
我要认证
2026-01-28
今天早上6点,谷歌发布了Gemini 3 Flash 全新功能Agentic Vision智能视觉,将静态图像理解升级为智能交互流程。
这个功能主要融合了视觉推理与代码执行,以 思考 - 行动 - 观察闭环运作,依托视觉证据输出答案。
还能让多数视觉基准测试的效果稳定提升5%-10%,是视觉AI智能体的重大突破。
体验地址:https://aistudio.google.com/prompts/new_chat?model=gemini-3-flash-preview
详细说明文档:https://ai.google.dev/gemini-api/docs/code-execution?hl=zh-cn#images
你有没有试过让AI看一张特别复杂的图,比如那种满是细节的建筑图纸或者密密麻麻的电子元件?很多时候AI就是那种大概看一眼,然后就开始蒙。
这就好比你让一个远视眼的人去读一本小字书,他根本看不清就只能瞎猜。这就是传统AI处理图像的方式,一次性看完,看到多少算多少。
谷歌这次在Gemini 3 Flash里加了个叫Agentic Vision的功能,说白了就是让AI学会了像人一样看东西。
它不再是那种只看一眼就下结论的急脾气,而是会仔细琢磨,觉得哪里没看清楚就凑近了再看。
这个功能最核心的地方就是它把视觉理解变成了一套很灵活的流程。AI拿到一张图后,会先琢磨一下用户到底想知道什么,然后制定一个计划。
这个计划可能包含好几步,比如先看看整体情况,再放大某个区域仔细瞧瞧,甚至可以把图旋转一下换个角度看。
说到这你可能要问,AI怎么放大或者旋转图片呢?其实它不是真的凑到屏幕前去眯眼看,而是通过写Python代码来操作图片。听起来有点绕对吧,我给你打个比方。
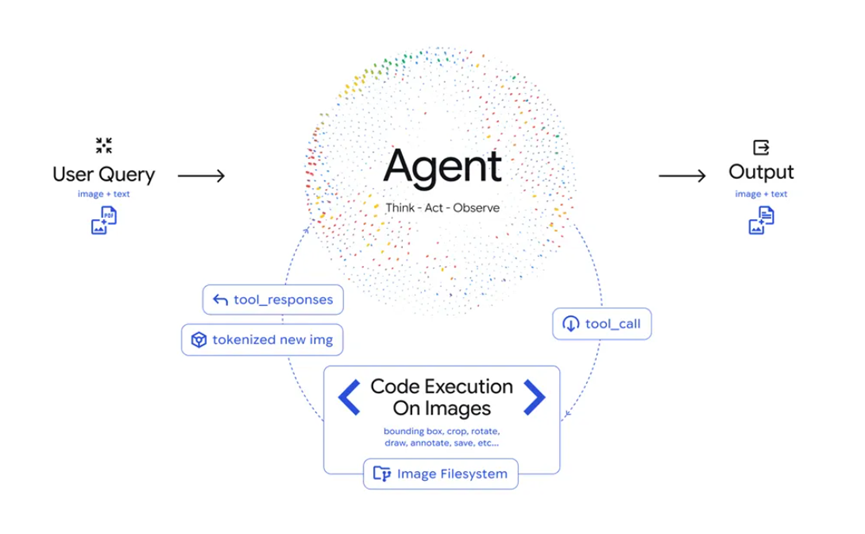
这就好比你要研究一幅复杂的古画,你可以用放大镜一块一块地看,甚至把局部打印出来贴在墙上慢慢研究。AI做的事情本质上是一样的,只不过它的放大镜是代码而已。
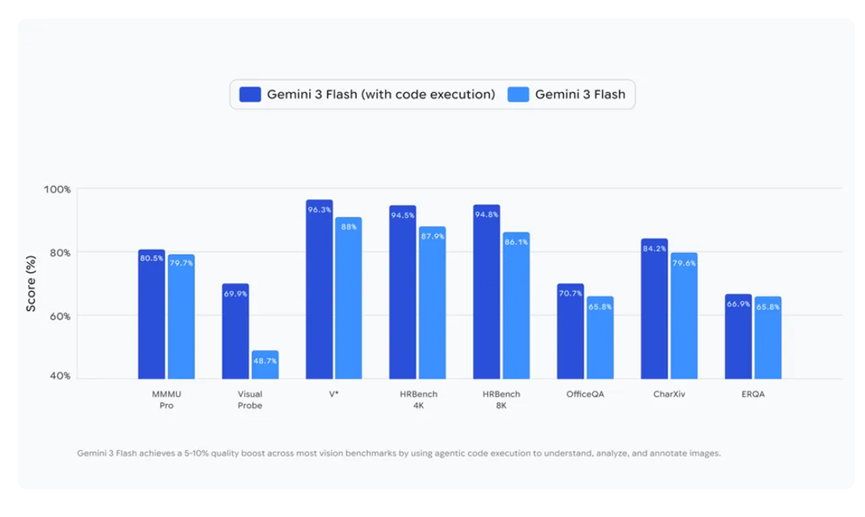
这个做法带来的效果还挺明显的。谷歌说在大多数视觉测试任务上,准确率能提升5%到10%。你别觉得这个数字小,在AI领域这个提升已经相当可观了。
现在来聊聊具体能用它干啥。第一个场景就是检查特别精细的细节。有个叫PlanCheckSolver的平台专门验证建筑图纸,他们用这个新功能后准确率提高了5%。
AI会把图纸切成小块,逐个区域去检查细节,比如屋顶的边缘啊,建筑结构啊什么的,确保符合那些复杂的建筑规范。这就像以前验收房子时,验收员拿着清单一项项核对,现在AI也能这么干了。
第二个场景是给图片做标注。以前AI只能用文字描述它看到了什么,现在它可以直接在图片上画出来。举个例子,你让它数数一共有几根手指,它不仅告诉你数字,还会给每根手指画个框标上编号。
登录/注册后继续阅读
立即登录/注册 >































