
我要认证
2026-02-05
最近刷到个超牛的技术突破,快手的Kling团队联合清华大学和中科院自动化所的大神们,搞出了一个叫3DiMo的框架,直接解决了人体视频生成领域卡了好久的痛点。
简单说就是以前咱们用AI生成人物动作视频,要么被死死绑在固定视角里,换个角度人物动作就崩了,要么依赖那些死板的3D模型,生成的动作僵硬得像木偶。
现在有了3DiMo,既能精准复刻驱动视频里的动作,还能随心所欲调视角,简直是虚拟数字人、影视制作的大突破。

论文:https://arxiv.org/pdf/2602.03796
咱们直接看效果,非常丝滑的模拟鸡哥的打篮球动作。
网红小舞蹈轻松拿捏。
注意看,这可不是简单的2D平面模拟,而是3D立体空间的非常精准。
咱们都知道,现在市面上那些能让人跳舞、让人动起来的AI技术,说白了大多还是基于二维平面的。这就好比是你教一个人画画,你只让他看正面,那他画出来肯定也就只有正面。
以前的这些老办法,要么就是提取个二维骨架,要么就是搞个显式的三维模型。
用二维骨架的问题在于,它把动作和视角死死绑在了一起,视频是正面拍的,AI生成的也就是正面的,你想换个侧面看看?没门,因为它根本不理解侧面该长啥样。
而那些用显式三维模型的方法呢,理论上好像通了三维的道理,但实际上却很尴尬,因为从二维视频里恢复出来的三维模型,精度往往不够高。
有时候胳膊腿的位置都会搞错,这就导致生成的视频看着特别别扭,动作僵硬不说,连物理规律都违背了。
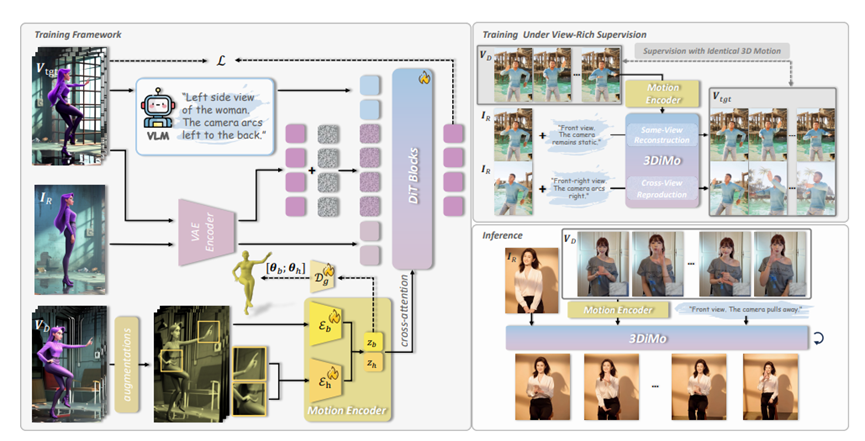
所以,研究团队就想,既然现在的大视频模型本身就很聪明,有点像人脑一样能理解空间关系,那咱们为什么非得用那些笨重又不准的外部模型去硬套它呢?
不如直接让模型自己从视频里悟出动作的精髓,这就是3DiMo最核心的想法。
要做到这一点,光靠嘴说肯定不行,得有真家伙。3DiMo的这套组合拳里,最厉害的一个模块就是他们设计的隐式运动编码器。
你可以把这个编码器想象成一个特别会抓重点的观察员。以前的方法像是把每一帧的画都原封不动地记下来,连背景是啥样都记着,但这东西没用,反而会干扰判断。
3DiMo这个编码器就聪明多了,它把那些花里胡哨的外观啊、具体的背景啊全都丢掉,只提炼出动作最核心的那个意思,变成一串特别紧凑的代码。
这个过程就像是看武侠片,你记住了那个大侠打了一套拳,但你记不住他当时穿的是红衣服还是蓝衣服,也记不住旁边有没有棵树,你只记住了那一招一式的精气神。

而且为了让它学得更纯粹,研究人员还在训练的时候故意给视频加了一些花样,比如随便改改颜色,或者假装换个角度看,逼着这个编码器只能去关注动作本身,而不是那些细枝末节的表面功夫。
光有了理解动作的大脑还不够,还得有一双灵巧的手把动作画出来。3DiMo用了一个现在很火的叫DiT的架构作为底座,这玩意儿经过海量视频的训练,天生就知道怎么画人才像人,怎么动才自然。
那么,编码器看懂的动作,是怎么告诉这个画家的呢?这里他们没用以前那种死板的拼接方式,而是用了一种很像人类沟通的交叉注意力机制。
咱们打个比方,就像是编码器在画家的耳边悄悄说了一句诀窍,画家听了之后,心领神会,手里的画笔自然就跟着动了。
但是,光教它看动作还不够,还得让它明白什么是三维空间。如果一个AI只看过正面的视频,你让它画侧面的动作,它肯定会瞎蒙。
登录/注册后继续阅读
立即登录/注册 >































