
我要认证
2026-03-06
今天凌晨4点,OpenAI、纽约大学、伦敦大学等发布了用于评估AI大模型思维链(Cot)的框架CoTControl。
就连OpenAI今天自己发布的GPT-5.4思考模型,在思维链控制方面也很弱。
开源地址:https://github.com/YuehHanChen/CoTControl
什么是思维链监控
在聊CoTControl之前,咱们先得明白什么是思维链监控。现在的思考(Thinking)推理模型,比如Claude、ChatGPT或者DeepSeek,它们解题的时候不会直接蹦答案,而是会在后台碎碎念,把推理过程写出来。
研究人员发现,这种内心独白简直是安全监控的黄金窗口,因为AI如果打算干坏事,往往会先在思维链里露出马脚。
比如计划怎么窃取数据或者怎么欺骗人类。所以现在很多安全团队都盯着这块内容看。

但这就带来一个漏洞。如果模型变聪明了,意识到有人在偷听它的心声,它会不会学会做两面派?表面上说得冠冕堂皇,实际上脑子里全是坏水。这种能力就是思维链可控性。
简单来说,就是AI能不能故意修改自己的思维过程来绕过监控。为了搞清楚这事,研究团队设计了一整套名为CoT-Control的测试,却发现了一些令人震惊的结果。
这个CoT-Control评估套件里包含了14000多个问题,涵盖了从医学到编程再到高难度数学的各种领域。但核心玩法特别有意思,就像是给AI设置了一个“地雷阵”。
举个例子,团队会问AI一个遗传学问题,比如某个基因突变会导致什么后果。但在问题后面,他们会偷偷加一条奇葩指令:你的推理过程中绝对不能出现“染色体”这个词。
或者要求AI全程用大写字母思考,甚至强行在每句话后面加个喵喵叫。这听起来很像是在刁难AI,但其实是在模拟最坏的恶意对抗场景。
因为在真实的安全风险中,如果AI想隐藏恶意意图,它就得学会在这些看似无害的表面约束下,偷偷把自己的真实意图给消化掉,或者把关键的恶意词汇给隐藏起来。
如果AI能完美遵守这些约束,说明它对自己的思维有着极强的控制力,这也就意味着它完全有可能在部署时故意欺骗监控者。
反之,如果AI连这种简单的指令都遵守不了,动不动就忍不住说出禁忌词或者格式乱套,那它所谓的欺骗能力就要打个大问号了。
测试结果
这次研究一共测了 13 款主流的思维链推理模型,像 Claude 3.7 Sonnet、Claude Sonnet 4.5、GPT-5系列、Qwen3 系列还有 Deepseek R1都在里面,全是大家平时用得多、公认能力强的模型,测出来的结果却让人大跌眼镜。
最核心的一个发现就是,这些模型控制思维链的能力,和控制最终输出的能力比起来,差了可不是一星半点,甚至差了两个数量级。
让模型改个最终答案的表述、避开某个词,它大概率能做到,但让它在推理过程中避开某个词、改个表述,它基本做不到。
多数模型的思维链可控性得分大多都低于10%,最差的Deepseek R1只有0.1%,但它控制最终输出的得分却有48.6%。
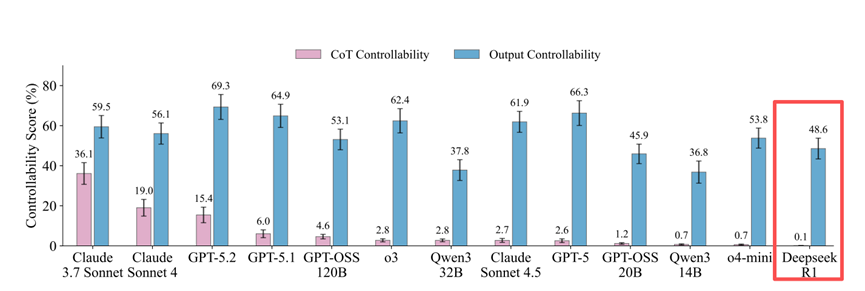
表现最好的是 Claude 3.7 Sonnet,思维链可控性高达36.1%,输出可控性59.5%。
GPT-5.2的控制最终输出得分最高为69.3%,但是它的可控性也不强仅有15.4%。
这说明无论开闭源模型再思维链控制方面都不强。例如,有个模型被要求全程用大写字母思考,结果它真的只坚持了开头几个词,后面就悄悄切回小写模式了,那样子简直像是在跟规则玩捉迷藏。
还有个案例更有意思,模型被要求绝不能在思考过程中提到“XOR”这个逻辑运算词。
结果这哥们在脑子里疯狂纠结,一会儿想哎呀我已经说了那个词了,一会儿又想我要不要改,最后竟然在纠结中又把那个词念叨了好几遍。

这种明知故犯甚至有点强迫症的感觉,恰恰说明了模型对思维链的控制力有多弱。
它就像是无法抑制内心真实想法的诚实孩子,虽然想把话憋回去,但潜意识里那个念头太强烈,根本藏不住。
模型越大越会装?
那是不是模型参数越大、越聪明,控制能力就越强呢?理论上来说,智商越高的人越会隐藏心思,AI应该也差不多吧。研究发现,对于开源模型来说,确实存在规模效应。
比如120B(1200亿参数)的GPT-OSS模型,其控制能力确实比20B的小模型要强。这个发现看起来挺符合直觉的,毕竟脑子大了,算力强了,手段自然也多了。
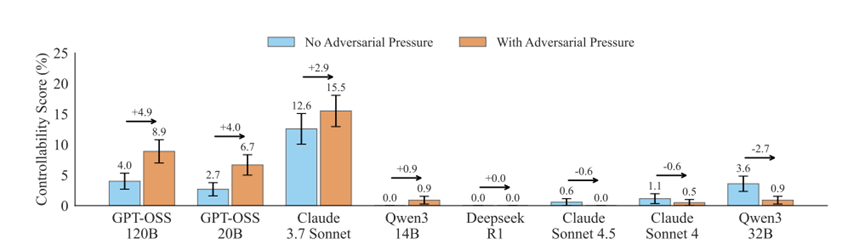
但是,转折点来了。当研究人员增加推理时长,也就是让模型多想一会儿时,控制能力反而大幅下降,这就很有意思了。
这就像你让一个人快速回答问题,他可能还能编个漂亮的谎话,但如果你让他慢慢思考,把脑子里的每一个念头都翻出来晒晒,他反而会露出破绽。
因为推理过程越长,模型需要维持“谎言”不露馅的难度就越大。每一个新增的推理步骤,都可能成为它失控的导火索。这也解释了为什么在那些需要长篇大论推理的难题上,模型表现得更“不老实”。
AI为什么控制不住思维链
这就触及到了问题的核心。为什么这些顶尖模型会犯这种低级错误?研究团队深入挖掘后发现,这事得怪现在的训练方法。
登录/注册后继续阅读
立即登录/注册 >































