
我要认证
2026-05-07
今天想跟大家聊聊Zyphra刚开源的超强小参数模型ZAYA1-8B。这小玩意说实话有点意思,还是用AMD芯片训练的。
咱们平时看大模型新闻,总感觉参数量不上百亿就不叫模型。ZAYA1-8B是个混合专家架构的模型,真正干活的时候激活参数还不到10亿。
开源地址:https://huggingface.co/Zyphra/ZAYA1-8B
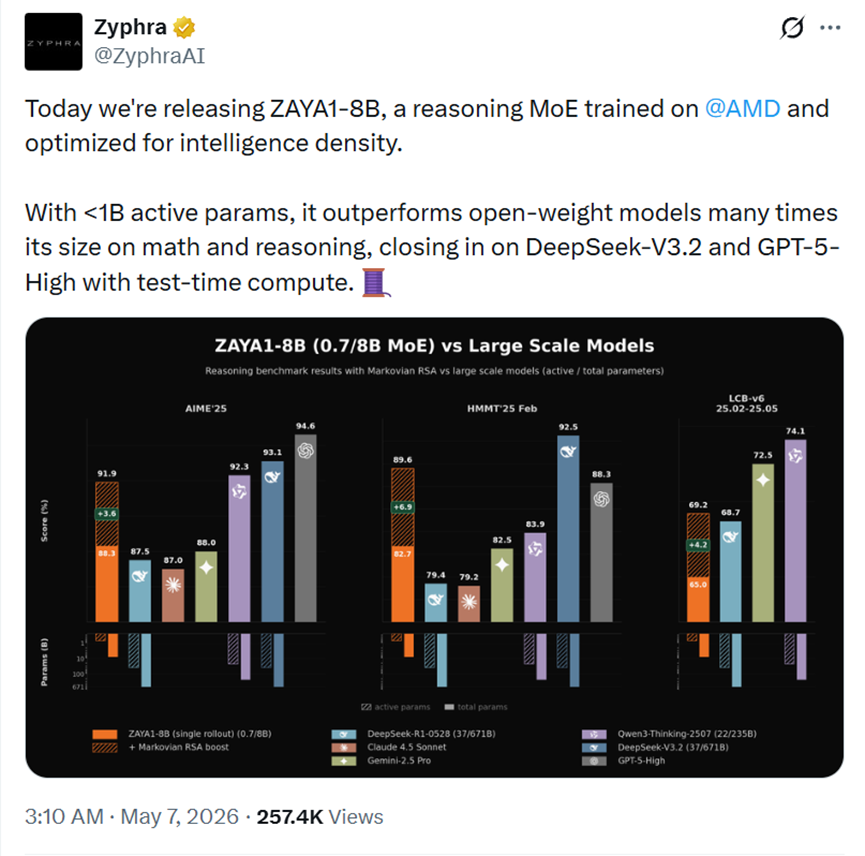
但就这点体量,跑起数学和写代码的活来,居然能反超那些参数量比自己大几十倍的大家伙。
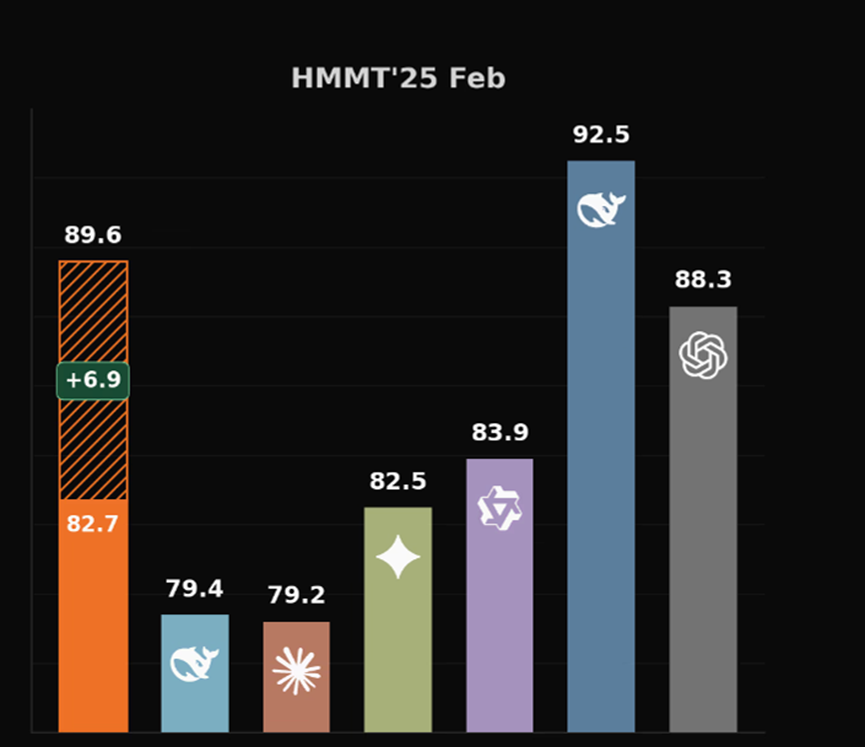
例如,在HMMT这个挺难的数学比赛数据集上,分数直接干到了89.6,硬生生超过了GPT-5的高配版和Claude4.5 Sonnet这些著名闭源模型。
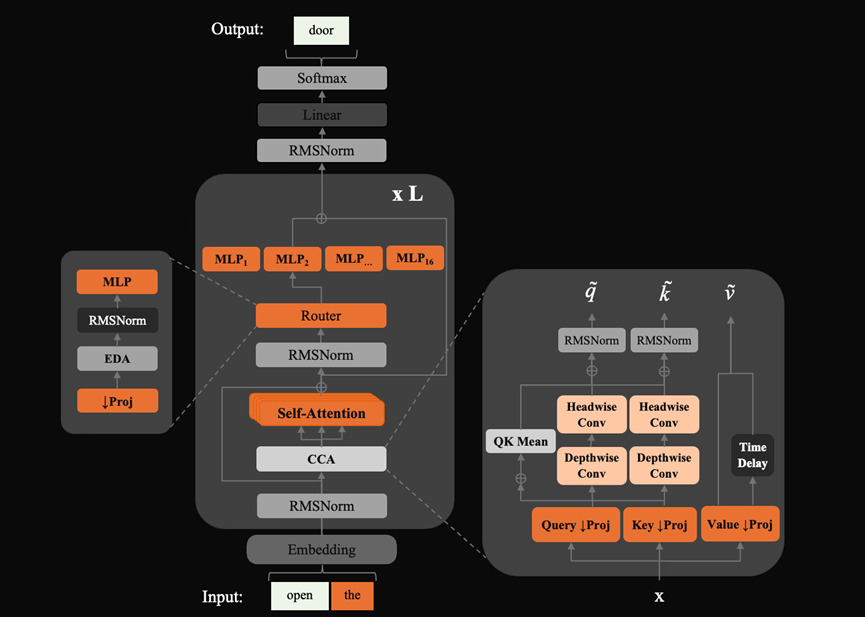
这么小的参数性能还这么强,主要是因为Zyphra在设计上死磕了一个点,就是每一分算力每一颗参数都得榨干它的智商。
他们弄了三个挺巧妙的改动,一个是CCA的注意力机制。简单理解就是给模型装了个“过滤器”,把没用的信息过滤掉只保留精华。
再加上它那个混合专家架构,就像是组建了一个AI专家团队,遇到数学题就叫数学专家,遇到写代码就叫程序员专家,各司其职推理效率自然高效。
接着他们把选专家的路由器从以前那种简单的直线判断换成了一个小型的多层感知机网络,这样模型在挑谁来干活的时候就不会手忙脚乱出岔子。
还加了个可以自己学习的残差缩放开关,花极小的代价就把模型太深导致的数值发散问题给治住了。这三板斧一下来,整个模型的底子就变得特别精干。
说说它的出身,这点可能很多非硬核玩家不知道,但真的很有意义。以前咱们训练这种级别的模型,基本都得抱英伟达的大腿。
毕竟显卡就那几家强。但Zaya1-8B是个异类,它是完全在AMD的硬件上跑出来的。
用了1024张AMD的MI300X显卡,硬是把这个大家伙给练成了。这也说明AMD现在的AI生态也是好起来了。
以后咱们搞AI训练,又多了一个选择。这对咱们用户来说绝对是好事,毕竟有竞争才有性价比嘛。
不过真正让这个模型脱胎换骨的,其实是他们后面那套极其繁琐但也极其管用的后训练流程。
一共分了五步,每一步都在给模型开小灶。一开始先教它最基础的聊天和听指令,接着就开始给它喂逻辑题,让它学会自己把几个候选答案糅合在一起。
登录/注册后继续阅读
立即登录/注册 >






























