
我要认证
2026-01-13
现在的机器人技术看着热闹,但真到了乱糟糟的真实环境里,大多还是有点笨手笨脚。
咱们人类瞥一眼就能知道东西碰一下会怎么动、会不会变形,可机器人得靠一堆复杂程序、反复调试才能完成简单操作。
但最近斯坦福大学和英伟达的团队联手推出了一个叫PointWorld的3D世界模型,直接把这个难题给破了。

你有没有想过,为什么家里的扫地机器人只能按固定路线跑,稍微地上多了个袜子就卡住?或者工厂里那些机械臂,换个零件就得工程师重新调半天?
根本原因就是,现在的机器人太死板了,它们不会像人一样,看一眼就知道推一下纸巾盒它会往哪滚、拉一下围巾它会怎么变形。而PointWorld要解决的,正是这个“空间直觉”难题。
简单来说,它是个能脑补物理的3D世界模型。你给它一张带深度信息的照片,就是普通RGB-D相机拍的那种。
它就能猜出,如果机器人伸手去推、拉、开、关,接下来几秒里场景里所有东西会怎么动。
重点来了,它不需要提前看过这个物体,也不用你手把手教它怎么做,更不用在仿真环境里反复训练。就像你第一次见到微波炉,也能大概知道门是往外拉还是往右推,PointWorld就在学这种“常识”。就是说0样本,就能完成自主学习。
那它是怎么做到的?核心思路特别聪明:把整个世界和机器人的动作,都转化成“点的流动”。
想象一下,你用激光扫描仪扫一遍房间,得到一堆密密麻麻的3D点,每个点代表一个位置。当机器人动起来时,这些点有的会移动、有的会变形。
PointWorld不去管物体叫什么、是什么材质,而是专注追踪这些点怎么流。这就避开了传统方法里必须先识别物体、再查物理参数的麻烦步骤。
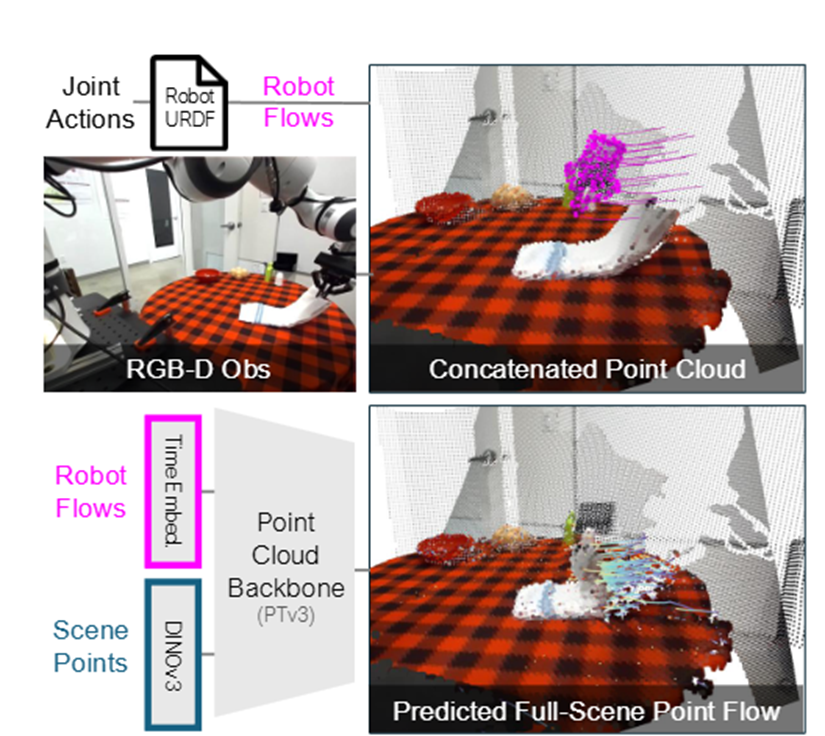
为了让不同机器人都能用这个模型,它连机器人动作也用3D点流来表示。和环境点流不一样,机器人的点流是通过自身的URDF文件预测出来的,相当于机器人在脑子里“预演”自己的动作轨迹。
就是根据机器人的关节配置,在初始时刻采样机器人表面的点,然后跟着关节运动轨迹,算出每个时间点这些点的位置。实际用的时候,为了省劲儿,只需要从夹持器上采样几百个点就够了。
这种方式在遮挡场景里特别好用,比如机器人抱着大箱子,接触的地方看不见,但通过预演的点流,依然能清楚知道怎么互动,保证动作准确。而且不管是单臂机器人、双臂机器人,甚至不同形状的夹持器,都能通用,大大降低了部署成本。
有了环境和动作的表示,接下来就是让模型预判结果了。PointWorld没搞复杂的定制架构,而是用了现在最先进的Point TransformerV3点云骨干网络,效率和效果都有保障。

它会把环境的点云和机器人的动作点流合并成一个点云,环境点的特征靠冻结的DINOv3编码器提取,机器人点则加上时间信息,然后让骨干网络处理,最后一次性预测出未来一段时间内每个点的位移。
这里有个特别聪明的设计,就是分块预测。它不像以前的模型那样一步一步慢慢算,而是一次预测未来10步、也就是1秒内的状态,不仅算得快(0.1秒就能出结果),而且时间一致性特别好,不会越算越偏。对比那些基于像素的模型,动不动就要算好几秒,这个速度简直是碾压级的。

训练的时候,PointWorld也有自己的小妙招。首先,机器人操控时只有少数点会动,大多数点都是静止的,如果平均用力训练,有效信号就被稀释了。所以它会重点关注那些运动的点,给这些点更高的权重,让训练更有针对性。
其次,真实世界的数据难免有噪声,模型会自己预测每个点的不确定性,对那些不靠谱的数据自动降低权重,还用上了Huber损失来减少异常值的影响。这样一来,模型训练得又稳又准,不会被噪声带偏。
再好的模型也得靠数据喂,PointWorld能这么厉害,背后是一个规模超大的3D交互数据集在撑着。
登录/注册后继续阅读
立即登录/注册 >































