
我要认证
2026-02-27
全世界都在等DeepSeek的V4模型,但它却悄悄地和北大、清华联手搞了个大动作,叫DualPath创新架构。
这事在咱们AI圈里还挺炸裂的,毕竟DeepSeek自带巨大流量,而且马上要发布万众期待的V4模型了。
简单来说,这个架构主要解决了智能体推理的时候,被存储带宽卡脖子的大难题。

咱们以前老觉得算力是瓶颈,但研究发现,现在的智能体跟以前那种一问一答的聊天机器人不一样了。
智能体得自己规划任务、调用工具,跟环境交互几十甚至上百轮。虽然每轮说的话不多,但上下文那是越积越多,甚至能到百万token级别。
这就导致一个现象,模型推理的时候,95%以上的时间都在命中缓存,真正需要计算的新东西特别少。这就是典型的IO受限,算力在那闲着,数据却堵在路上读不进来。
现有的架构其实挺尴尬的。主流做法是把预填充和解码分开,搞成两个独立的引擎。
结果就是,负责读数据的预填充引擎忙得要死,网口带宽跑满了,GPU利用率却只有40%,因为都在等数据;而负责解码的那些引擎呢,网口基本闲置,GPU利用率也就80%。
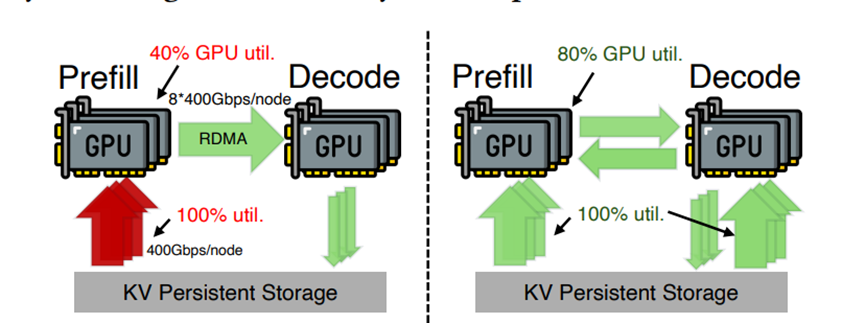
这就好比你有一群人在食堂排队打饭,只有一个窗口开着,排队的人饿得前胸贴后背,旁边的一排窗口却关着,这资源浪费得让人心疼。
而且硬件发展也不太平衡,显卡算力这几年翻着跟头往上涨,可那个PCIe带宽和显存容量就像蜗牛爬,这就让IO瓶颈显得更突出了。
而DualPath最核心的创新就是搞了个双路径加载机制。以前只有预填充引擎能去存储里读数据,现在它把那些闲着没事干的解码引擎也利用起来了。
你可以把它想象成刚才那个食堂,突然把旁边的窗口都打开了,大家都能去取餐,然后通过内部的高速传送带把饭递给真正需要的人。
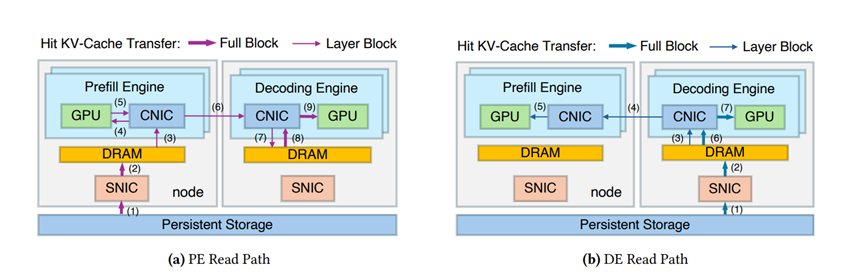
这样一来,所有的存储带宽都被榨干了,以前是独木桥,现在成了通衢大道。而且它还很聪明,把数据传输的时间跟计算的时间重叠起来,让你感觉不到传输的延迟,这也就是所谓的隐藏开销。
为了让这套机制跑得顺滑,研发团队还设计了两个重要的组件。一个是流量管理器,这玩意儿像个交警,专门指挥数据流向。
用了一个以计算网卡为中心的策略,把模型推理的通信流量设为高优先级,其他的设为低优先级,保证那些急着要算的数据不被堵住。
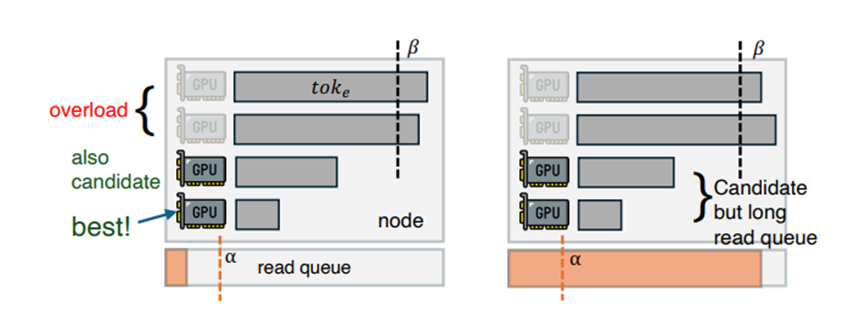
另一个是自适应请求调度器,这就好比是个超级调度员,不仅盯着显卡忙不忙,还盯着网口堵不堵,动态地把任务分配给最合适的引擎,确保大家都有活干,谁也别闲着。
研究团队用三个主流模型做了实测,结果让人眼前一亮。离线推理场景下,DeepSeekV3.2 660B模型的速度最高提升了1.87倍,相当于原来要跑8小时的任务,现在不到4.5小时就能完成。
DeepSeek27B模型也提升了1.78倍,Qwen2.5-32B的表现也不相上下。
登录/注册后继续阅读
立即登录/注册 >































