
我要认证
2026-03-25
今早6点,Cursor放出了Composer2的技术报告,我第一时间啃完了整份内容,只能说这波真的把智能体化软件工程模型玩明白了。
在SWE-bench Multilingual、Terminal-Bench这些业内公认的主流测试里冲到了第一梯队,并在CursorBench拿下61.3%的准确率性超过了Opus4.6,媲美OpenAI的GPT-5.4。
值得一提的是,Cursor这次在技术报告里终于大大方方的承认基础模型使用的就是Kimi K2.5。
地址:https://cursor.com/resources/Composer2.pdf
其实Composer2的核心训练逻辑就两步,先做持续预训练打基础,再用强化学习磨细节,整个过程都在尽量模拟真实的开发场景,让模型从一开始就适应工程师的实际工作节奏,不会出现训练时表现好、实际用起来拉胯的情况。
做模型首先得选个好底子,Cursor团队对比了GLM5、DeepSeekV3.2、KimiK2.5等多款开源模型。
从编码知识、状态跟踪、代码库困惑度三个核心维度做了全面评估,最后选了KimiK2.5。
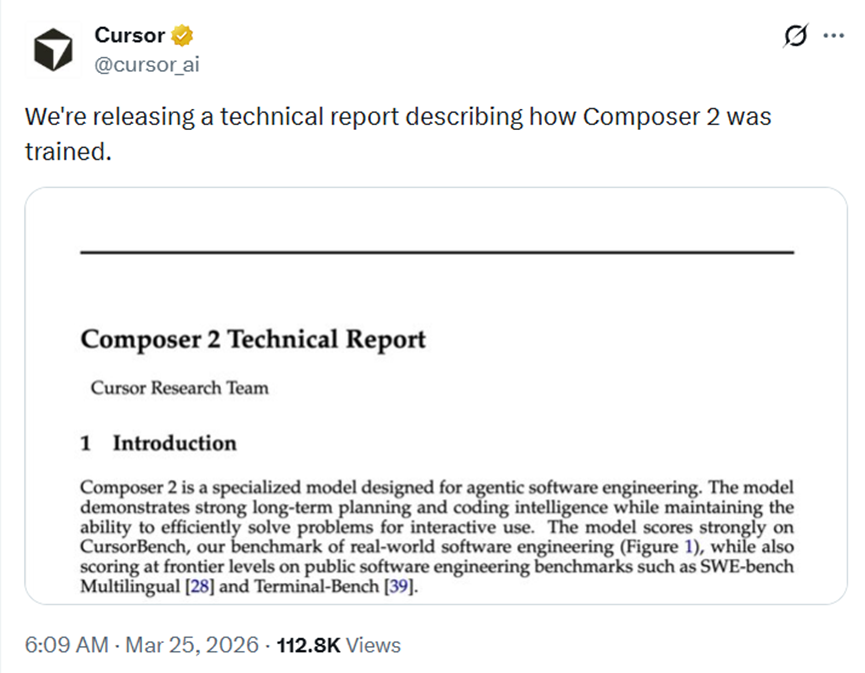
确定了基础模型,接下来的预训练分了三个阶段,全程在NVIDIAB300显卡上用MXFP8精度完成,效率和效果都兼顾到了。
第一阶段主要练32k令牌序列长度的内容,这是投入算力最多的阶段,核心就是让模型沉浸式吸收编码领域的知识,把基础打牢。
第二阶段把序列长度拓展到256k,简单说就是让模型能处理更长的代码和文本,毕竟实际开发中动辄就是几万行的代码文件,长上下文能力太重要了。
最后一个阶段做针对性的有监督微调,让模型的能力更贴合实际的编码任务,比如工程里常见的调试、重构这些场景。整个训练过程中,模型在内部代码库的测试损失一直稳步下降,能明显看到效果在持续提升。
如果说预训练是让模型学会了编码的基本功,那强化学习就是让模型学会在真实场景里解决问题,这一步也是Composer2能适配工程化场景的关键。
团队在高度模拟Cursor实际使用会话的环境里,用大量真实的编码任务训练模型,核心逻辑就是让模型不断尝试解决问题。
再根据解决的好坏调整模型参数,最终让模型的推理能力、多步执行能力都得到提升,面对长周期的编码任务也能保持思路连贯。
训练的任务覆盖了工程开发的方方面面,功能迭代、调试、新功能开发、重构、代码库理解、写文档、做测试。
甚至DevOps和迁移这些场景都包含了,弥补了很多主流测试里缺失的工程化任务。而且训练后期还会刻意增加难任务的占比,让模型不断挑战更高难度,性能也能持续突破。
在强化学习的具体实现上,团队做了不少优化,让模型训练得更稳定、效率更高。
比如用异步训练的方式,训练和任务执行分开进行,互不干扰;对策略梯度算法做了调整,去掉了会导致长度偏差的部分,避免模型出现一些不合理的行为。
在KL散度正则化的估计上,放弃了开源常用的方法,选择了更稳定的估计器,让模型训练过程不会出现大的波动。
最让人惊喜的是,以往很多大模型做强化学习,会只盯着已知的成功方法,牺牲了输出的多样性,导致模型只会解固定的题。
而Composer2的训练既提升了平均表现,也保留了输出的多样性,重复采样时能找到更多正确的解决方案,这在实际开发中太重要了,毕竟解决一个工程问题往往有多种思路。
为了让模型能处理长周期的开发任务,团队还沿用了自总结技术,简单来说就是模型在解决复杂问题时,会不断给自己做总结,把关键信息提炼出来,就算上下文窗口有限,也能处理大量信息。
而且这个总结的好坏会直接影响模型的奖励,做得好就加分,丢了关键信息就减分,训练久了模型就学会了高效的自我总结,比单纯的提示压缩效果好很多,还能节省令牌、复用缓存,效率拉满。
除此之外,团队还特别注重模型的实际使用体验,毕竟是给工程师用的,光聪明还不够,还得好用。
一方面设置了各种辅助奖励,比如代码写得规范、沟通清晰会加分,要是乱建待办事项又不完成、注释里写一堆没用的思考过程就会扣分,训练时还会随时观察模型的行为,发现问题就及时调整奖励规则。
另一方面加了非线性的长度惩罚,让模型学会在简单任务上快速解决,不用浪费时间,遇到复杂任务时又能沉下心多思考,比如学会并行调用多个工具,大幅提升解决问题的效率。
说了这么多技术细节,最终还是要看实测成绩,Composer2的表现可以说是相当亮眼。
在CursorBench-3的测试里,Composer2拿到了61.3%的准确率,相比Composer1.5提升了37%,相比最初的Composer1更是提升了61%,和基础模型KimiK2.5的36%相比,几乎翻了一倍,这充分印证了两步训练法和基建优化的有效性。
登录/注册后继续阅读
立即登录/注册 >































