
我要认证
2026-04-17
继之前Qwen3.6-Plus发布之后,阿里通义千问团队又放大招,刚把Qwen3.6-35B-A3B全量开源了,直接把开源小模型的天花板抬到了新高度。
谷歌最新开源的Gemma 4-31B在它面前,几乎全面被碾压。

开源地址:https://modelscope.cn/models/Qwen/Qwen3.6-35B-A3B
https://huggingface.co/Qwen/Qwen3.6-35B-A3B
Qwen3.6-35B-A3B是典型的混合专家模型,总参数看着有350亿,但实际运行的时候只需要激活30亿参数,相当于用轻量级的算力消耗,跑出了大模型级别的性能。
这一点真的太关键了,不管是个人开发者本地部署,还是企业做落地应用,算力成本都能省一大笔。同时支持多模态思考和非思考两种模式。
全面碾压谷歌Gemma 4
我特意把两款模型的核心测试数据做了对比,从编程到通用推理,再到多模态。
Qwen3.6-35B-A3B猛超谷歌刚发布的Gemma 4-31B,各项核心任务的领先幅度都不小,是实打实的碾压。
先看最核心的智能体编程能力,这也是开发者最关心的点,几款主流的测试基准里,Qwen3.6-35B-A3B的表现都甩开Gemma 4-31B一大截。
SWE-benchVerified测试里直接拿到73.4的分数,比Gemma 4-31B的52.0高出21.4,这几乎是断层领先了。
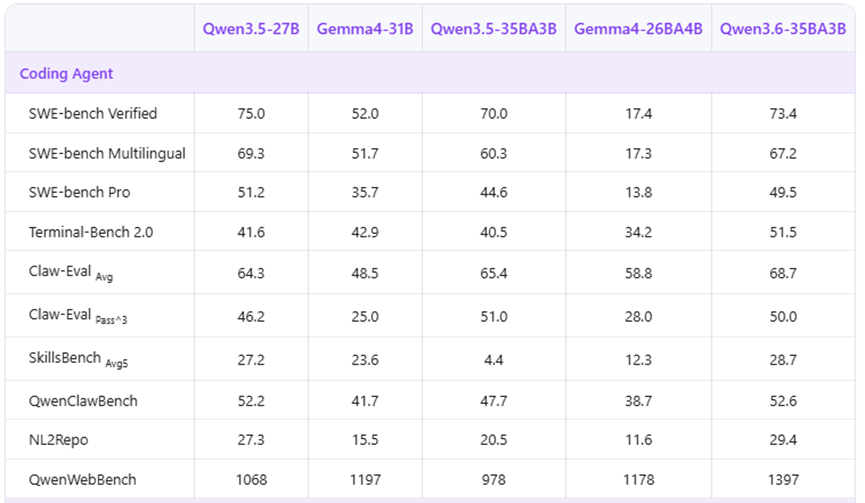
就算是多语言编程测试,也比谷歌的模型高出15.5,专业的工程化测试SWE-benchPro里,领先幅度也有13.8。
还有终端操作、通用代码评估这些测试,每一项都比Gemma 4-31B强,平均下来领先幅度都在20左右。
简单来说就是用这款模型做AI编程助手,写代码、查bug、做工程开发,效率会比用Gemma 4-31B高太多。
再看通用智能体能力,也就是模型的工具调用、复杂任务规划、多模态交互这些能力,两款模型的差距同样很明显。
虽然在TAU3-Bench测试里分数差不多,几乎持平,但在深度规划测试里,Qwen3.6-35B-A3B的表现就更优了,尤其是MCPMark这个核心测试,直接拿到37.0的分数,而Gemma 4-31B只有18.1,相当于直接翻倍。
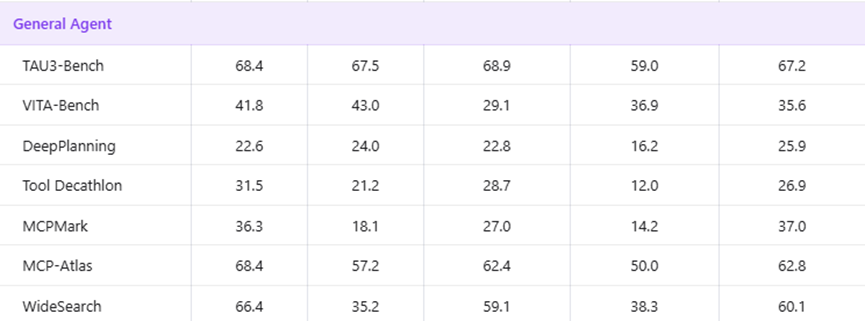
多模态交互的核心测试里,也比谷歌的模型高出5个多点,能看出来这款模型在处理复杂任务、对接各类工具的时候,灵活性和准确性都要更强。
知识储备和通用推理方面,两款模型的基础知识储备差不多,在MMLU-Pro这类通用知识测试里分数完全持平,MMLU-Redux里也只是微差,几乎可以忽略不计。
但重点在中文理解和STEM推理上,Qwen3.6-35B-A3B的优势就体现出来了。
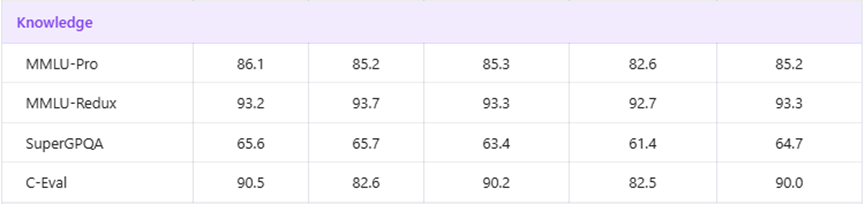
C-Eval作为中文理解的核心测试,直接拿到90.0的高分,而Gemma 4-31B只有82.6,高出7,STEM推理测试里也领先1.7。
这对于国内开发者来说,中文理解能力强这一点,用起来的体验会好太多,不用再纠结模型对中文指令的理解偏差。
最后是多模态能力,这也是Qwen3.6-35B-A3B的强项,视觉、文档、视频理解全方面领先,部分任务的领先幅度还超过了10。
视觉问答的真实场景测试里,拿到85.3的分数,比Gemma 4-31B高出13,文档理解的核心测试里,更是从80.1直接干到89.9,接近90的高分,视频理解测试里也保持着领先。
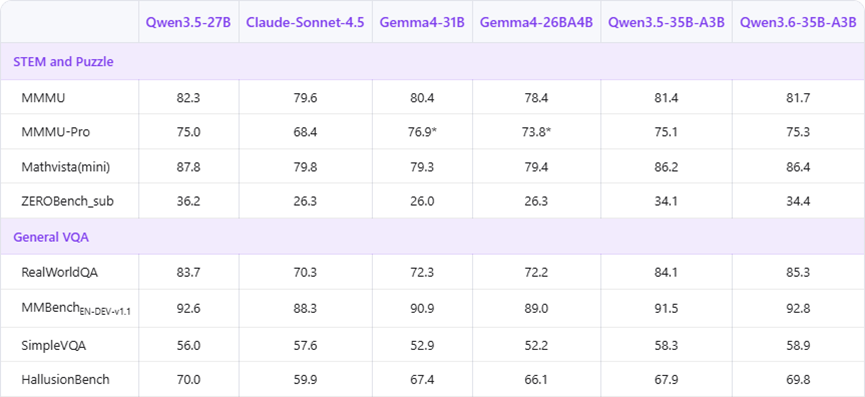
更关键的是,谷歌Gemma 4-31B在空间智能相关的测试里几乎是空白,而Qwen3.6-35B-A3B在这方面有明确的高分表现,不管是图片里的目标定位,还是多语言的空间理解,都能轻松应对,多模态的全面性直接拉满。
为啥能轻松战胜谷歌Gemma 4
很多人可能会好奇,为啥Qwen3.6-35B-A3B只用30亿激活参数,就能干翻谷歌31B的Gemma 4,其实核心就在四个技术优化上,每一个都踩在了模型优化的关键点上。
首先是稀疏MoE架构的革新,这是最核心的一点。传统的稠密模型运行时要调动全部参数,算力消耗大,而这款模型用的稀疏架构,总参数350亿但只激活30亿。
登录/注册后继续阅读
立即登录/注册 >






























