
我要认证
2026-01-10
现在大家对虚拟世界的期待真的越来越高了,不管是玩游戏、搞仿真还是想在元宇宙里社交,都想要那种能随便逛、看着真实、还能自由互动的环境。
最近复旦大学、上海人工智能实验室和上海创新研究院开源了大世界模型Yume1.5。生成的世界不仅能靠文字控制,还能实时互动在里面游玩。
下面是生成的虚拟世界,赛博朋克、古文明、青山绿水能让你随意穿梭、游玩。
其实这些年视频生成技术已经进步不少了,像 Google的Lumiere、OpenAI的Sora,还有开源的 Stable Video Diffusion,生成的视频画质和连贯性都越来越棒。但真要用来做能无限探索的虚拟世界,就会发现一堆让人头疼的问题。
第一个问题就是不接地气。很多模型都是用游戏数据集训练的,生成的场景看着就很假,跟真实城市里的动态环境完全不是一回事。
游戏里的行人、车辆运动都有固定规律,可现实世界里的情况复杂多了,这些模型根本还原不出来,沉浸感一下就没了。
第二个是慢得让人抓狂。扩散模型本身计算量就大,生成一段视频要等好久。之前我了解过 Wan-2.1 生成一段标准视频要 611 秒,Matrix-Game 更夸张要 971 秒,这哪能叫实时互动啊,等视频生成完,探索的兴致都没了。
第三个是不够灵活。以前的模型要么靠键盘鼠标机械控制,要么只能按固定脚本走,没法用自然语言触发随机事件。想让虚拟世界里突然下场雨,或者有只猫跑过马路,根本做不到,玩一会儿就觉得无聊了。
这三个问题缠在一起,让虚拟世界一直停留在看着还行但不好玩的阶段,而Yume1.5直接解决了这三大难题。
长视频生成最头疼的就是,生成的画面越多,电脑要记的历史信息就越多,最后慢得像蜗牛。以前的办法要么是直接删掉早期的画面,导致后面生成的内容和前面脱节;要么是简单压缩一下,远处的场景就变得模糊不清。
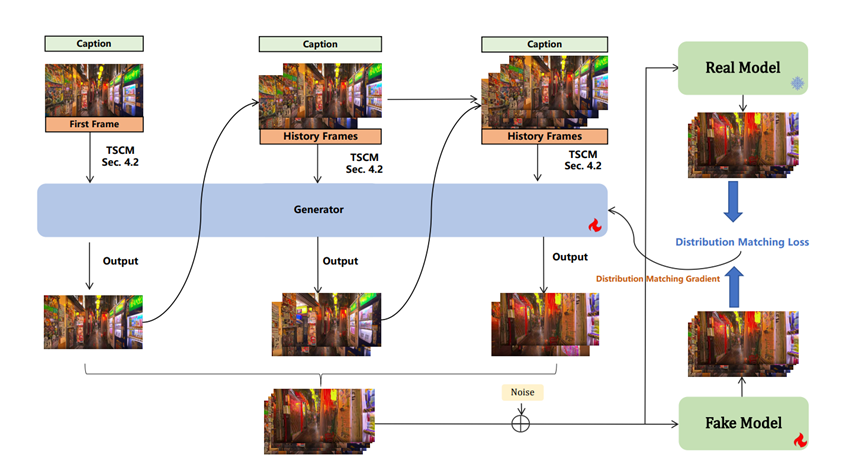
Yume1.5的 TSCM 建模就聪明多了,它给历史画面做了双重瘦身。一方面按时间远近调整压缩力度,刚生成的近景少压缩点,保留更多细节;

早一点的远景就多压缩点,但关键信息一点不丢,就像我们看远处的东西不用看清每一根草,知道大概轮廓就行。另一方面还会给画面的 “数据通道” 减肥,把没用的信息过滤掉,让电脑处理起来更快。
这么一套操作下来,不管生成多长的视频,电脑都能轻松应对。视频块数量超过 8 个以后,推理速度就稳定下来了,再也不会越生成越慢,而且指令响应也更精准了。
实时性是虚拟世界的命根子,要是操作一下等半天,谁还愿意玩。Yume1.5 用了两个办法来提速,效果直接拉满。
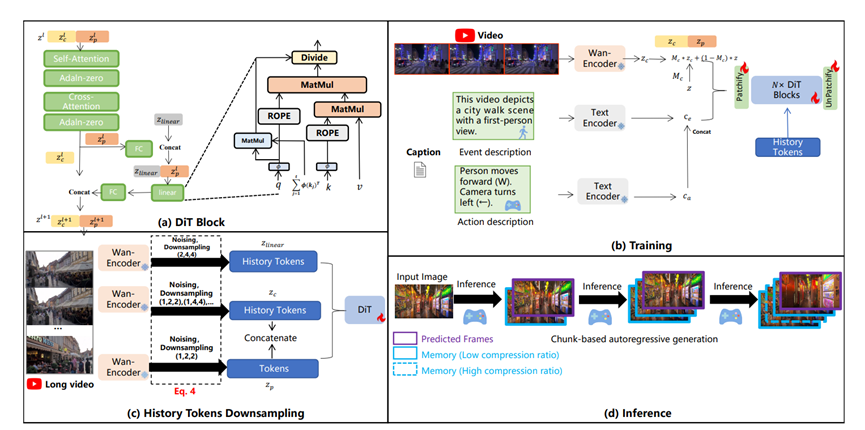
首先是 “蒸馏” 技术,就像老师把知识浓缩了教给学生,研究团队让一个 “学生模型” 跟着 “老师模型” 学,老师要 50 步才能完成的生成任务,学生 4 步就搞定了,而且效果还差不多。
它还用 TSCM 代替了传统的缓存方式,解决了快速生成时容易出错的问题。这么一来,Yume1.5在 540p 分辨率下每秒能生成 12 帧画面,完全能满足实时互动。
对比一下以前的模型,Wan-2.1 每秒才 0.016 帧,Matrix-Game更是只有 0.01 帧,这速度提升简直是革命性的。
以前的模型只能机械控制,Yume1.5 直接实现了文本自由,这才是最让人惊喜的地方。它会把我们输入的文字分成两部分来理解,一部分是场景和事件描述,比如 “阳光明媚的欧洲街道 行人悠闲散步”;另一部分是动作控制,比如 “向前向右移动”。
这样一来,我们既可以用键盘鼠标直接控制角色移动和相机视角,也可以输入文字指令让虚拟世界发生各种事情。
想让街道上突然出现洒水车,或者让一群鸽子飞过天空,只要打一句话就行,虚拟世界瞬间就变得生动有趣多了。
为了让模型更好地理解文字和画面的关系,研究团队还专门建了三个数据集,有真实世界的视频,有合成的高清素材,还有专门描述各种事件的样本,总共有 13 万多条数据。模型在这些数据上交替训练,既能还原真实场景,又能精准响应文本指令。
为了测试Yume1.5,研究团队进行了全面测试。在核心性能上,Yume1.5 生成一段 96 帧、分辨率 544×960 的视频只需要 8 秒,而 Wan-2.1 要 611秒,Matrix-Game 要 971 秒,Yume 之前的版本也要 572 秒。
在指令跟随能力上,Yume1.5 的得分达到 0.836,远超其他模型,基本上我们说什么,它就能做什么。
登录/注册后继续阅读
立即登录/注册 >































