
我要认证
2026-04-10
大家都知道RAG这个东西,就是先从知识库里检索相关内容,再喂给大模型生成回答。思路很简单对吧。
但问题是,目前市面上绝大多数RAG框架都只认文字。你丢一张图进去,它就愣住了。
如果你有大量的图片资料、PDF文档,甚至视频素材想要让AI去理解和检索就很费劲。
所以,阿里巴巴的通义实验室刚开源了一下带的RAG多模态框架VRAG。使得AI模型不仅能读文字,还能看图片、看视频,自己去找需要的信息,然后像人一样进行多步推理,最后给出一个靠谱的答案。

开源地址:https://github.com/Alibaba-NLP/VRAG
https://huggingface.co/Qiuchen-Wang/Qwen2.5-VL-7B-VRAG
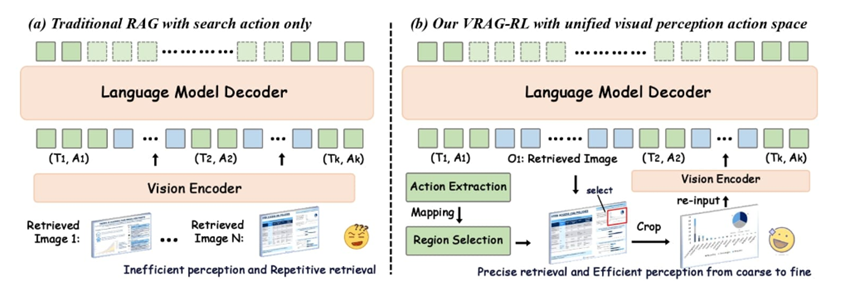
咱们详细唠唠VRAG的核心能力,第一个也是我觉得最有意思的能力,就是它的多模态检索。
传统的RAG只会从文本语料库里搜东西,而VRAG支持图片、PDF文档和视频三种格式的语料输入。你有一堆产品截图扔进去,它能直接理解图片内容并建立索引。
PDF的话它会自动转成图片再处理。视频也很贴心,可以按时长自动切片,比如每60秒切一段。
这意味着你可以把一个包含丰富图表的PDF报告,或者一段产品演示视频,直接喂给这个系统,让它帮你做内容检索和问答。不用自己手动整理文字摘要,省了大量前期工作。
然后顺着这个能力往下延伸,就是它的第二个杀手锏多步推理。这个是整个框架比较硬核的部分了。
VRAG不是那种一次性检索完就完事的系统,它支持多轮交互式的推理过程。
简单来说就是AI可以像人翻书查资料一样,先看个大概,发现信息不够,再去细查某个部分,一步步缩小范围,最终找到准确答案。
这个框架把这个过程建模成了一个有向无环图,听起来很高深,其实你可以理解成一张思维导图,每个节点代表一步推理操作,节点之间有清晰的逻辑关系。
好处是什么呢,就是推理过程是可追溯的,你不仅知道最终答案,还能看到AI是怎么一步步想出来的。对于需要可解释性的场景来说,这个特性非常实用。
有了推理过程还得能看得见才行,所以第三个能力就是实时可视化。VimRAG那个版本带了一个Streamlit的交互界面,推理过程中的每一步都会以图的形式实时展示出来。

你可以看到AI在哪个节点做了什么决策,检索了哪些内容,怎么关联起来的。
这个功能看起来可能只是花哨的演示,但实际调试和优化的时候特别有用。你一眼就能看出AI是在哪一步走了弯路,然后针对性地调整你的语料或者参数。
登录/注册后继续阅读
立即登录/注册 >






























