
我要认证
2026-03-17
法国著名开源平台Mistral AI刚刚开源了最新模型Mistral Small 4-119B-2603。
这个模型最大亮点是把指令对话、深度推理、代码开发三大能力揉在了一起,相当于把三款优质模型的优势整合到一个模型里,用户不用来回切换,一个就能搞定多种任务。
同时支持中文、英文、韩文等10种主流语言,上下文窗口达到了25万,主打能耗低性能强。
开源地址:https://huggingface.co/collections/mistralai/mistral-small-4
这款模型的底子很扎实,底层用的是Mistral 3框架,主打FP8浮点精度,权重存储用的是安全张量格式,稳定性和兼容性都很靠谱。
在本地部署时,咱们最怕大模型跑不动、响应慢,这款模型刚好解决了这个痛点,靠的是精巧的混合专家架构。
Mistral Small 4内置了128个专家网络,每次推理只激活4个,总参数虽然有1190亿,但实际单次调用的激活参数只有65亿,既保住了算力,又不浪费资源。
实际表现也很亮眼,延迟优化模式下,端到端生成速度比上一代快了四成,要是追求吞吐量,每秒处理的请求量更是前代的三倍,对于需要批量处理任务的场景来说,效率直接拉满。

除此之外,它还支持256k的超长上下文,处理长文档、多轮对话都不会断片。
多模态能力也没落下,文本和图像都能识别,输出结果都是文本形式,分析图片内容、提取图文信息都很顺手。
还自带强悍的智能体能力,原生支持函数调用和JSON格式输出,做自动化工具、开发助手都很合适,不管是写代码、改bug,还是梳理代码库,对开发人员来说都很省心。
根据Mistral AI公开测试数据显示,Mistral Small 4在主流测试平台中相当能打。
开启深度推理模式后,它在AA LCR、LiveCodeBench、AIME25这三大核心测试集上,成绩直接持平甚至超越GPT-OSS 120B。
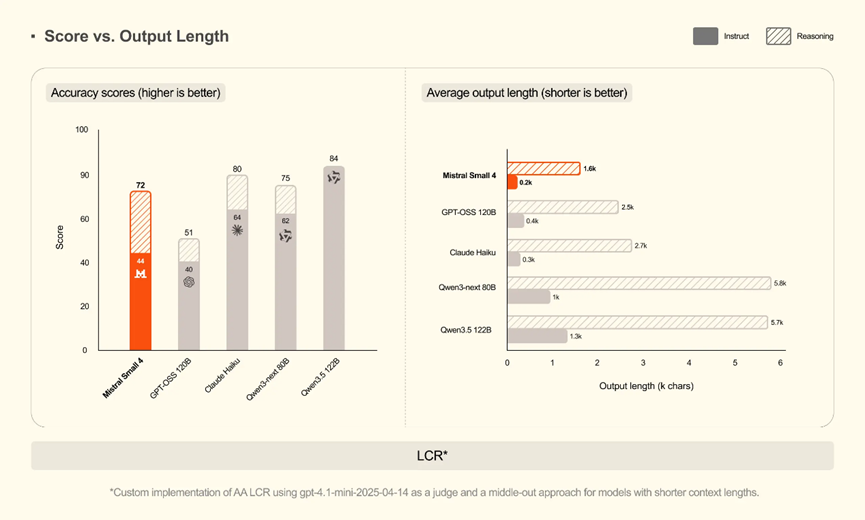
最绝的是它的输出效率,AA LCR测试里仅用1600个字符就斩获0.72的高分,而同类型竞品往往需要生成5800到6100字符,足足是3.5到4倍的长度才能追平分数。
在LiveCodeBench代码测试中,它不仅性能超越GPT-OSS 120B,输出内容长度还减少了20%,短篇幅就能给出精准结果,既降低了推理延迟,又能省下不少算力成本。
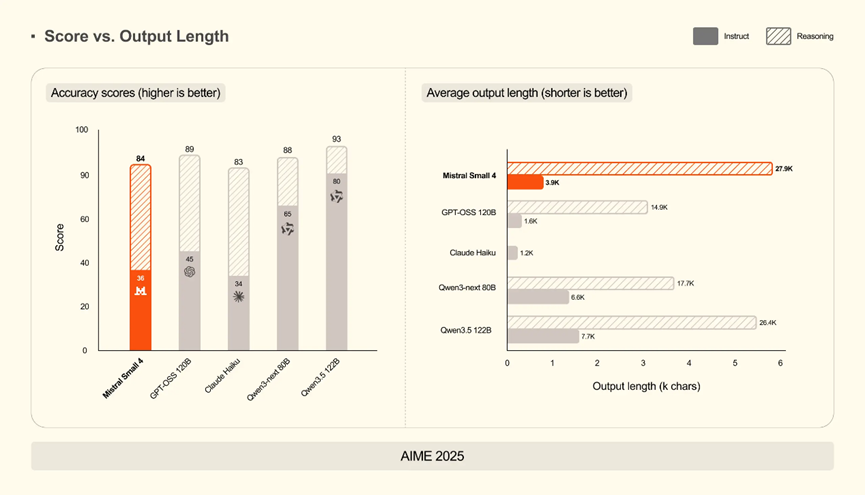
除此之外,核心实测参数也很接地气,256k的超长上下文,处理长文档、多轮对话压根不会丢关键信息,推理采用FP8浮点精度,还支持英伟达NVFP4 4位量化,普通显卡也能低成本部署。
登录/注册后继续阅读
立即登录/注册 >































