
我要认证
2026-01-18
在本地部署玩大模型的都知道,模型上下文越长越好用,但显卡内存直接告急,跑个长文本推理卡到不动,或者直接爆显存闪退。
英伟达直接开源了显存优化神器KVzap。简单来说,KVzap就是给大模型的KV缓存做了个智能瘦身手术,能把缓存体积压缩2-4倍,又几乎不影响推理精度。
就像给你的手机做了系统优化,存储空间变多了,运行速度还更快了,关键是所有功能都正常用。

要明白KVzap有多牛,得先知道KV缓存到底是啥。咱们用模型生成文本时,每个输入的字都会变成一组叫键和值的向量,这些向量会存在KV缓存里,后面生成内容时反复用,不用重新计算。
这就像你写作文时会在草稿纸上记要点,后面接着写的时候直接参考,不用再从头想。
但问题来了,现在模型的上下文能到几十万字,草稿纸越记越厚,显卡的内存根本扛不住。
比如经典的Llama1-65B模型,要是处理128k长度的文本,KV缓存就得占335GB内存,普通显卡根本顶不住。
而且缓存越大,模型读取数据的速度越慢,生成第一个字的时间越长,整体响应也跟着拖后腿。
之前行业也试过各种优化,比如让多个查询头共用一组键值,或者压缩向量的维度,这些方法确实能省点内存,但都没解决最核心的问题,就是文本越长,缓存占用越多的问题。
有些剪枝方法要么把模型精度搞崩了,要么只能在特定阶段用,没法兼顾输入长文本和生成长文本两个场景,一直没能普及。
KVzap之所以这么猛,主要是有大三超强优化功能。
第一个是给KVzip做了个升级,变成KVzip+。之前最厉害的剪枝方法是KVzip,但它有个毛病,得先把输入文本翻倍,才能判断哪些键值没用,又慢又占空间,还不能在生成文本的时候用。
KVzap就聪明了,借鉴了别人的研究,给判断标准加了个归一化调整,不用翻倍文本,也能精准识别哪些键值是多余的,判断准确率还比原来更高。
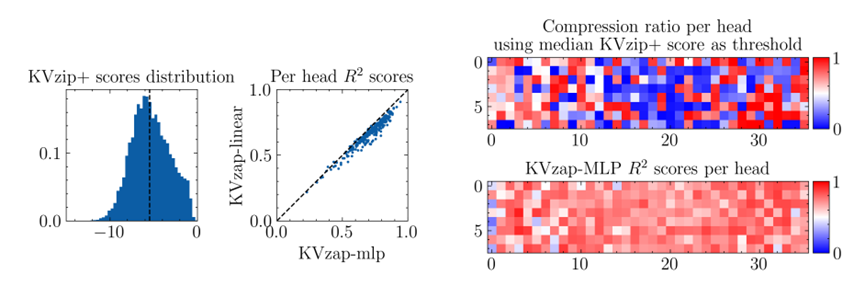
第二个绝招是用轻量级模型代替复杂计算。KVzap没有硬算每个键值的重要性,而是训练了两个超简单的模型,一个是线性模型,一个是两层的小神经网络。
这俩模型就像经验丰富的编辑,扫一眼文本就能判断哪些内容重要,哪些可以删,而且计算量特别小,最多只增加1%左右的开销,甚至在显卡空闲的时候就能完成,完全不耽误正事。
为了让这两个小模型靠谱,研究团队用了包含英语、多语言文本、代码、数学题的多样化数据集,练了120万组样本。
结果就是,小模型判断键值重要性的准确率特别高,和复杂计算的结果相关性能到0.6-0.8之间,相当于抄作业抄得又快又准。

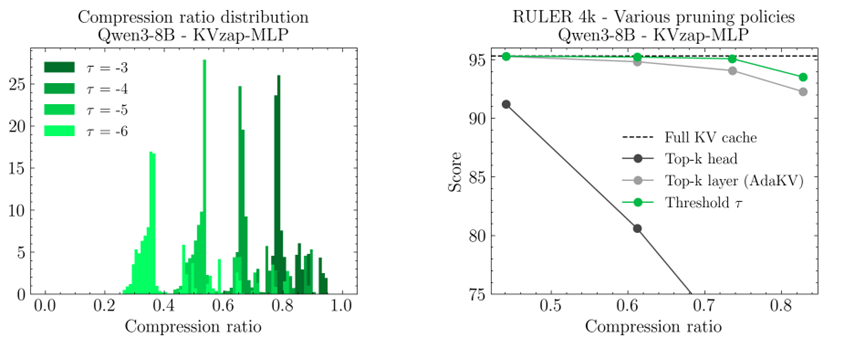
第三个设计是自适应剪枝加滑动窗口。KVzap不是固定删多少内容,而是设定一个阈值,低于这个阈值的键值才删掉,文本冗余多就多删点,内容复杂就少删点,特别智能。
同时还保留了最近128个token的内容,就像看书时不会跳过刚读的段落,保证上下文连贯。实验证明,128个token的窗口刚好够用,再大也不会提升效果,还浪费内存。
最关键的是,KVzap的额外开销几乎可以忽略。Qwen3-8B用的MLP版本才7600万参数,相对于主模型的80亿参数,简直是九牛一毛,计算开销最高也才1.09%,线性版本更是低到0.01%,平时根本感觉不到它在工作。
登录/注册后继续阅读
立即登录/注册 >































