
我要认证
2026-04-24
今天中午11点,DeepSeek-V4预览版终于开源了。
这一次DeepSeek没有停留在参数堆砌,而是从底层架构到实际效率全链路突破。
不仅把100万上下文做到真正可用,还在多项核心能力上超越Opus-4.6,仅次于GPT-5.4、Gemini-3.1-Pro顶尖模型,成为当前最强开源模型之一。
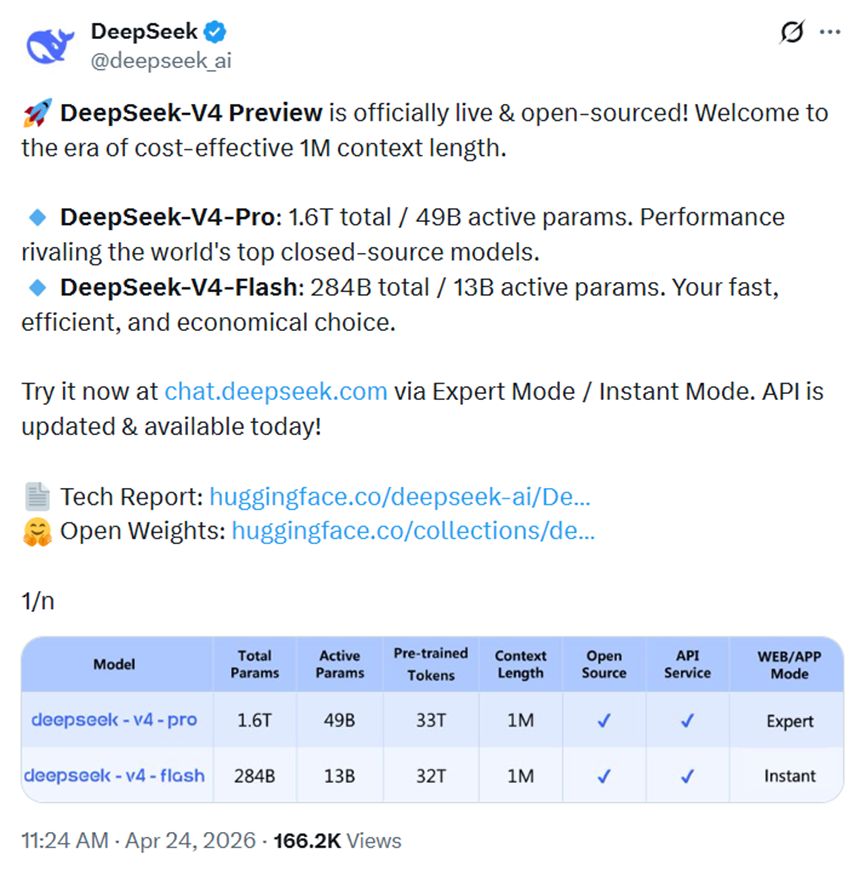
开源地址:https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro
https://huggingface.co/deepseek-ai/DeepSeek-V4-Flash
超强测试数据
DeepSeek官方放出了和Claude-Opus-4.6-Max、GPT-5.4-xHigh、Gemini-3.1-Pro-High三款全球顶级模型的横向评测数据,多个关键维度成绩大幅领先Opus-4.6与GPT-5.4。
通用常识问答基准上,V4拿到57.9%的成绩,大幅领先Claude的46.2%和GPT的45.3%,仅略低于Gemini的75.6%,在基础事实问答能力上,已经和两大闭源对手拉开了明显差距。
专业知识基准测试中,V4成绩达到37.7%,和Claude的40%、GPT的39.8%差距微乎其微,基本站在了同一水平线,专业冷门知识的记忆调取能力,完全对标国际旗舰水准。
来到全场最硬核的高阶数学推理测试,V4直接拿下全场最高分90.2%。对比来看,Claude为85.9%,GPT仅78.1%,就连Gemini也只有89.1%。
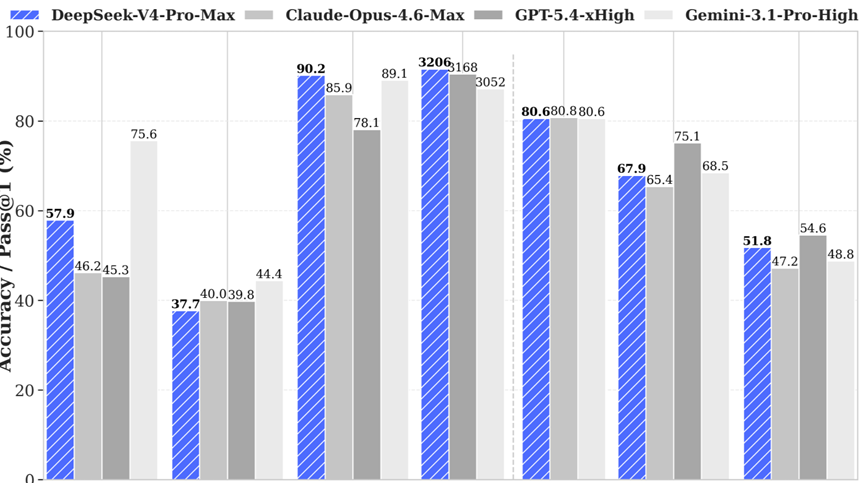
也就是说,在奥数级、竞赛级的高难度深度逻辑推理上,V4已经稳稳反超Opus和GPT,推理深度和解题正确率实现全面领跑。
综合复杂任务基准里,V4交出67.9%的亮眼答卷,领先Claude的65.4%,虽然暂时不及GPT的75.1%和Gemini的68.5%,但差距已经压缩到极小,实战表现相当亮眼。
最后在下一代AI核心的工具调用与智能体综合能力测试中,V4以51.8%的成绩位列四模型第一,领先Claude的47.2%和Gemini的48.8%,仅小幅落后GPT的54.6%。
在多工具联动、自主规划执行这类决定AI上限的能力上,开源出身的DeepSeek,已经实打实完成了对两大国际闭源巨头的超越。
原生支持100万上下文
这次推出的DeepSeek-V4一共两款型号,分别面向极致性能和高效普惠,并且都原生支持一百万token的超长上下文。
旗舰版本DeepSeek-V4-Pro总参数规模达到1.6万亿,实际每步激活参数490亿,直接对标ClaudeOpus-4.6、GPT-5.4、Gemini-3.1-Pro这类顶级闭源模型。
专门处理复杂推理、长文档精读、大规模代码工程和专业智能体任务。
另一款轻量化版本DeepSeek-V4-Flash总参数284亿,激活参数仅13亿,在推理能力接近旗舰的前提下。
把速度和成本做到极致,日常办公、通用文本处理、轻量智能调用都能轻松胜任。
两款模型的训练基础都非常扎实,分别使用33万亿和32万亿高质量token完成预训练,内容覆盖通用文本、科研资料、代码、长文档和多语言知识,让模型在各类场景下都有稳定的输出能力。
真正让人惊喜的是效率提升,在一百万token的超长上下文场景下,对比上一代的DeepSeek-V3.2,Pro版本的单token推理算力消耗仅为原来的27%,缓存占用更是降到十分之一。
轻量化版本表现更夸张,算力消耗仅为原先的10%,缓存占用只有7%。
这意味着百万上下文不再是只能展示的技术概念,而是企业和开发者都能稳定部署、低成本使用的实用能力,大模型终于从短对话走向完整的长流程任务处理。
V4架构三大创新
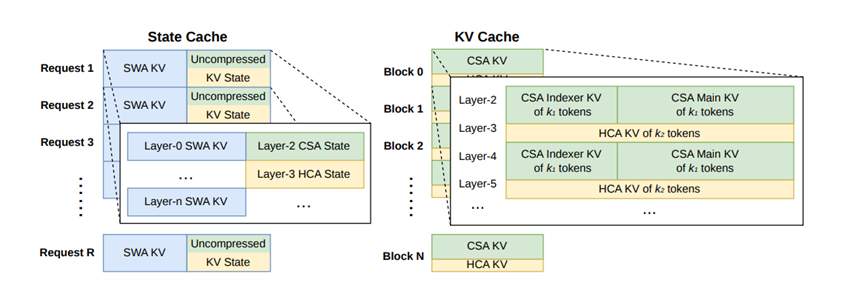
能实现这样的突破,核心来自三处架构创新。首先是全新的混合注意力机制,传统大模型处理超长文本时,计算量会急剧增长,而V4系列将压缩稀疏注意力和重度压缩注意力交替使用。
登录/注册后继续阅读
立即登录/注册 >






























