
我要认证
2026-02-01
AI有时候挺聪明,可一旦碰上那种特别难的数学推理题,它立马就卡壳了,不管你怎么试它就是做不出来。
这其实就是因为传统的训练方法到了瓶颈期,面对那种完全没思路的难题,模型就像个只会死记硬背的学生。
最近麻省理工学院和MetaFAIR实验室搞了个非常强的框架SOAR,硬生生突破了那些看似无解的推理难题,这波操作简直颠覆认知。

以前为了让模型更会做题,咱们通常会用强化学习,就是做对了给糖吃,做错了打板子。但这招有个死穴,那就是如果题目难得离谱,模型完全蒙不对,那它就永远拿不到糖,也就不知道自己错哪了。
之前也有人想过用课程学习,就是从易到难慢慢教,但这得靠人一点点去整理数据,那工作量简直让人抓狂,根本不现实。
MIT和Meta的团队就提出了一个大胆的想法:既然预训练大模型已经学了那么多知识,能不能让它自己从这些知识里提炼出“阶梯式”的练习题,自己教自己突破难题?顺着这个思路,SOAR框架就诞生了。
SOAR框架的设计特别巧妙,核心就是让一个模型“分身”成两个角色老师和学生,再通过一套闭环系统让两者互相促进。
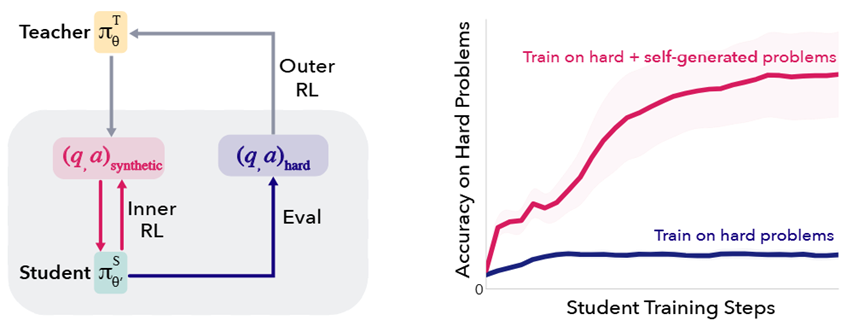
先给大家理清这个逻辑:一开始老师和学生是同一个模型,能力完全一样。老师的任务不是直接解决高难度问题,而是根据自己的知识库,生成一堆合成练习题给学生做。
学生做完这些题后,再去挑战真正的难题,学生的成绩提升多少,就给老师多少奖励。这样一来,老师就会慢慢摸清什么样的练习题能帮学生最快进步,生成的题目也会越来越精准。
这里有个关键设计,就是老师的奖励完全绑定学生的真实进步,而不是靠什么内在评分标准。
这就像好老师备课,不会只顾着出难题,而是盯着学生的薄弱点针对性出题,最终目的是让学生能搞定考试真题。
整个框架运作起来分两个循环:外层是老师的训练循环,老师生成一批题目,分成好几组,让学生分别训练,最后根据学生的进步情况给每组题目打分,老师再根据这个分数优化自己的出题思路。
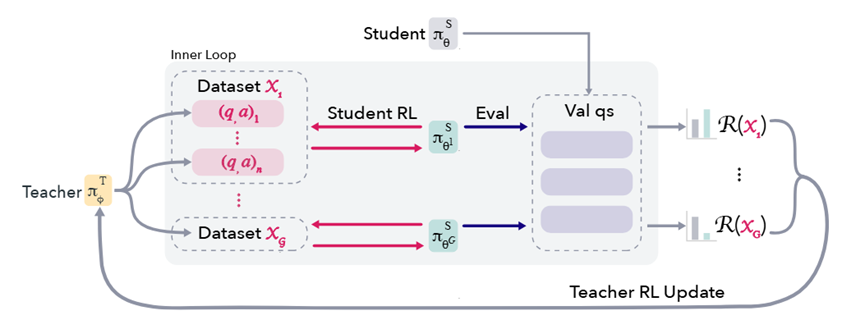
内层是学生的训练循环,学生在每组题目上训练10步左右,既能看出训练效果,又不会浪费太多计算资源,训练完就回到初始状态,准备下一组题目的测试。
还有个特别贴心的“学生晋升机制”。当学生通过老师的题目训练后,能力明显提升了,系统就会把学生的“基础线”拉高,老师之后就要出更难的题目才能拿到奖励。
这就像我们升级打怪,等级提升了,怪物强度也会跟着涨,逼着老师和学生一起进步。
那些真正帮学生升级的好题目,会被收集起来形成“晋升问题集”,相当于模型的专属错题本和进阶题库。
为了验证SOAR框架是不是真的有用,研究团队的实验设计得特别严格,简直是往模型的痛处上戳。

登录/注册后继续阅读
立即登录/注册 >































