
我要认证
2026-04-03
阿里刚发布了Qwen3.6-Plus,带着100万上下文窗口重磅登场,直接把AI智能体卷到了全新高度。
算是把之前3.5版本的短板全补上了,尤其是智能体编码这块,从简单的前端开发到复杂的代码库问题都能搞定。
多模态的感知和推理也更精准了,看图片、分析视频再结合语言做判断,比之前靠谱多了。
从今天开始已经可以在阿里的Qwen聊天助手中体验了,同样也开放了API。
API:https://modelstudio.console.alibabacloud.com/ap-southeast-1?tab=doc#/doc/?type=model&url=2840914_2&modelId=qwen3.6-plus
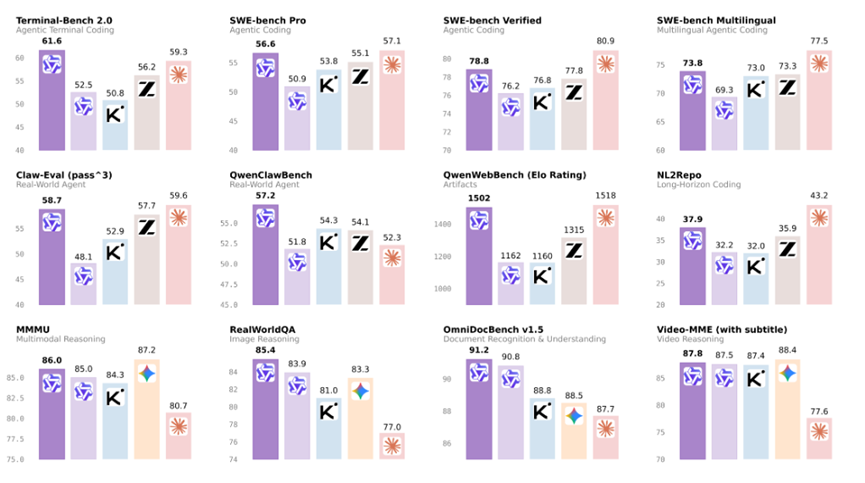
Qwen3.6-Plus的核心亮点主要有三大块:一是默认支持100万上下文窗口,无需额外设置,这是其最突出的优势,为AI智能体能力升级奠定基础。
二是智能体编码能力大幅提升,可轻松应对从前端开发到复杂代码库问题的各类需求。
三是多模态感知与推理更精准,能高效融合图片、视频与语言信息,完成深度分析与判断。
视觉推理这块,在原来感知能力的基础上,又提升了对各类视觉输入的理解、分析和推理能力,不再是简单的识别图片里有什么、视频里讲什么,而是能结合推理、定位、OCR这些能力做深度分析。
比如看一份复杂的文档、解析一张专业的图表、理解一个软件的UI、精准定位图片里的细节,这些实用的任务都能搞定,能真正帮上忙。
这都离不开100万上下文的支撑,也让这款AI智能体的综合能力更上一层楼。
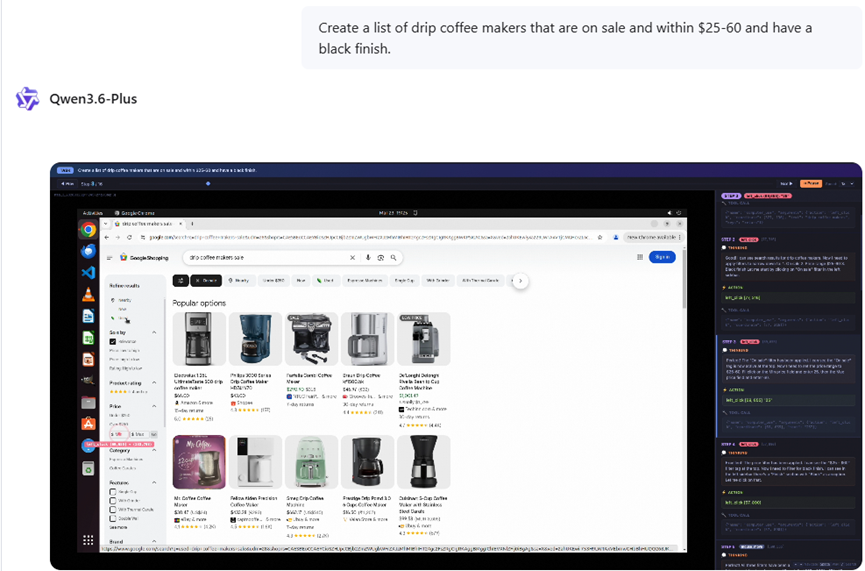
视觉编码的能力也做了增强,把视觉理解、内容生成和工具使用揉到了一起。现在只要给它UI截图、产品原型、设计稿,或者用自然的语言加视觉的方式发指令,它就能生成前端页面、完整的代码,还能优化交互效果。
从理解界面到生成代码,再到用工具修改代码的闭环就打通了,多模态模型不再是只能看不能做的花瓶,在真实的开发流程里,能真正发挥价值。
视频理解方面也在持续升级,越来越贴近真实的任务场景。相比静态的图片,视频理解的难度要大很多,需要模型处理时序信息、捕捉动态的变化。
还要分析跨帧之间的关系,这对模型的感知、理解和处理能力都是很大的考验。
Qwen3.6-Plus在这方面的进步,能让它在视频分析、视频处理这些实际场景里,发挥更大的作用。
视觉智能体的实际应用,核心就是让模型在具体的环境里,一直感知、推理、再执行动作。
比如在GUI智能体的场景里,模型能看懂屏幕当前的状态,再结合自己的规划能力,判断下一步该做什么、该怎么操作。
像OpenClaw这些探索,也能看出来多模态模型在开放的环境里,完成复杂交互任务的潜力有多大。
登录/注册后继续阅读
立即登录/注册 >































