
我要认证
2026-01-16
平时用AI处理点短文本还行,一旦遇到长篇论文、大代码库或者几十万字的资料合集,是不是瞬间就卡壳了?
要么AI直接提示“文本太长处理不了”,要么就是前面的关键信息记不住,越往后回答越离谱,这就是大家常说的语境衰退问题。
哪怕是GPT-5这种顶尖模型,语境窗口也就27万多token,面对动辄上千万token的长文本,照样束手无策。
而麻省理工的CSAIL团队开发出了递归语言模型RLM,直接把有效处理长度拉满两个数量级,复杂任务性能还甩了传统模型几条街。

其实不是AI不想好好干活,主要是有两个绕不开的坑。首先是语境窗口的物理限制,就像我们的手机内存一样,AI一次能记住的文字是有限的,超过这个范围的内容根本加载不进去。
更头疼的是语境衰退,哪怕文本没超出窗口长度,AI对前面内容的记忆也会慢慢淡化。比如让它读一本百万字的小说,读到后面可能连主角名字都记混了,更别说分析复杂的人物关系和剧情逻辑。
这就像我们一口气读几百页书,前面的细节难免会模糊,而AI的“记忆力”比我们还差劲。
之前行业里也试过各种解决办法,比如给模型扩容,硬生生增加语境窗口,但这种方法又费钱又费算力,效果还不明显。
还有的是把长文本拆成小段总结,再把摘要拼起来,可这样很容易丢失关键细节,就像把一篇文章浓缩成一句话,很多重要信息都没了。
另外还有靠检索工具提取关键片段的,但这种方法太依赖关键词,稍微复杂点的语义理解就翻车。而RLM就是让AI主动和长文本互动,彻底改变了游戏规则。
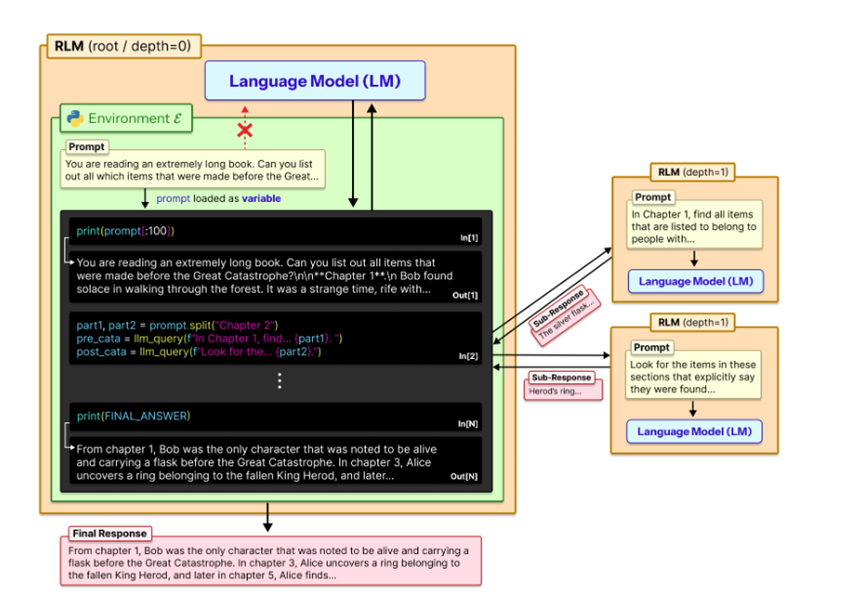
RLM其实没有改变AI本身的能力,而是换了一种和长文本打交道的方式。以前是把所有文本一股脑塞进AI的“脑子”里,现在是把长文本存放在一个专门的环境里,AI需要什么信息就自己去拿。
就像我们在电脑上打开一个大文件,不需要一次性读完,想看哪部分就翻到哪部分。
这个专门的环境就是Python的REPL编程环境,简单说就是一个能让AI写代码、执行代码的工具。RLM的工作流程特别好理解,分三步走就行。
第一步是初始化环境,把长文本当成一个变量存进REPL里,AI会先知道这个文本有多长、大概是什么结构,心里有个底。
第二步是AI主动探索文本,它会写一些简单的Python代码,比如用正则表达式找关键词,或者把文本按逻辑拆成小块,就像我们读长文章会先看目录、划重点一样,AI也会用代码筛选出有用的信息,忽略无关内容。
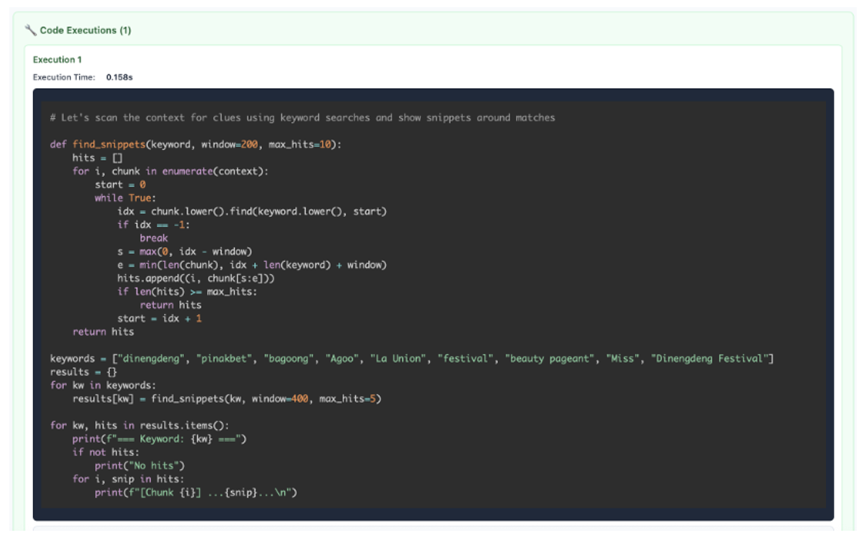
第三步是递归处理和聚合结果,AI把拆出来的小片段交给“分身”(也就是轻量化的自己)去处理,每个分身专注解决一个小问题,处理完之后把结果存起来,最后AI再把所有结果整合到一起,形成最终答案。
打个比方,这就像我们团队合作完成一个大项目,项目经理先把项目拆成一个个小任务,分给各个成员,成员完成后上报结果,项目经理最后汇总出成果。RLM就是靠这种方式,把无限长的文本拆解成有限的小任务,完美避开了语境窗口的限制。
RLM的核心模块主要有两个,就像汽车的发动机和变速箱一样,缺一不可。先说说REPL环境,它就像一个智能文件管理器,不仅能存长文本,还能让AI随时操作。
AI可以用代码查看文本的任意部分,比如只看前1000字或者某几个段落,还能通过代码做统计、找关键词,操作结果会实时反馈给AI,帮助它调整下一步的策略。
而且这个环境还自带接口,让AI能随时调用“分身”处理片段,不用额外配置工具。
再看递归调用机制,它就像一个智能调度员,把大任务拆成小任务,确保每个任务都在AI的处理能力范围内。
每个小任务都是独立的,不用等其他任务完成,后续还能并行处理,效率特别高。而且所有小任务的结果都能追溯,AI要是觉得某个结果不对,还能回头重新处理,不会出现信息丢失的情况。
值得一提的是,RLM不用专门训练新模型,现有具备代码能力的AI比如GPT-5、Qwen3-Coder都能用,零训练成本就能解锁长文本处理能力,这一点真的太良心了。
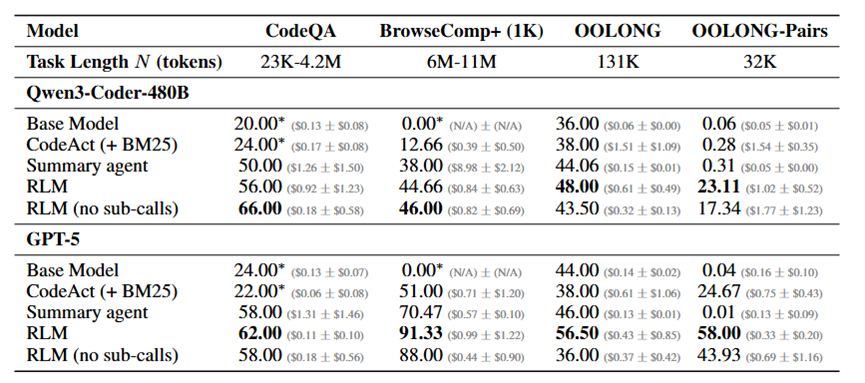
研究团队对RLM进行了大规模实验,从简单信息检索到复杂语义分析的各种场景,结果真的让人眼前一亮。
登录/注册后继续阅读
立即登录/注册 >































