
我要认证
2026-02-02
最近上海人工智能实验室联合上海交大、北大、港大等一票大牛,开源了一个高精准多模态数据集MMFineReason。
这个数据集一共有180万样本,包含51亿个解决方案tokens,在使用该数据集训练的大模型,可以媲美GPT-5、Gemini-3等顶级闭源模型。

开源地址:https://huggingface.co/collections/OpenDataArena/mmfinereason
咱们都知道,像GPT-5或者Gemini3这种大模型,数学题做得好,看图推理也厉害,但这背后其实是有秘密的。它们都吃了海量且精心整理的私有数据,这就像人家是吃着米其林大厨特供的营养餐长大的,身体自然壮实。
反观开源社区,大家手头的资源就比较寒酸了。现有的开源数据集不仅数量不够,质量也参差不齐,特别是在那些特别烧脑的STEM图表或者视觉谜题领域,高质量的标注少得可怜。而且,很多标注缺乏连贯的长形式思维链。
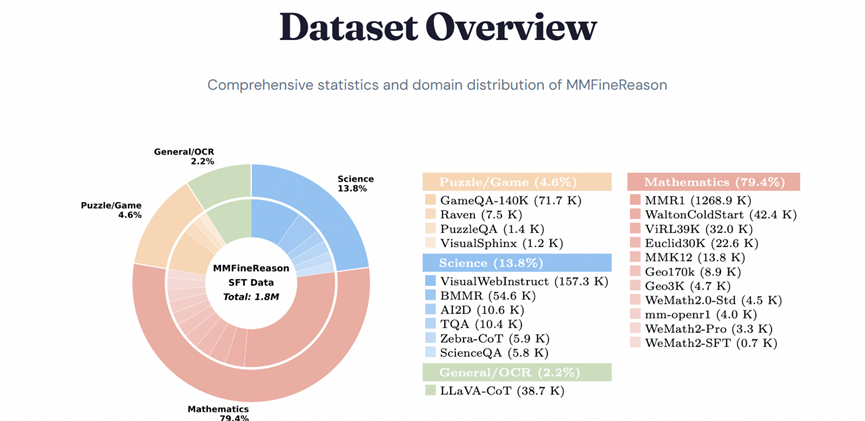
所以,研究团队把火力全集中在了高质量数据上。MMFineReason里面足足装了180万个样本,解决方案的标记数量更是达到了惊人的51亿个。
更关键的是,这些高质量的推理标注都不是人工死磕出来的,而是蒸馏自目前最强的开源大模型Qwen3-VL-235B-A22B-Thinking,相当于把学霸的脑子里的解题思路给复制了下来。
不过这数据集也不是随便堆出来的,人家那是走了一套非常严谨的三段式流水线,每一步都抠得特别细。
第一阶段就是大规模的收集和标准化。团队先是从开源社区把各种各样现成的多模态数据集都扒拉下来,以FineVision数据集为基础,人工筛掉了那些跟STEM、推理八竿子打不着的内容,只留下有营养的干货。
为了让覆盖面更广,他们又特意把BMMR、Euclid30K这些高质量的数学、科学以及视觉游戏谜题数据集给混了进来。
到了第二阶段,就是最核心的思维链推理逻辑生成了。为了让数据集里的每道题都有高质量的解题过程,团队选了Qwen3-VL-235B-A22B-Thinking做老师。
这老师特别厉害,它解题的时候得严格按照四步走,先是把所有信息都扒拉清楚,然后搭建解题策略,接着是一步一步严谨地执行计算,最后还得验证结果对不对。

第三阶段就是综合筛选了。原始数据集虽然大,但肯定有水分,得把杂质挤出去。
先是模板和长度验证,没按规矩输出的、过程写得特别短的,直接踢掉。然后是去重,要是发现一段推理里有重复的套话或者重复的词组,说明是糊弄事,要么删了要么重写。
最狠的是正确性验证,拿老师给出的答案和标准答案对一对,凡是推理错的或者胡编乱造的,哪怕再花哨也不要。
这一轮下来,差不多两成的水分被挤掉了。最后剩下来的就是精华,也就是那180万样本、51亿标记的高质量MMFineReason数据集。
为了验证MMFineReason数据集到底好不好用,研究团队基于Qwen3-VL-Instruct模型,分别在2B、4B、8B三种参数规模下进行微调。
登录/注册后继续阅读
立即登录/注册 >































