
我要认证
2026-03-01
开发过AI应用的朋友都知道,想做一个能看、能听、能说的虚拟AI伴侣有多麻烦。你得分别接入语音识别、LLM、语音合成。
还得想办法让这些模块协同工作,光配置环境就能折腾一天。更别提还要处理实时对话、嘴型同步这些细节问题,整套下来头都大了。
今天介绍一个很火的开源,曾拿下Github每日最佳的AI伴侣Airi。

开源地址:https://github.com/moeru-ai/airi
简单来说,这是一个整合框架,就是把上面那些麻烦事情都集成在了一起,用起来相当方便。
Airi最大的亮点就是模块化设计。你不需要去研究每个AI模型怎么调用,框架已经帮你把语音识别、语言模型对话、语音合成这些环节串联起来了。
就像乐高积木一样,每个功能模块都是现成的,你想怎么拼就怎么拼,不想折腾直接用默认配置也行。对新手来说特别友好,只要跟着教程做就可以了。
目前,已经开发出的功能包括意识、发生和听觉,视觉、记忆功能正在开发中。
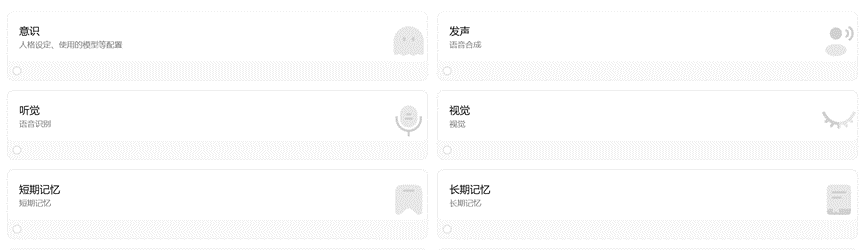
Airi支持实时的语音输入输出,可以像真人一样边听边回应,而不是那种傻傻地等你把话说完才反应,用起来的感觉就像是跟朋友打电话差不多。
嘴型同步和表情驱动这些细节Airi也考虑到了。虚拟角色说话时嘴会跟着动,表情也会根据对话内容有所变化。
虽然听起来是小事,但正是这些细节让角色看起来不那么假。
Airi兼容性很强,不绑定特定的AI模型,你想用哪家的大语言模型都行,例如,OpenAI、Claude、gemini、Minimax、DeepSeek等市面上所有主流开闭源模型。
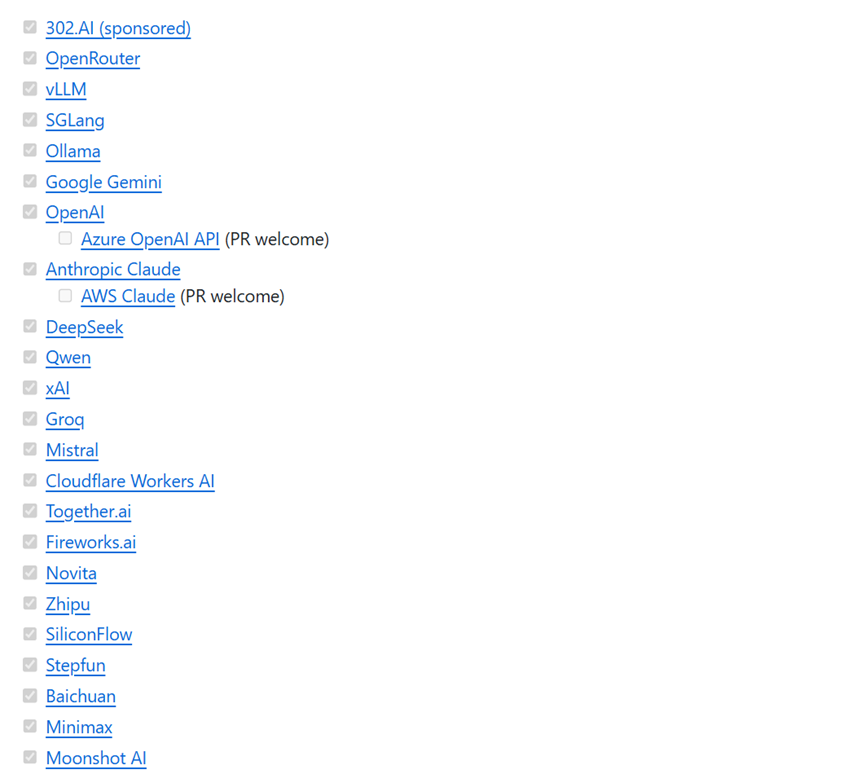
语音识别和合成模块也可以替换。这对于有特定需求或者预算考虑的开发者来说很友好。毕竟不同模型的成本和效果差异挺大的,能自由选择才是王道。
登录/注册后继续阅读
立即登录/注册 >































