
我要认证
2026-04-02
做AI智能体开发的朋友肯定都踩过这个坑,想让Agent多会点本事,就一个劲往系统提示词里塞规则、贴指南、加API说明。
最后提示词臃肿到不行,每次调用大模型都耗一堆tokens,关键大部分内容用户根本用不上,纯纯资源浪费。
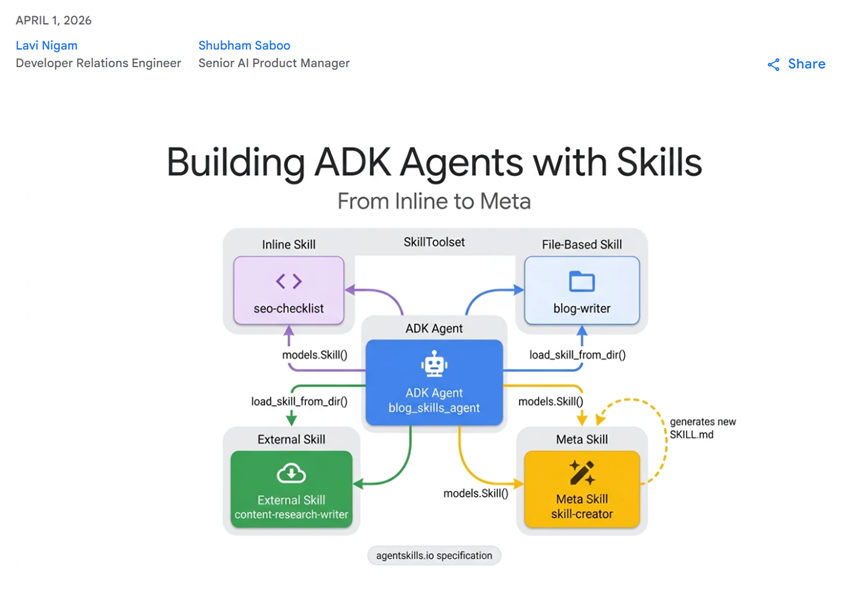
而谷歌最新推出的ADK也就是Agent开发工具包的Skill Toolset核心组件,直接把这个痛点给解决了,并且token成本直接暴降90%。
原文:https://developers.googleblog.com/developers-guide-to-building-adk-agents-with-skills/
谷歌ADK能实现这个突破,核心靠的是渐进式信息披露的架构思路,就是不让Agent把所有知识死记硬背,而是给它弄个“Skills菜单”,需要哪个技能再去翻详细说明。
甚至查配套资料,不用再把几千个tokens的内容全堆在一个提示词里,既省了token资源,Agent的反应速度也快了不少。
ADK把知识加载分成了三个层级,就像我们平时看书,先看目录找方向,再翻章节看细节,最后查参考文献补内容,一步一步来,不浪费一点token和精力。
第一层是L1元数据,每个技能只占大概100个tokens,就包含技能名字和简单描述,Agent启动的时候全加载好,相当于一个技能菜单。
Agent接到任务先看菜单,找对应的技能就行,不用再翻所有内容,这点token成本几乎可以忽略。
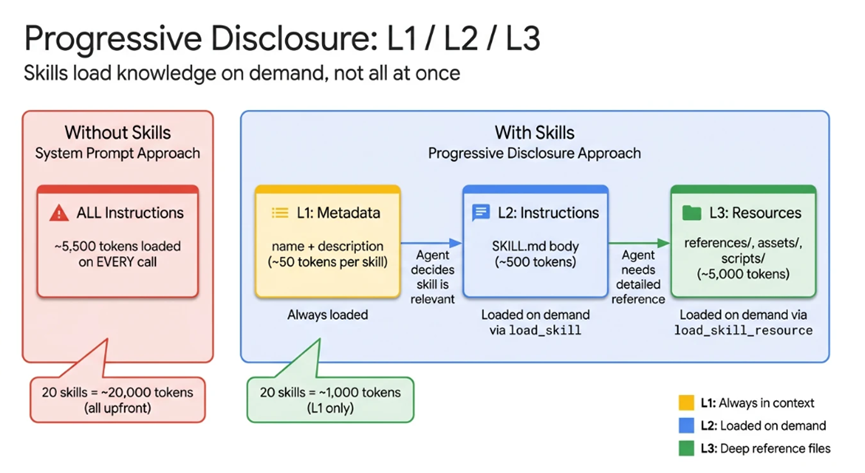
第二层是L2指令,每个技能最多5000个tokens,是这个技能的完整操作步骤,只有Agent确定要用到这个技能了,才会通过API加载,不用的时候根本不占任何token资源。
第三层是L3资源,就是样式指南、API规范这类外部参考文件,只有技能的具体步骤里明确需要这些资料了,才会按需加载,真正做到精准调用,不做无用功,不花冤枉token。
这么算下来就很直观了,一个有10个技能的Agent,以前启动一次要耗10000个tokens,现在只要1000个就够了,直接省了90%的基线上下文token资源。
这效率提升可不是一点半点,token成本也跟着大幅下降,对于高频调用大模型的开发者来说,这波省下来的成本真的太香了。
而ADK里的SkillToolset类就是实现这个架构的核心,它会自动生成三个工具,刚好对应这三个层级:list_skills管L1的技能列表,load_skill加载L2的具体指令,load_skill_resource调取L3的参考资料。
不用我们自己再写额外的代码,特别省心,开发效率直接翻倍,还能精准控费。下面是几个ADK常见的自动创建Skills方法。
嵌入式Skills
这是ADK里最简单的Skill实现方式,就像我们在代码里贴个便签,把技能的名字、描述和具体指令直接写成Python对象,嵌在Agent的代码里就行,不用搞复杂的目录结构,特别适合那些内容固定、几乎不用改的小规则。

比如简单的SEO检查、格式校验、基础数据核对这类场景,新手一分钟就能上手,还不额外耗token。
例如,做一个博客SEO优化的技能,直接定义一个seo_skill对象,写清楚名字是seo-checklist,描述是给博客做SEO检查,涵盖标题、元描述、标题层级这些核心内容。
再把具体的检查步骤一条条写在指令里,比如标题要控制在50-60个字符,核心关键词尽量前置,元描述要加行动号召语句这些细节。
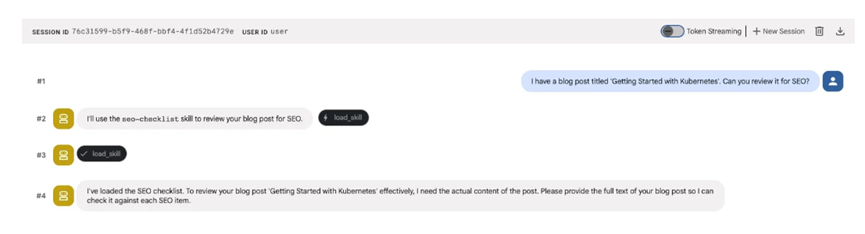
这个对象里的名称和描述会自动变成L1元数据,每次调用大模型都能读到,而具体的检查步骤就是L2指令。
只有用户让Agent审核博客SEO的时候,Agent才会加载这些步骤,按条系统执行检查,简单又实用,不用把所有SEO规则都塞在提示词里浪费token。
这种方式的好处就是上手快,代码写好直接用,不用管其他配置,新手也能轻松掌握。
但缺点也很明显,如果技能需要参考其他资料,或者想在多个Agent里复用,就不太方便了,这时候就可以升级到下一个模式,实用性会更强,也能进一步优化token使用效率。
基于文件的Skills
嵌入式Skills适合简单的小技能,但如果你的技能需要搭配参考文档,比如写博客需要对应的样式指南,调用API需要详细的规范说明,做数据校验需要参考标准表,这时候嵌入式就不够用了。
得用基于文件的Skills,把技能做成一个独立的“参考手册”,弄个专属目录,把指令和参考资料分开放,条理更清晰,复用性也更强,还能避免把参考资料的内容塞到提示词里浪费token。

这个专属目录里,必须有一个SKILL.md文件,这是技能的核心,开头写技能的基本信息,后面用Markdown写具体指令,这就是对应的L2内容。
还可以建一个references子目录,把样式指南、API规范、标准数据表这些参考资料全放进去,这就是L3资源,需要的时候再按需加载,不占额外token资源。
比如做一个博客写作的技能,就建一个blog-writer目录,里面放SKILL.md,把写作的步骤、要求、注意事项全写清楚,references里放style-guide.md样式指南,代码里只需要调用load_skill_from_dir方法,指定这个目录的路径,就能一键加载整个技能,特别方便。
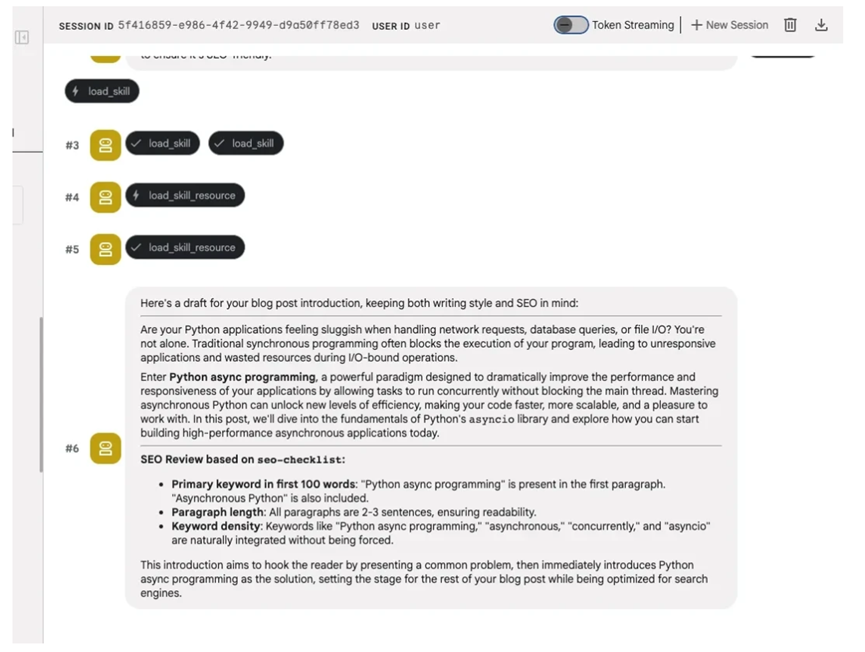
这种方式把技能和参考资料拆分开,让知识变得可复用,只要是遵循agentskills.io规范的Agent,都能加载这个目录。
不用再重复写代码,大大节省开发时间,更重要的是,参考资料不用提前塞到提示词里,只有需要的时候才加载,能有效减少token消耗。
不过美中不足的是,这个SKILL.md文件还是需要我们自己手动写,要是能直接用别人写好的,效率会更高,这就是第三种模式的核心价值。
外部Skills
其实外部Skills和基于文件的Skills原理完全一样,核心区别就在于技能目录的来源不一样,不用我们自己从头写SKILL.md,直接从社区的资源库比如awesome-claude-skills里下载别人写好的技能目录。
然后用和模式二一样的load_skill_from_dir方法加载就行,代码都不用改,真正的抄作业式开发,新手也能快速搭建高能力的Agent,还能省掉自己写技能的时间和试错的token成本。

谷歌自己也会用这个规范发布官方的ADK开发技能,直接用npx命令就能一键安装,特别方便。因为agentskills.io规范定义了统一的目录格式,所以不管是自己写的还是从外部下载的,Agent都能精准识别加载,完全不挑来源,兼容性拉满。
其实这三种模式下来,我们就能轻松把现成的、自己写的、社区分享的技能都用起来,Agent的能力库能快速扩充,开发效率也能大幅提升,还能通过按需加载精准控制token消耗。但说到底这些技能还是人写的。
而谷歌ADK的终极玩法,是让Agent自己写技能,也就是第四种模式,这才是真正的王炸功能,不仅能省开发时间,还能让Agent根据需求灵活造技能,进一步优化token使用。
Skills工厂
这是ADK最有意思、也最核心的一个模式,核心是做一个元Skills,就能自己创造Skills。
给Agent装上这个元Skill,它就有了自扩展能力,不用我们手动写代码,它能自己在运行时生成新的Skill,然后加载使用,真正实现了AI智能体的自我进化,从此再也不用为了新增技能反复修改提示词、浪费token了。

这个元Skill其实也是一个嵌入式Skill,核心关键就在resources字段,我们把agentskills.io的规范文档和一个完整的技能示例,作为L3资源嵌在这个字段里,然后在指令里写清楚,让Agent严格按照这个规范和示例,生成符合要求的SKILL.md文件。
登录/注册后继续阅读
立即登录/注册 >































