
我要认证
2026-05-03
前阵子无意间点进了小红书技术实验室的一个开源库,刚打开的时候其实没太当回事,心想又是一个OCR工具嘛,市面上这类东西也不少了。
但往下翻了几行之后,我发现这个dots.ocr跟之前见过的所有OCR方案都不太一样。它是把视觉语言模型直接拉到了文档解析这件事上面来做的,用一个词概括就是多语言文档版面理解。
不止识别文字,连图表、化学式、网页截图都能处理,并且能把这些结构化图形直接转成可编辑的SVG代码。

开源地址:https://huggingface.co/rednote-hilab/dots.mocr
这个功能确实强的离谱,之前用过不少OCR工具,有的只能认纯文本,有的能认表格但格式全乱,有的碰到扫描件模糊的老文件直接翻车,更别提混排的中英文或者满屏数学公式的学术论文了。
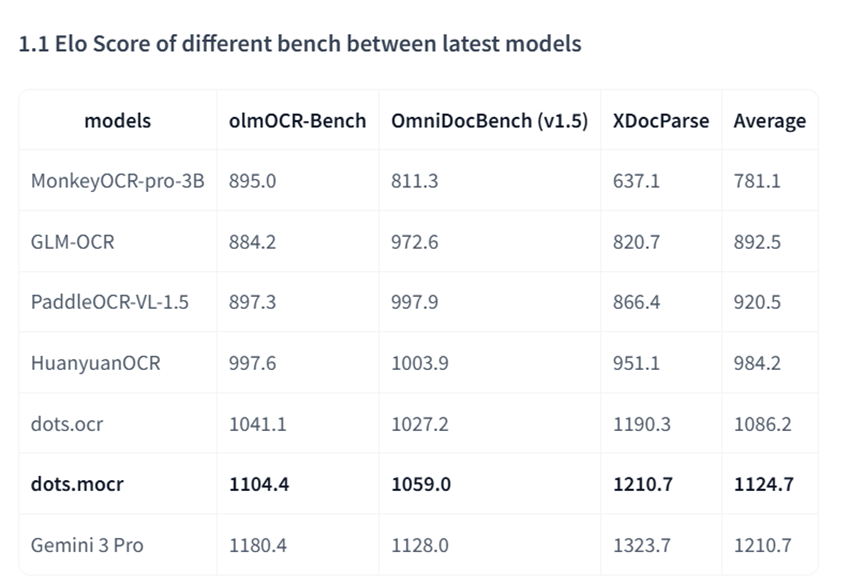
结果这个dots.ocr,就一个30亿参数的小模型,居然在多个权威评测榜单上干到了同类模型里的最高水平,综合评分甚至压过了一堆用API调的闭源大模型方案,仅次于谷歌的Gemini 3 Pro。
那咱们继续唠唠dots.ocr的特色功能,多语言文字识别这块就不用多说了,它的目标几乎就是人类能写出来的任何文字体系它都想认,东亚字符、阿拉伯文、印地文、西里尔字母之类的全都在覆盖范围内。
例如,你去旅游拍了一块路牌,上面写了三种语言,扔给它基本上都能认出来。
对于经常需要处理跨国文档的朋友来说,这个功能直接省掉了很多翻译前期的录入工作。
从这不难看出,小红书研发、开源这个模型也挺贴合它那个平台的旅游属性的。
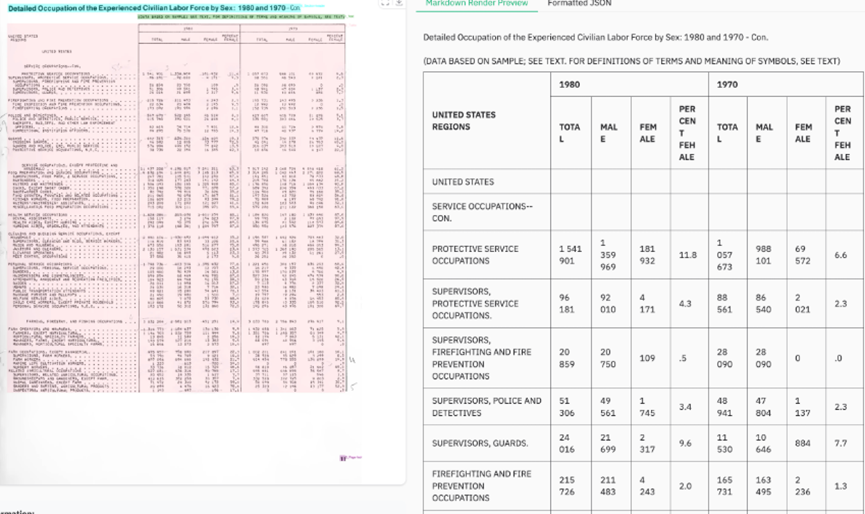
版面结构理解是它真正拉开差距的地方。你知道很多传统OCR工具最让人头疼的问题是什么吗?
就是它只管把字认出来,至于这些字在页面上是怎么排列的,哪段是标题哪段是正文,表格的行列关系是什么,它根本不在乎。
但dots.ocr不一样,它能理解整个文档的版面布局,标题层级、段落顺序、多栏排版、页眉页脚这些都能拆得清清楚楚,最后输出的是一份结构化的markdown文件。
你可以想象成它不是在抄写一页纸,而是在理解这页纸的逻辑结构之后再重新排版给你。
图表和图形的解析就更有点黑科技的味道了。普通的OCR遇到柱状图、折线图、流程图这种图形元素基本就瞎了,最多给你截个图保存下来。
dots.ocr能直接把图表转成SVG代码,就是那种可以无损放大缩小还能编辑每一个元素的矢量图格式。
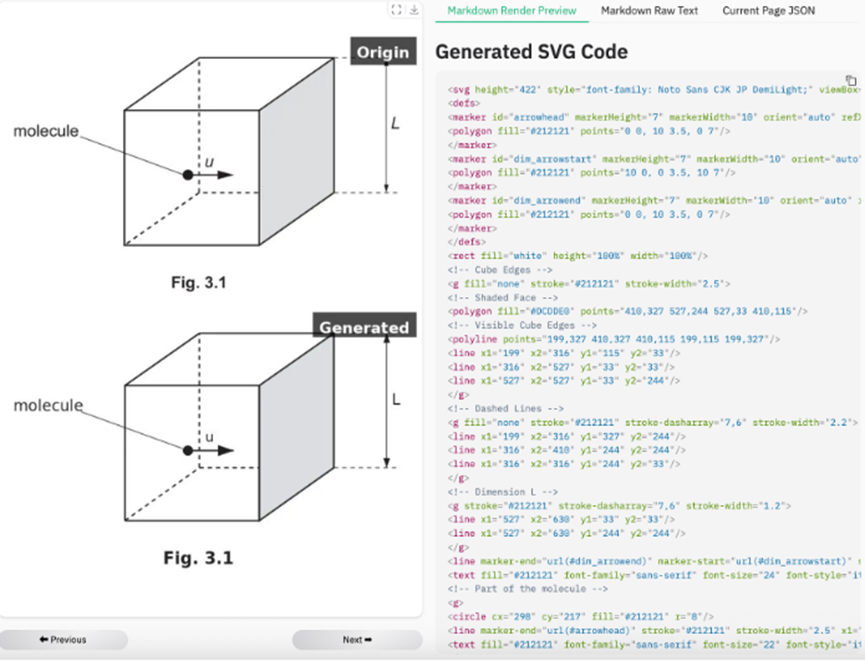
你拿到的不是一个死的图片,而是一份活的数据可视化源码。这个能力放在以前,基本只有专门的图形识别工具才能做到,现在被集成到了一个文档解析模型里面。
网页截图解析和场景文字识别这两个功能可能乍一看不太起眼,但实际用起来非常顺手。比如你截了一张网页截图想提取里面的内容,或者你在大街上拍了一个招牌想查一下上面的信息,直接丢给它就行。
它的场景文字识别能力在通用视觉任务评测里也拿到了相当不错的成绩。
登录/注册后继续阅读
立即登录/注册 >






























