
我要认证
2026-04-08
想从一份PDF里精准提取内容,结果一解析出来全是乱套的。表格碎了,阅读顺序是乱的,多栏排版直接给你拼成一坨,图片更是完全丢了。
更烦的是那种扫描件PDF,明明看着全是字,你复制出来却是一堆乱码,还得自己再跑一遍OCR。搞RAG的朋友应该深有体会,数据清洗这一步有时候比调模型还费劲。
今天介绍一个曾拿下Github每日最佳的开源OpenDataLoader PDF,专门为AI数据提取打造的PDF解析器。

开源地址:https://github.com/opendataloader-project/opendataloader-pdf
你可以把它理解成一台超级精准的PDF拆解机,不管你的PDF多复杂,它都能把里面的文字、表格、图片、公式、标题层级一层一层剥出来,整理得干干净净,直接喂给大模型用。
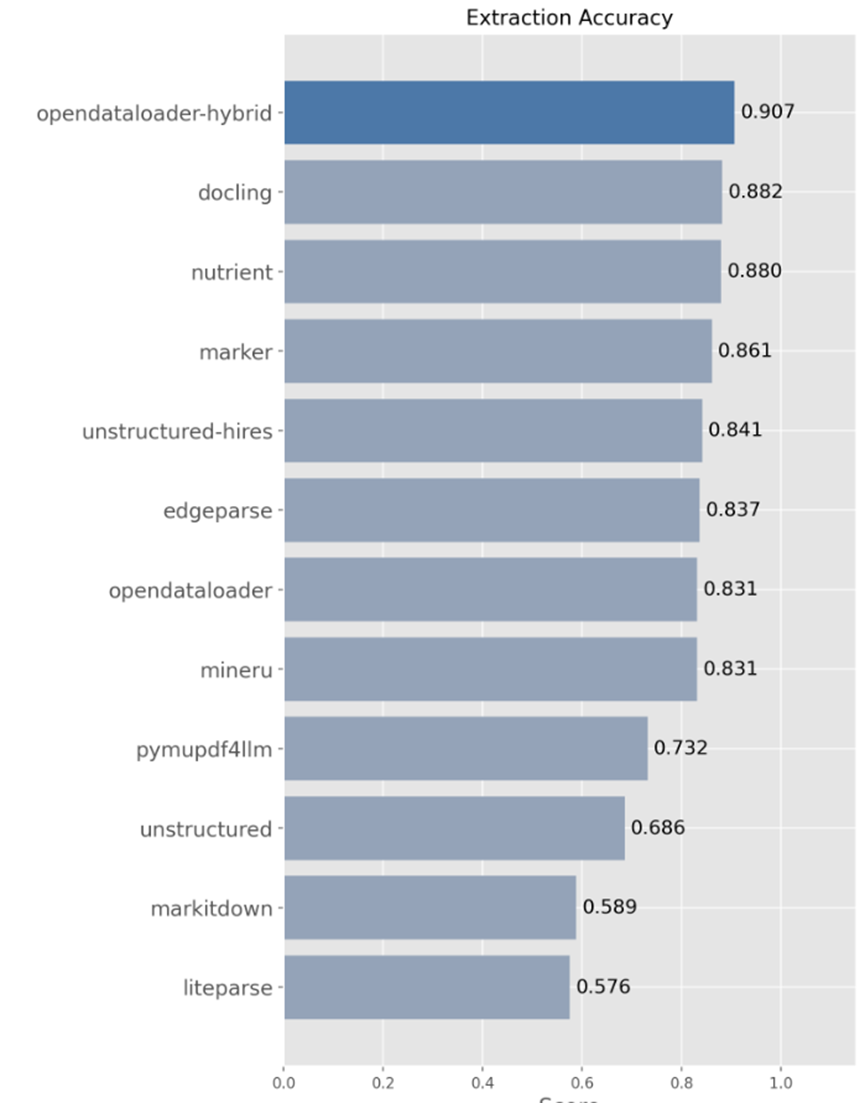
在目前公开的PDF解析基准测试里,OpenDataLoader PDF的综合准确率拿到了第一名,总分0.907,这个成绩甩了第二名不少。
目前,很多PDF解析器最大的问题就是不知道先读哪后读哪,尤其是多栏排版的学术论文或者杂志页面,经常把左栏和右栏的内容混在一起,读起来前言不搭后语。
我之前处理过一份双栏排版的行业报告,用某款付费工具解析完,第一段还没讲完突然跳到第三段去了,后面又绕回来,整段逻辑完全支离破碎。
OpenDataLoader用了一种叫XY-Cut++的算法来处理这个问题,简单来说就是模拟人类看页面的方式,先确定大的区域划分,再逐步细化到每个段落和句子。
用起来最直观的感受就是,解析出来的Markdown读起来是通顺的,不会出现上一句还是第一段的内容下一句突然跳到第三段的情况。
你在处理学术论文、技术白皮书这类双栏排版的PDF时,这个能力的价值会体现得非常明显。

表格提取这块OpenDataLoader PDF是真的强,这个要重点说一下,因为表格真的是PDF解析里的老大难问题。
有边框的表格还好说,最怕那种无边框的,纯靠空格和对齐来区分行列的表格,很多工具直接就放弃了,提取出来就是一坨挤在一起的文字。
做数据分析的人应该懂那种绝望,你明明知道PDF里有张关键的数据表,却怎么都拿不出来。
OpenDataLoader在混合模式下可以处理各种复杂表格,包括合并单元格、嵌套表格这些。
而且提取出来不是一坨纯文本,是带着行列结构的JSON数据,每个单元格的坐标都有,这意味着你可以精确定位到PDF里的任意一个格子。
做文档问答或者数据分析的时候,这个能力特别关键,因为大模型拿到结构化表格之后理解能力会大幅提升。
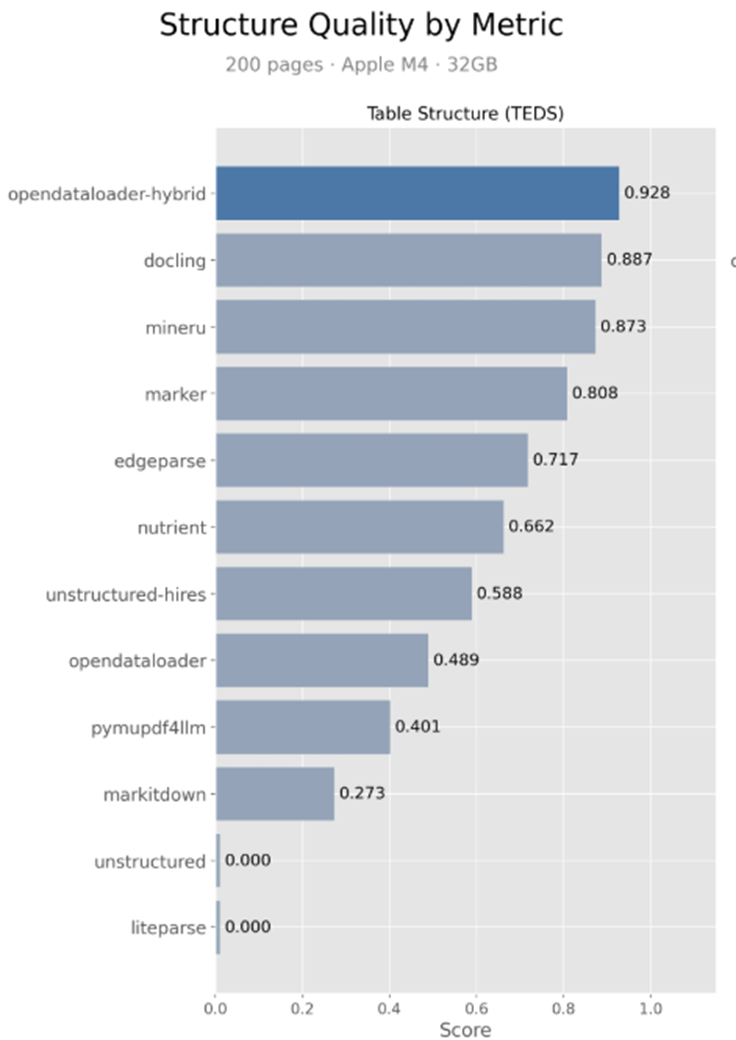
从基准测试数据来看,它表格提取的准确率做到了0.928,这个数字在目前的PDF解析工具里基本没有对手。
登录/注册后继续阅读
立即登录/注册 >






























