
我要认证
2026-02-23
字节跳动联合多个机构开源了一个重磅模型BitDance,直接给自回归图像生成技术来了个大升级。
这模型最牛的地方就是不用传统的码本索引,转而预测二进制视觉token,靠三个核心组件解决了老问题,不仅生成质量拉满,速度还快得离谱。
在ImageNet256×256数据集上拿到1.24的FID值,创下自回归模型的最好成绩,生成1024×1024高清图时比之前的自回归模型快30多倍,参数量还少了5.4倍。

开源地址:https://github.com/shallowdream204/BitDance
在线体验:https://huggingface.co/spaces/shallowdream204/BitDance-14B-64x
目前已经开放在线测试啦,生成效果那是相当逼真,是不是有小红书照片感觉了,并且去掉AI生成人物的油腻感。


先说说背景吧,不然有些朋友可能不知道这块儿有多难。自回归生成在文本领域那是混得风生水起,ChatGPT就是典型代表,一个字一个字往后预测,效果杠杠的。
可一到图像领域就蔫了,就像一个学霸突然换了个完全不擅长的科目,咋学都不对劲。
第一个是token设计的平衡问题。图像token得又能装下丰富细节,又不能在生成长序列时出错越来越多。
之前的离散模型用矢量量化,词汇表一扩大就容易出问题,重建出来的图糊里糊涂

第二个是大词汇量采样的效率坑。想让token表达能力强,就得扩大词汇表,但传统分类头根本扛不住。
要么参数量暴增到硬件扛不住,要么假设比特独立忽略关联,采样出来的图质量暴跌,怎么选都不对。
第三个是推理速度慢得让人着急。自回归本来就是一个token一个token地生成,图像分辨率一高,序列变长,等生成完一张图得花老长时间。
后来有并行生成的方法,但都是独立采样token,生成的图要么结构乱,要么有伪影,速度和质量始终不能两全。
而BitDance正好对着这三个痛点下手,从token、采样、解码三个方面全革新,终于让自回归生成在表达力、精度和速度上都达标了。
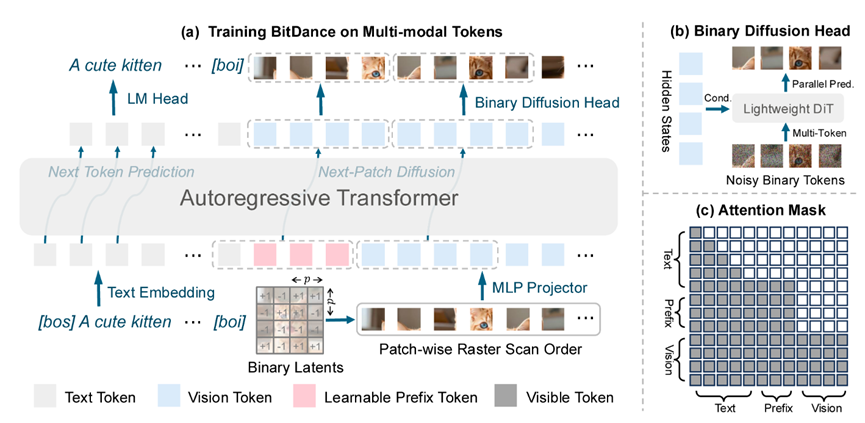
以前的token器要么表达力不够,要么容易出错,BitDance直接用了二进制量化的思路,搞了个大词汇量的token器,把词汇表规模做到了2的256次方,比之前的离散token器大了好几个数量级。
它用的是无查找量化,不用复杂的码本学习,直接把每个通道的数值变成1或-1,形成二进制token。
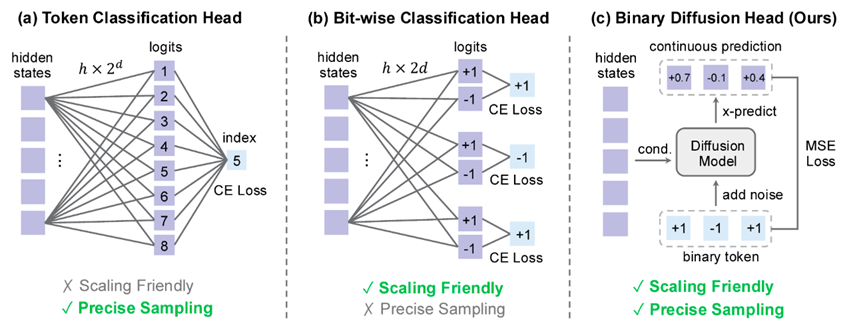
词汇量上去了,怎么精准采样又成了问题,BitDance的二进制扩散头就是来解决这个的。
它不像传统分类头那样硬算,而是把二进制token当成连续空间里的超立方体顶点,用扩散模型来建模,既控制了参数量,又没丢采样精度。

举个例子,要是直接建模32通道的二进制token,传统分类头得要4.4万亿参数,根本不现实。
逐比特分类虽然参数少,但忽略了比特间的关联,采样出来的图质量差。
而二进制扩散头把离散token映射到连续空间,用整流流公式优化,加噪声再去噪声,最后再转成二进制,完美平衡了效率和精度。
解决了token和采样问题,最后就是提升速度了。BitDance发现图像里局部块的token关联性很强,就像搭积木时相邻的积木总是配套的,所以可以把这些token分成块,一块一块地并行生成,而不是一个一个地来。
登录/注册后继续阅读
立即登录/注册 >































