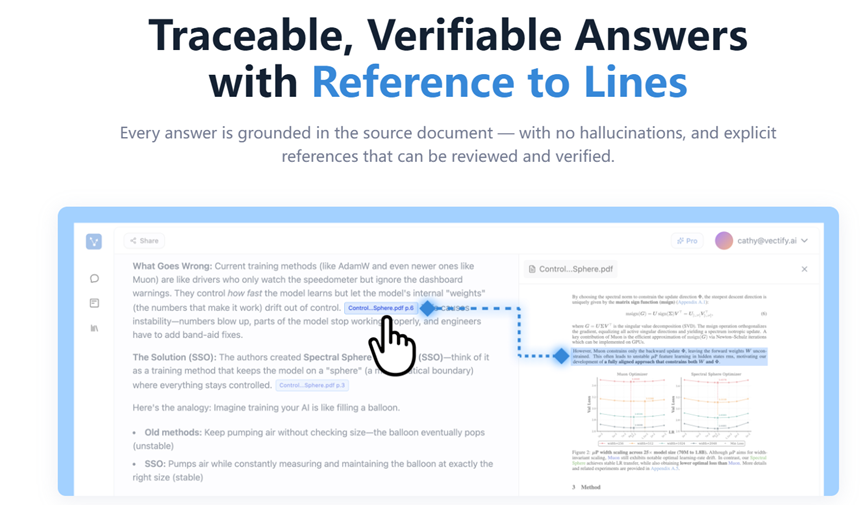
PageIndex具体好用在哪,选几个最实用的功能给大家瞅瞅。找到的东西能看到来源。
以前向量检索返回一段话你根本不知道它从哪来的。PageIndex每次都会告诉你内容来自第几页哪个章节,推理路径是什么。
就像让同事帮你查资料,他不仅把答案递过来,还把书页码都标好了,你一翻就能验证。金融、法律这种一个数字都不能搞错的场景,这是刚需。
能记得你之前聊了什么,传统向量检索每次提问都是独立的,系统不知道你上回问了啥。但PageIndex的检索带对话历史,能结合前面的上下文做更精准的推理。
你先问了一家公司的营收,接着追问增长率,它知道你还在聊营收这个话题,不会乱跑。
审计报告、招股书、学术论文动不动上百页,章节嵌套章节、图表穿插在正文中间,传统切块处理简直是灾难。
但PageIndex本身就是按文档自然层级组织的,它模仿人类专家的阅读方式,先看大标题定方向,再看小标题缩范围,最后落到具体段落。

这种树搜索思路跟谷歌的AlphaGo下棋有点像,都是在决策树上做推理和选择,只不过一个在棋盘上落子,一个在文档树里定位。
登录/注册后继续阅读
立即登录/注册 >






























