
我要认证
2026-04-13
最近腾讯混元视觉团队联合RoboticsX实验室,开源了一个专门给现实世界具身智能体用的王炸模型HY-Embodied-0.5。
这个模型在22项国际权威测试里拿下16项第一,大参数32B版本媲美谷歌的Gemini 3.0 Pro模型。具身智能的“iPhone时刻”,这次可能真的要被腾讯给催熟了。
开源地址:https://huggingface.co/tencent/HY-Embodied-0.5
可能很多人对具身智能这个词有点陌生,简单说就是让AI不只是停留在屏幕里聊天、做题、生成内容,而是能看懂真实环境、会思考操作步骤,还能指挥机器臂完成精准动作。
过去这一步一直很难迈过去,主流的视觉语言模型要么看不清物理空间里的深度、位置和细节,或者只会处理静态图片,完全不懂怎么规划动作、怎么和现实物体交互。
而HY-Embodied-0.5要解决的,就是这个横在数字智能和物理世界之间的最大鸿沟。
两个版本,落地场景广泛
腾讯这次没有只做一款大而全的模型,而是直接推出两个版本,覆盖了从终端部署到云端推理的全部场景,这种设计非常贴合实际使用需求。
其中小型号是HY-Embodied-0.5-MoT-2B,激活参数20亿,总参数40亿,主打一个轻巧高效,专门用在边缘设备上,保证实时响应的同时还能保持强悍性能。
大型号则是HY-Embodied-0.5-MoE-A32B,激活参数320亿,总参数高达4070亿,专攻复杂场景下的视觉感知和深度推理,能力直接拉满。
两款模型从架构、数据到训练方式都做了全套优化,不是简单的参数缩放,而是每一处设计都围绕物理世界的感知和操作展开,最终实现了小模型好用、大模型超强的效果。
架构三大升级
想要让AI适配现实世界,模型架构必须重新打磨。HY-Embodied-0.5在经典视觉语言模型的基础上,做了三项关键改进,每一项都精准解决了实际问题。
首先是升级了HY-ViT2.0视觉编码器。传统的视觉模型需要把图片裁剪成固定尺寸,很容易丢掉关键的空间信息,而且大模型很难在终端跑起来。
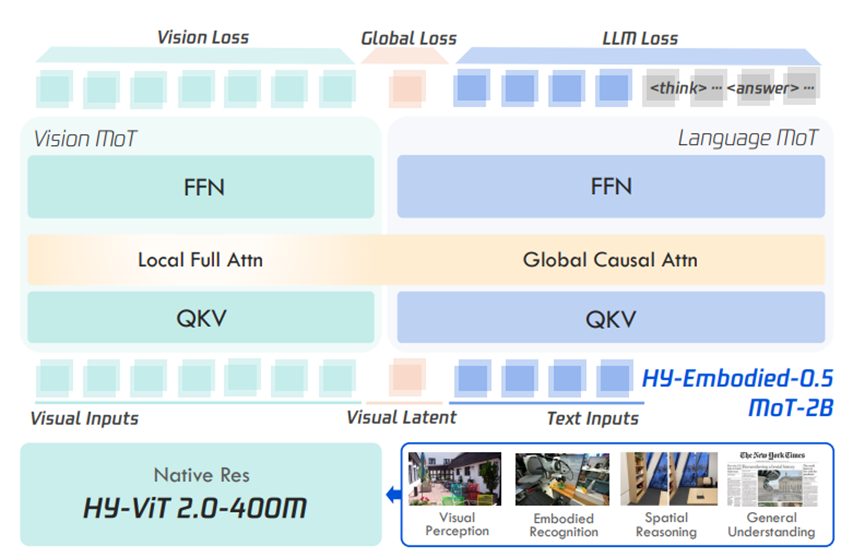
新版编码器原生支持任意分辨率输入,不用裁剪缩放就能完整保留画面信息,参数只有4亿,经过大模型蒸馏之后,轻巧又精准,还能同时完成理解和重建,保证送给语言模型的视觉信息没有损耗。
其次是用上了混合Transformer架构,也就是MoT。过去多模态训练经常出现一个问题,视觉任务练多了,语言能力就会下降,小模型尤其明显。
MoT架构把视觉和语言的计算路径分开,视觉信息用独立参数处理,文本信息保留原有参数,再给视觉部分配上专属的双向注意力和监督任务,既强化了视觉能力,又不会拖累语言表现。
实际测试下来,这种架构收敛更快,损失更低,推理的时候几乎不增加额外开销,非常适合小模型使用。
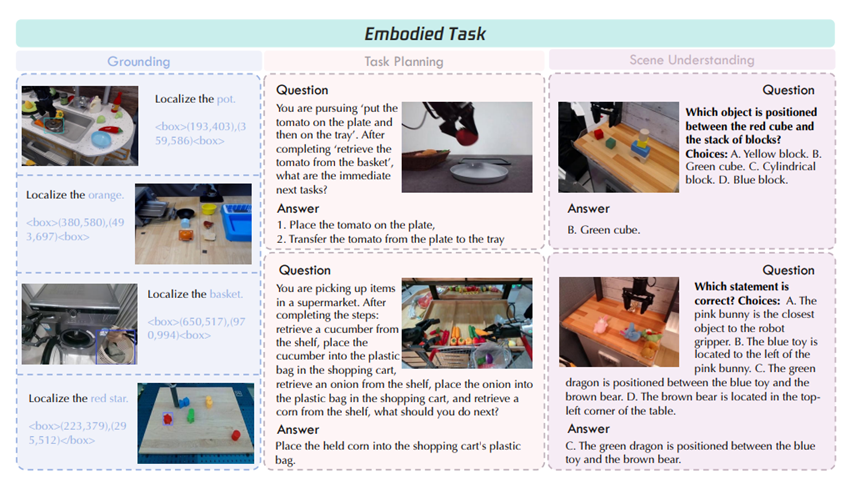
最后是加入了视觉潜在token,相当于给视觉和语言之间搭了一座专用桥梁。它能把画面里的关键物体、空间位置,和语言里的操作指令、语义信息精准对应起来。
从注意力可视化的结果能看到,模型能精准定位到薯片罐端口、抽屉把手这类细小部位,同时关联上关闭、抓取这类动作指令,跨模态理解的能力直接上了一个台阶。
登录/注册后继续阅读
立即登录/注册 >






























