
我要认证
2026-04-14
从单张RGB图片里做3D目标检测,一直是又难又刚需的视觉大难题。不管是自动驾驶、机器人抓取,还是AR/VR交互,都离不开精准的3D空间感知。
但传统模型要么只能识别固定几类物体,要么只支持一种交互方式,遇到真实场景就容易拉胯。
最近AI2和华盛顿大学联合开源的WildDet3D,直接把开放词汇单目3D检测推到了新高度,同时把目前最大的3D检测数据集之一也开源了。
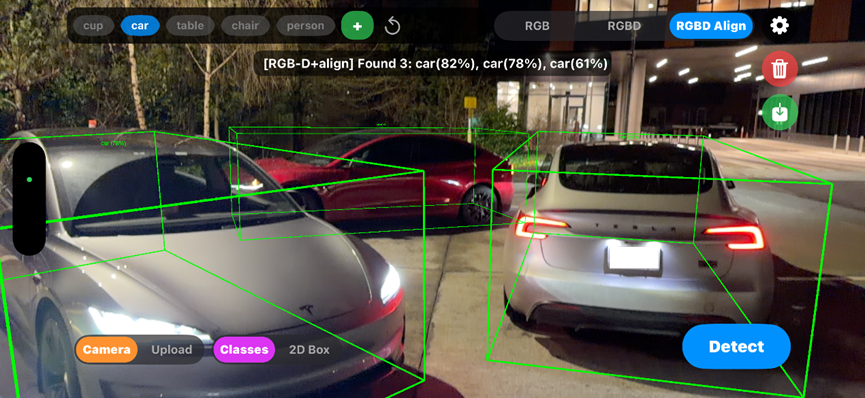
WildDet3D不仅能用文字、点选、方框三种方式触发检测,还能灵活用上深度信息,再搭配史上最大规模的野外3D检测数据集,不管是常见物品还是小众类别,可以稳稳输出精准3D包围盒。

开源地址:https://github.com/allenai/WildDet3D
数据集:https://huggingface.co/datasets/allenai/WildDet3D-Data
在说WildDet3D技术之前,咱们先捋清楚单目3D检测的老难题。
以往的模型大多有三个硬伤:第一,只能识别训练过的固定类别,遇到野外场景里的小众物体直接失效;
第二,交互方式太单一,要么只认文字指令,要么只能框选,没法适配机器人、AR眼镜等不同设备的操作习惯;第三,没有深度信息就寸步难行,就算有额外几何信号也没法灵活利用。
而WildDet3D的出现,就是冲着这三个问题来的。它打造了一个统一的几何感知框架,同时搞定开放词汇、多模态提示、深度信号融合三件事,再配上百万级标注数据,让3D检测真正能走出实验室,落地到真实生活里。
WildDet3D的厉害之处在于其架构设计很巧妙,没有堆砌复杂模块,而是用三个核心部分,把视觉特征、几何信息、提示交互完美捏合在一起。
双视觉编码器
第一个是图像编码器,基于SAM3的ViT大模型,专门提取图片里的物体语义特征,比如分辨出这是杯子、那是斑马,精准定位物体在图片里的位置。
训练时只微调最后四层,保留预训练的强大识别能力,又能适配3D检测任务。
第二个是RGBD编码器,基于DINOv2模型,专门处理深度信息。它可以接收带深度的4通道输入,没有深度时就用零填充,自己从RGB图里推算深度特征。
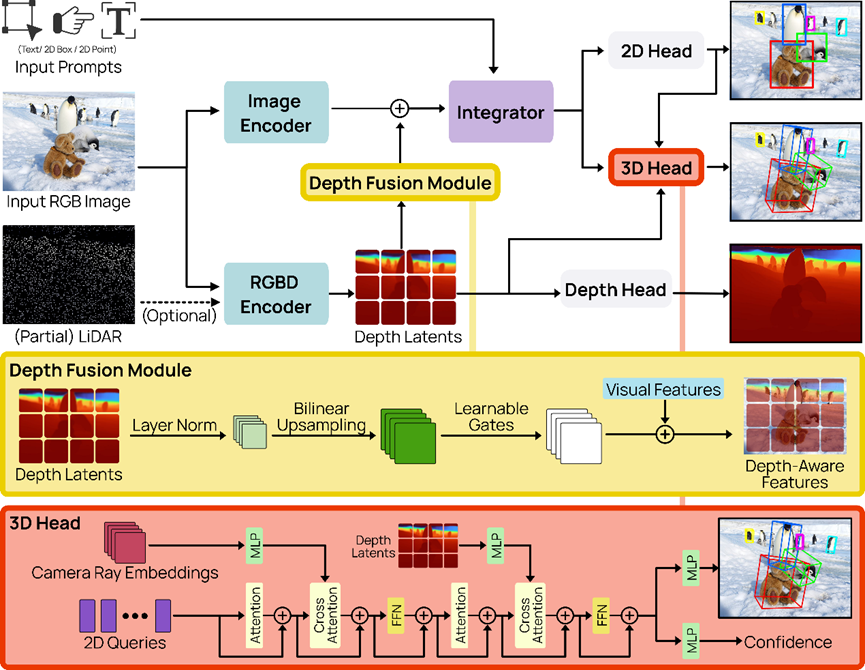
这个编码器负责搞定空间几何信息,比如物体离镜头多远、实际尺寸多大,解决单目检测最头疼的尺度模糊问题。
最后通过深度融合模块,把几何特征注入视觉特征里,就像给识别结果加上精准的空间坐标,既不破坏原有的语义识别能力,又能获得可靠的3D几何信息,两全其美。
可提示检测器,文字点选方框都能认
这是WildDet3D最接地气的设计,也是它能落地到手机、AR眼镜的关键。以往的3D检测器要么只支持文字搜索,要么只能用预设方框,而这个模型一次性兼容四种提示方式,日常使用超顺手。
文字提示就是直接输入类别名称,比如输入汽车,模型就会找出图片里所有汽车的3D框;点选提示就是用手指点一下物体,模型就能定位这个目标的3D信息;
方框提示就是用2D方框框住物体,直接lifting成3D框;还有示例提示,框一个物体就能找出所有相似物品。

训练时模型会同时采样多种提示方式,保证每种交互都学得均匀。而且它采用按提示批次训练的方式,不是按图片训练,能轻松处理上千个类别。
不会出现类别太多导致的性能下降,这也是它能支持13.5K类别的核心原因。
深度监督3D检测头
最后一步就是把前面的特征,转化成精准的3D包围盒。这个检测头用了多层Transformer解码器,每一层都输出3D预测结果,全程深度监督,让模型从浅层就学会3D定位,收敛速度比传统模型快好几倍。
它会同时融合相机射线特征和深度特征,先确定物体在空间中的射线方向,再结合深度信息算出精准坐标。
针对3D框最容易出错的旋转问题,模型还做了无歧义旋转归一化,自动统一尺寸顺序和旋转角度,避免同一个物体出现多种等效3D框,训练更稳定,预测更准确。
除此之外,模型还加了3D置信度分支,专门评估3D检测的质量,结合2D置信度重新排序,就算2D检测结果差不多,也能选出3D位置更准的结果,进一步提升精度。
史上最大3D检测数据集
登录/注册后继续阅读
立即登录/注册 >






























