
我要认证
2026-01-23
现在多模态大模型虽然能听懂人话,也能看懂图片,但一旦涉及到像素级的精准操作,比如把图里那个穿红衣服的小姐姐单独扣出来,这事对于大模型来说其实挺难的。
以前咱们做这种区域识别,要么是用一大堆数字去框定位置,要么就是专门搞个分割头,不仅笨重,训练起来还费劲。
字节跳动、武汉大学等研究人员联合开源了一个重磅模型SAMTok,硬生生地把一个复杂的图像遮罩压缩成了仅仅2个文本token,并且还能精准抠图,直接颠覆了整个多模态赛道。

开源地址:https://github.com/bytedance/Sa2VA/tree/main/projects/samtok
在线体验:https://huggingface.co/spaces/insomnia7/SAMTok
SAMTok同时提供了在线体验。例如,我们上传一张图片,然后仅用了不到30秒时间就完成了快速分割,效率太爽了。
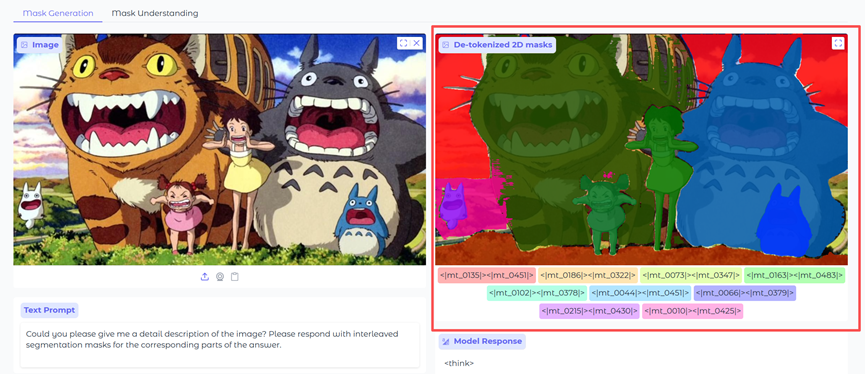
在比如,上传一张非常复杂的图像,然后只扣出站立的人。就算用PS也是相当费劲。
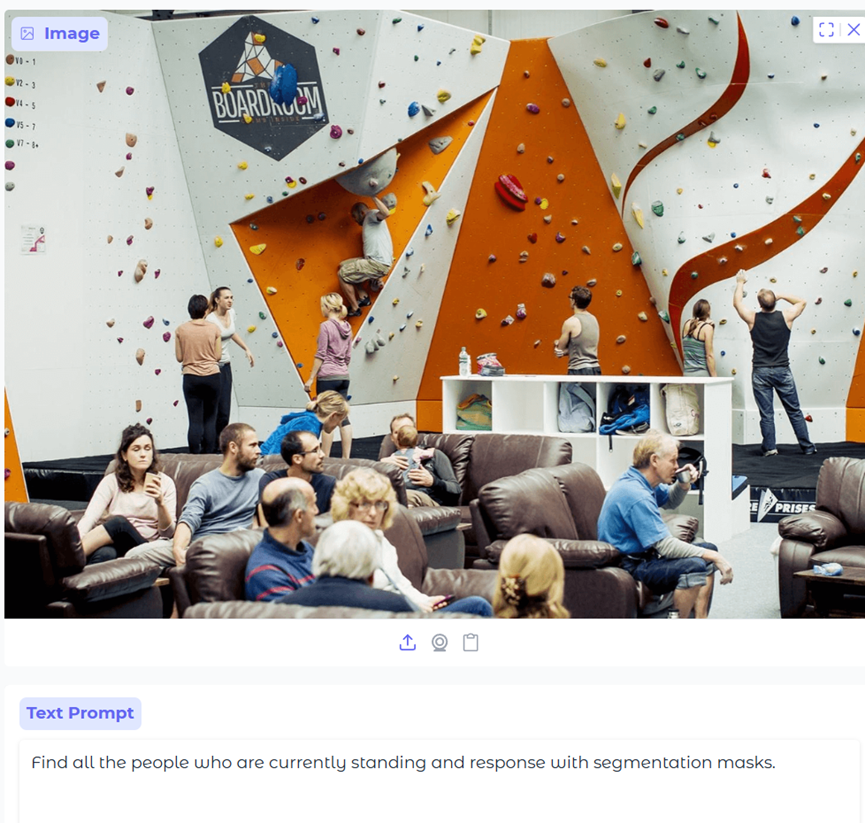
而现在用AI只需要一键+提示词,30秒完事。

咱们来聊聊SAMTok到底是怎么做到的,为啥这么牛。以前大模型处理图像区域,就像是指挥官在地图上画圈,得把坐标、边界框这些数据一股脑塞进去,不仅数据量大,而且模型理解起来也费劲。
而SAMTok真的给人一种脑洞大开的感觉,思路其实特别清奇,它不跟那些复杂的像素纠缠了。
它想了个招,把图像里的任意一个区域,不管它形状多奇怪,是一个圆还是个不规则的多边形,甚至是一根细细的线,它都用一种叫残差量化的技术,把这一大坨信息压缩成两个特殊的token。
你可以把它想象成一个超级压缩大师。以前你要描述图里的一只狗,可能得用几百个数字去描绘它的边缘轮廓。
现在SAMTok来了,看了一眼,直接从字典里掏出两个代号,比如这就好比是暗号A和暗号B。只要大模型看到这两个代号,立马就能在脑海里还原出这只狗的精确形状。
这种用两个token就代表任意形状区域的能力,直接把以前需要几十甚至上百个token才能描述清楚的信息量给浓缩到了极致,推理成本自然也就降下来了。
更有意思的是SAMTok带来的训练方式的变革。以前的模型想做像素级理解,得搞专门的架构,损失函数都要重新写,什么DiceLoss啊、BCELoss啊,一大堆公式。
这就导致它很难像咱们平时聊天的大模型那样,通过简单的预测下一个词来进化。但是SAMTok把掩码变成了token之后,情况就完全变了。

对于大模型来说,生成一个分割区域,跟写一句诗或者编个段子在原理上没任何区别,都是在预测下一个该出哪个词。这意味着我们完全可以把强化学习这套玩意儿直接用上去,而不需要像以前那样还得专门设计奖励机制。
比如说模型回答对了,咱们就给它奖励,错了就惩罚,这跟教AlphaGo下棋是一个道理,只不过现在它学的是怎么精准地抠图。这种统一性让整个训练过程变得特别丝滑,不需要搞那些复杂的定制化模块,拿来就能用。
只要用下一个token预测损失进行有监督微调,再配合一点简单的强化学习,模型就能掌握像素级能力。这就像是把复杂的图像处理任务,变成了简单的填词游戏,大模型玩起来那是相当顺手。
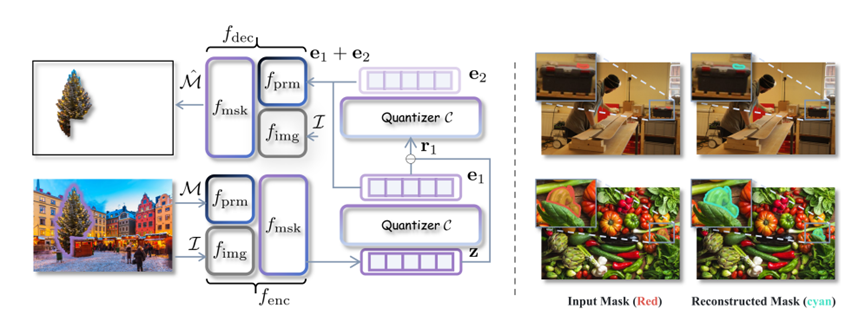
当然啦,要想让SAMTok好用,没点硬核的数据那是肯定不行的。研究团队这次也是下了血本,他们为了训练这个SAMTok,愣是收集了209M个多样化的掩码数据。
你想想这个数量级,两亿多个掩码啊,涵盖了室内室外、网页界面、各种乱七八糟的场景。这就好比是让一个学生刷了两亿道题,那见到什么考题肯定都不慌了。
而且为了让大模型能适应这种新的表达方式,他们还专门构造了大概500万个交错掩码和文本的样本。
这些样本把各种任务,比如你要描述一个区域,或者让你根据描述把区域找出来,统统都转化成了纯文本的形式。
登录/注册后继续阅读
立即登录/注册 >































