
我要认证
2026-01-17
现在的Sora、Runway、可灵等模型生成的视频确实很逼真,但生成个10秒视频要等好久。如果是本地部署,时间更是长的没边。
这要是放在VR眼镜或者机器人导航里,等你画面生成出来,黄花菜都凉了,根本没法实时交互。
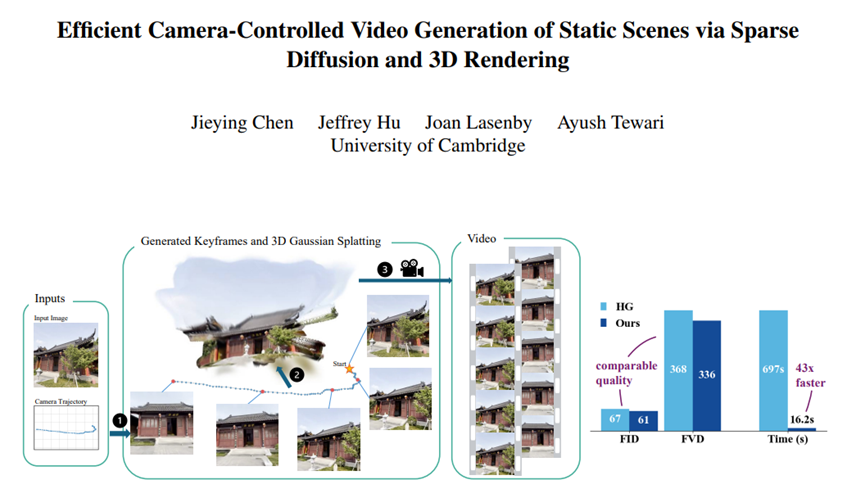
所以,剑桥大学的研究人员开发了Srender框架,同样生成20秒30帧的视频,以前要近700秒,现在只要16秒多,速度提升40多倍,并且画质还没打折。
现在主流的视频生成模型,不管是扩散模型还是流匹配技术,都在干一件事:逐帧生成。就像你要画一本连环画,每页都要从零开始画,哪怕两页内容就差一点点视角变化,也要重新动笔。
这些模型生成一帧画面,要经过无数次神经网络运算去噪,短则几千次多则上万次,积累下来,生成一段视频的时间自然就长得离谱。就拿常用的HG模型来说,20秒30帧的视频要算近700秒,平均每秒才生成0.86帧。
后来也有人想优化,比如设计更紧凑的网络结构,或者用蒸馏技术压缩模型,但本质上还是在逐帧画连环画,没跳出这个框架。
可视频这东西本身就有很多重复信息啊,尤其是静态场景,比如你围着一栋房子拍,不管视角怎么转,房子本身没变,只是你看的角度不同。剑桥团队的Srender就是抓住了这一点,换了个完全不同的生成思路。
Srender就是把“逐帧生成”改成了“先建模再渲染”。这就像拍电影,以前是每个镜头都要实景搭建、重新拍摄,现在是先做一个完整的3D场景模型,之后不管想从哪个角度拍、拍多久,直接用模型渲染就行,效率不就彻底起飞了嘛。
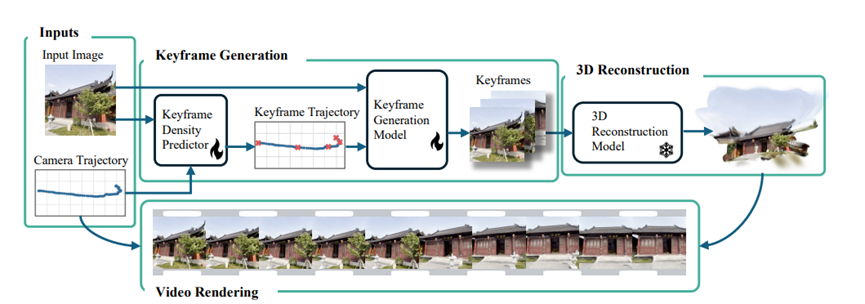
Srender的关键核心生成流程一共分成了4大块。
第一步:智能选关键帧不做无用功
要建3D模型,不用拍所有角度,选几个关键视角就行。但选多了费时间,选少了模型建不完整,容易出现漏洞。Srender就像个经验丰富的摄影师,能精准判断该拍多少张、拍哪些角度。
里面有个关键帧密度预测器,会先分析相机要走的轨迹。如果轨迹平滑,比如慢慢平移,4到8个关键帧就够了.
如果轨迹复杂,比如大幅度旋转、快速切换视角,就多安排些,最多也就35个。要知道,20秒30帧的视频有600帧,现在只需要生成十分之一的关键帧,工作量直接砍到原来的零头。
这个预测器还很聪明,会结合场景外观来判断。它先把相机的位置和旋转信息转换成电脑能懂的向量,再提取输入图像的核心特征,两者结合起来分析,最后给出最优的关键帧数量。
第二步:生成高质量关键帧保证模型精准
关键帧的质量直接决定3D模型的好坏,Srender用扩散模型生成关键帧,但不是简单套用,而是做了不少优化。
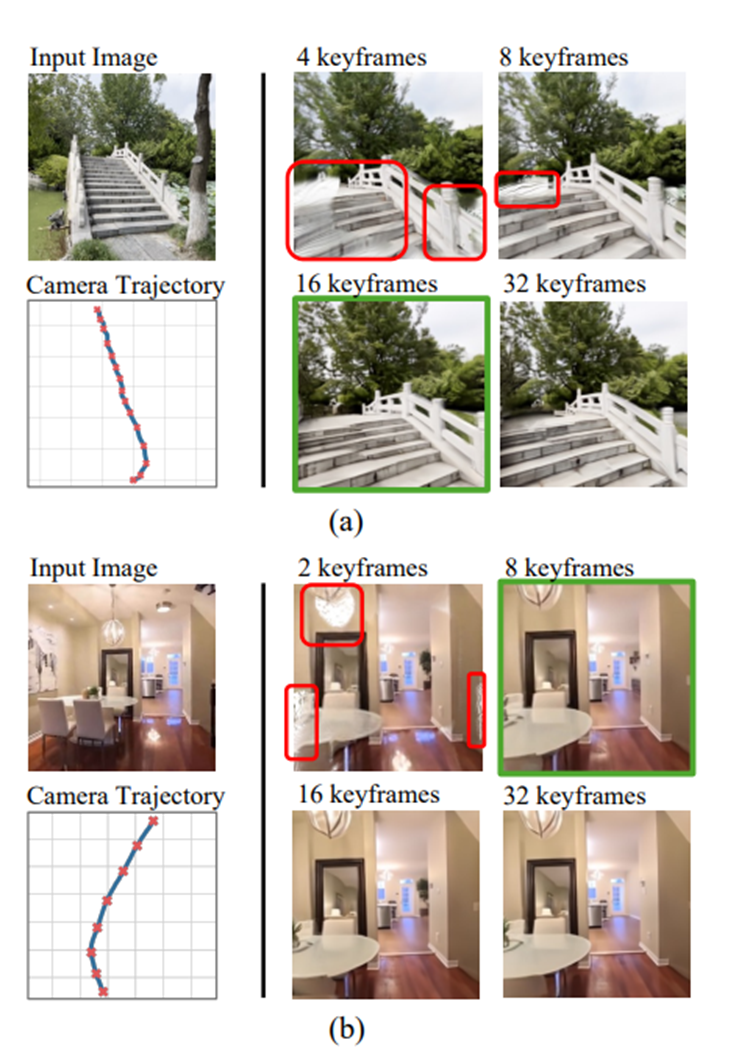
普通扩散模型生成低帧率的关键帧时,容易出现视角不连贯、细节对不上的问题,就像不同角度拍的照片不是同一个场景。
Srender采用渐进式训练,先让模型在高帧率视频上学习,熟悉帧之间的关联,再慢慢降低帧率,适应稀疏关键帧的生成。这样一来,哪怕关键帧之间视角差距大,也能保持一致性。
生成的时候还分两步走,先靠输入图像生成8个覆盖全程的关键帧,剩下的再以这些为参考补充,既保证了连贯,又控制了计算量。这就像你画素描,先勾勒出几个关键轮廓点,再慢慢细化,比盲目下笔要精准得多。
第三步:3D重建+快速渲染秒变稠密视频
这一步是Srender的效率核心,也是最惊艳的地方。它把生成的稀疏关键帧交给AnySplat模型,这个模型能快速把这些2D图片转换成3D场景模型,用的是3D高斯splatting技术。
你可以把这个3D模型想象成一个精细的实物模型,里面的每个细节都和真实场景对应。有了这个模型,之后要生成完整视频就简单了,沿着设定的相机轨迹,像用摄像机对着实物模型拍摄一样,逐帧渲染就行。
这个渲染过程特别快,因为不用再做复杂的神经网络运算,只是改变拍摄角度,就像你拿着手机围着一个小摆件录像,随手就能拍,根本不用等。
第四步:时间分块解决长视频漂移问题
长视频生成还有个痛点,就是时间久了画面容易“漂移”。比如生成20秒的视频,前面10秒场景还很稳定,后面10秒可能结构就变了,细节对不上,这是扩散模型的固有毛病。
登录/注册后继续阅读
立即登录/注册 >































