
我要认证
2026-02-04
刚刚,阿里巴巴扔出了王炸开源Qwen3-Coder-Next,直接改写了编码AI的游戏规则。
这个模型的总参数一共有800亿,仅有30亿参数处于激活状态,可以轻松在本地部署,但性能却异常强悍。

开源地址:https://huggingface.co/collections/Qwen/qwen3-coder-next
https://modelscope.cn/collections/Qwen/Qwen3-Coder-Next
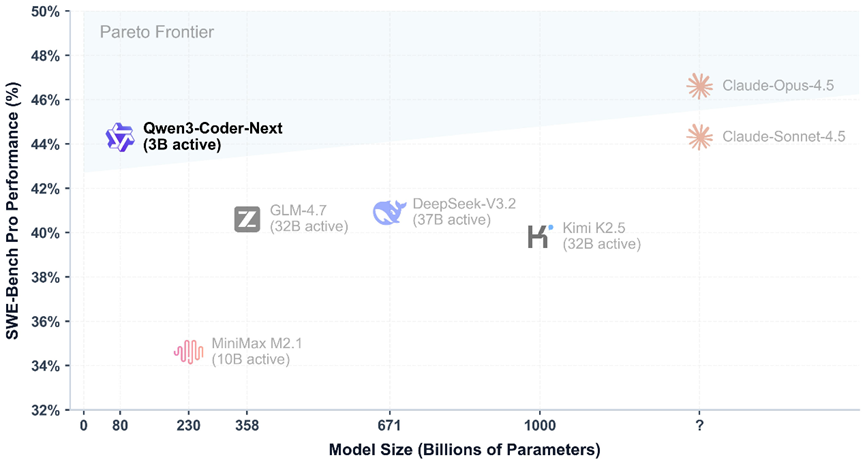
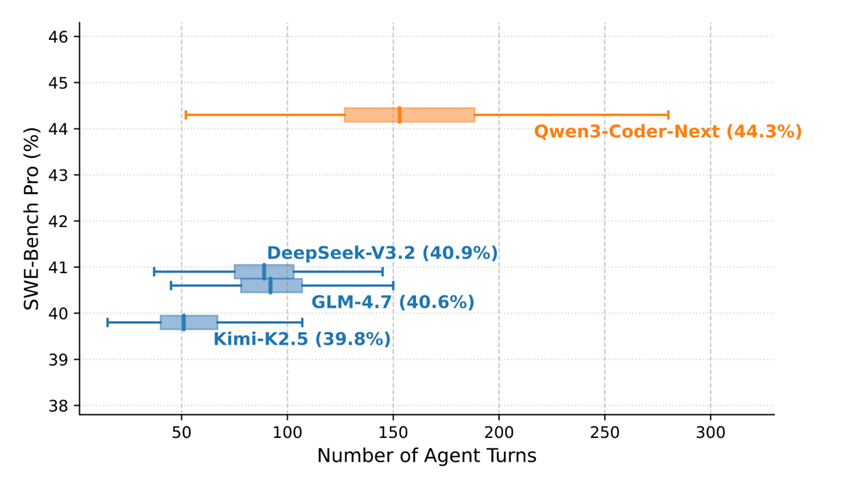
根据测试数据显示,Qwen3-Coder-Next在SWE-Agent、MiniSWE-Agent、OpenHands三大主流智能体测试中表现非常不错,分别取得70.6%、71.1%、71.3%的得分,比DeepSeek-V3.2、GLM-4.7、KimiK2.5更强。
因为它仅使用了30亿参数,而这三个参数在320亿和370亿,同时可以比肩闭源顶级编程模型Claude-4.5。
在通用知识与推理测试中,Qwen3-Coder-Next仍保持了强劲的通用能力。MMLU测试得87.73%,与通用模型Qwen3-Next87.87%几乎持平。
MMLU-Redux达91.18%,GPQA为74.49%,均略高于Qwen3-Next,显示出编码训练对通用推理的正向迁移效应。
数学竞赛基准测试中,模型表现尤为突出,HMMT25Feb得70.21%、HMMT25Nov得75.57%、AIME24得89.01%、AIME25得83.07%。
相较于Qwen3-Next均实现10-16个百分点的大幅提升,验证了代码推理能力向数学推理的有效迁移。
Qwen3-Coder-Next的底子是Qwen3-Next,核心亮点就是混合注意力机制和MoE架构这俩组合拳。800亿参数只是它的知识库,里面藏着各种编程技能,但干活时只让最擅长当前任务的30亿参数出马。
其实Qwen3-Coder-Next最牛的不是架构,而是它的训练方式。以前的编程AI都是对着静态代码库死记硬背,就像只看菜谱不进厨房的厨师,知道步骤但做不出好菜。
而这个模型是在真实的编程环境里练出来的,从任务设计到训练执行,每一步都贴近实际开发场景。
要练出厉害的AI,得有足够多的真实任务。阿里团队用了两种方法攒素材,最后凑出了超80万可验证的编程任务,覆盖了Python、Java这些常用语言。
一种是从GitHub上扒真实的问题修复案例,把每个修复拆成有问题的代码、正确的解决方案和测试脚本三部分,还专门做了可运行的环境。
这样AI就能像跟着资深程序员学干活一样,知道实际开发中遇到的bug该怎么修。
另一种是在现有开源项目基础上造新任务,通过各种方式给正常代码注入可控的bug,还得保证这些bug能通过特定修复解决,确保AI练的都是有用的技能。
这么多任务要高效完成,得有靠谱的平台支撑。团队自己搞了个叫MegaFlow的系统,基于阿里云的Kubernetes搭建,能让海量任务并行运行。
登录/注册后继续阅读
立即登录/注册 >































