
我要认证
2026-01-07
用AI编辑图像的小伙伴们都有一个感触,想让图片里的杯子挪个位置人物转个方向总得靠PS一点点抠图。如果用AI生成的结果总跑偏,背景直接变了样,原本简单的编辑需求最后搞得又费时间又闹心。
为了解决这个难题,香港中文大学和亚马逊AI团队联手开发了TALK2MOVE框架。
这也是全球首个靠强化学习驱动的扩散模型,图像编辑能力以76.67%准确率碾压了OpenAI的GPT-Image-1模型。

不是我吐槽,以前那些文本引导的编辑工具,用起来总感觉隔着一层。核心问题其实就四个,咱们一个个说。
首先是数据这块太矫情。想让模型学会编辑,得给它喂大量“原图+编辑后图”的配对数据。这种数据标注起来又费钱又费时间,尤其是涉及到物体移动、旋转的,真实世界里根本没那么多现成的对比样本。
靠视频或者3D模拟弄一点,数量少还场景单一,根本不够模型学透。
然后是精准度堪忧。以前的模型优化时总盯着像素级的误差,就像让你画画只看每个点的颜色对不对,却不管整体形状和位置。
结果就是,想移个杯子,要么移歪了,要么桌子边缘变模糊,要么杯子本身都变形了,完全达不到想要的效果。

再者是交互太不友好。有的工具得手动点控制点、拉坐标轴,没点专业知识根本玩不转。普通人想弄个“逆时针转90度”都得琢磨半天。
而纯文本驱动的模型又像没睡醒,根本听不懂这种细粒度的空间指令,经常答非所问。
最后是效率和效果难两全。有些模型想提升精准度,就把物体弄到3D空间里折腾,再转回到2D图像。
步骤一多,不仅慢,还容易出错,图像质量也下降。而那些快一点的模型,又总在一些没用的步骤上浪费算力,越用越着急。
而TALK2MOVE的团队很聪明,没走标注的老路,而是搞了个自动化的数据采集管道,三步就能生成大量高质量训练样本。
第一步,先让AI模型写场景描述,比如:“阳光照在窗边,有个男孩玩偶,旁边放着笔记本电脑和红色杯子。”然后用文本生成图像的工具,把这些描述变成实实在在的参考图片。这样一来,各种场景轻松就能搞定,比找真实图片方便多了。
第二步,是生成编辑指令。针对每张参考图,用视觉语言模型自动配上编辑要求,还制定了统一的模板:
平移就说清方向和目标位置,如“将杯子向左移动,从桌子上移到笔记本电脑上”;旋转就明确轴方向和角度,如“沿z轴逆时针旋转90度”;缩放就定好比例,如“放大2倍”。
这样指令又规范又好懂,模型学起来也有规律。
第三步,是为了让模型入门,合成少量高质量的配对数据:平移和旋转就用视频生成工具,模拟物体真实运动,再筛选出合格的样本;缩放就用图像编辑工具处理后筛选。
虽然数量不多,但足够让模型先掌握基础技能。整个过程完全不用人工插手,最后弄出了3200个平移样本、43个旋转样本和110个缩放样本,成本比以前低了90%还多,场景还特别丰富,这就为后续训练打下了好基础。
TALK2MOVE最核心创新是强化学习当老师,就是把模型训练变成了“闯关升级”,用强化学习的思路让它不断进步。
冷启动阶段,用前面合成的少量配对数据,给基础模型做个简单微调,就像让新手先熟悉下基本操作,不用搞复杂的全量训练,省时间还高效。
这个阶段主要是让模型知道:文本指令和物体变换之间有关系。比如听到“向左移”,就知道该往哪个方向动。
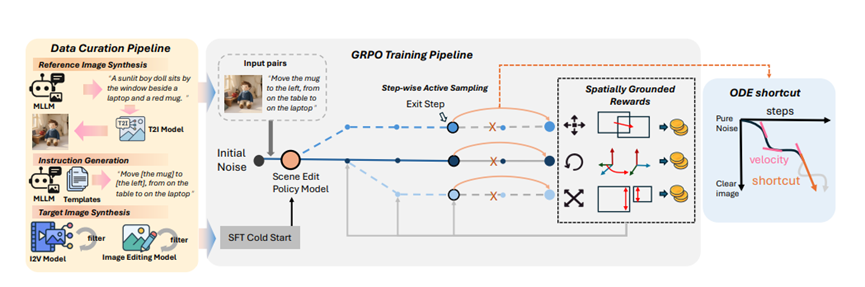
接下来就是强化学习的核心阶段。这里用到了GRPO框架,简单理解就是:让模型在生成图像的过程中,多尝试几种可能,然后根据结果好坏调整方向。
比如,让模型给同一个场景生成多个编辑结果,有的杯子移得准,有的移得偏。模型会对比这些结果,记住“移得准”的方法,下次就照着这个方向来。
这个过程不用再依赖配对数据,只要有参考图和文本指令就行。模型自己在尝试中学习,数据效率一下子提升了10倍,就算数据不多,也能练出好本事。
登录/注册后继续阅读
立即登录/注册 >































