
我要认证
2026-02-13
如果你手头有成百上千份文档,需要从中提取特定信息,比如从医疗报告里抓症状,从合同里扒关键条款,或者从文学作品里理人物关系。
传统做法基本上就是两条路,要么人工看,累死人,要么写正则表达式,写死人,而且还特别容易出错。
谷歌开源的langextract就是专门来解决这个问题的。能让你用几行代码,就从一个PDF文档,一本小说,甚至一堆复杂的医疗报告中,自动提取出你需要的信息。
最关键的是,还能准确定位到原文位置,再也不用担心这信息到底从哪来的难题了。
开源地址:https://github.com/google/langextract
这是一个基于大模型的结构化信息提取Python库。简单来说,就像一个超级智能的文本扫描仪,不仅能自动识别文本中的关键信息,还能把信息整理成你想要的格式,并且精准标注这些信息在原文中的位置。
下面说说langextract的主要核心功能
Langextract在效率方面真的是爆炸级别的,几秒钟就能处理完人工需要几小时的工作。
精准度方面也特别可靠,每个提取结果都能追溯到原文,不像传统OCR那样完全是个黑箱操作。使用门槛方面更是低到令人发指,只需提供几个示例,无需训练模型,上手即用。
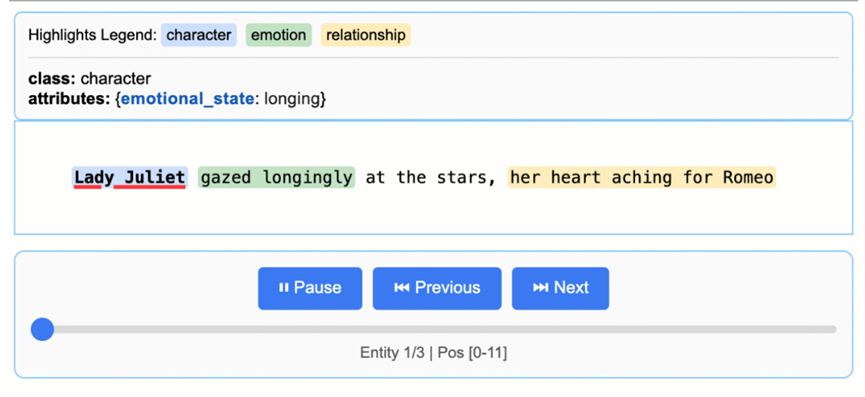
先说精准来源定位。每一个提取的信息都会精确标注在原文中的位置。这意味着什么呢,就是你再也不用担心这结论从哪儿来的这个问题了。
每个结果都能追溯到原文,可视化高亮显示,就像给文本做了个GPS定位。审计也好,查证也罢,都变得一目了然。

再说可靠的结构化输出。根据你提供的示例,它能强制生成统一格式的结构化数据。
不再是那种差不多就行的提取结果,而是严格遵循你定义的数据结构输出。配合Gemini模型的controlled generation技术,准确率真的相当不错。
然后是长文档优化处理。针对大型文档做了特别优化,采用智能分块,并行处理,多轮扫描等策略。
面对那种大海捞针式的文档,比如200页的医疗报告,也能快速找到关键信息。传统方法处理长文档容易顾此失彼,langextract能保证很高的召回率。
登录/注册后继续阅读
立即登录/注册 >































