
我要认证
2026-01-04
在VR/AR、游戏、数字人这些热门领域里,高质量3D人体动画一直是个绕不开的核心。以前做个逼真的3D人体动画可太难了——就算有昂贵的动作捕捉设备,专业动画师也得熬好几天,又费时间,又费技术。
最近,腾讯混元3D数字人团队刚开源的HY-Motion1.0,直接把这个技术拉到了新高度。
它是第一个把扩散Transformer相关模型做到十亿参数规模的文本到动作生成模型,不管是听话程度,还是生成动作的质量,都比现在开源的模型强太多。

虽然文本到运动生成技术发展了一阵子,但一直有几个老大难问题没解决。首先是生成的动作不真实,要么脚底下打滑,要么动作僵硬,完全不符合物理规律。
然后是模型听不懂复杂指令,你说个“慢慢抬起左手挥三下”,它可能只抬个手就完事了,细节根本对不上。
还有就是这个领域的模型一直没往大规模上做,不像图像生成那样越做越大,潜力没被挖出来;最后就是缺好数据,没有足够多、足够干净的运动数据,模型想学好都难。
案例展示
现在主流的模型还分成两派,各有各的毛病。一派是像MoMask和DART这样的小模型,虽然有点效果,但复杂动作根本搞不定,你让它生成个“边跑步边摆手”,它可能就只会机械地跑。
另一派是LoM和GoToZero这样靠大模型的,虽然能理解更多动作描述,但生成的动作总感觉不流畅,像机器人在动。而腾讯混元这次开源的HY-Motion1.0,用新的技术思路把这些问题都解决了。
想让模型表现好,高质量数据是基础,HY-Motion1.0能这么能打,首先得归功于它的数据集。团队找了三种不同的数据源,凑在一起搞出了一个又大又全的数据集。

先是从Hunyuan Video里挑了1200万条野生视频片段,这些视频都是真实场景下的,动作特别多样。然后用技术手段把视频里的人体动作提取出来,变成3D轨迹。
同时还收集了500小时的专业动作捕捉数据和3D动画资产,动作捕捉数据质量高但场景单一,3D动画资产是艺术家手工做的,动作特别标准但数量少还贵。这三种数据互补,既保证了动作质量,又有足够多的场景。
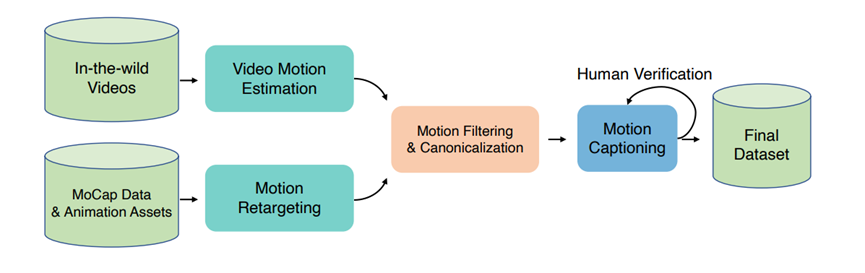
数据收集完还不算完,得好好处理一番。团队先把所有数据统一成一个标准的骨骼系统,不管原来是什么格式,都转换成一样的,这样模型学起来才方便。然后开始过滤低质量数据,重复的、动作奇怪的、关节动得不正常的,还有脚打滑的,全都删掉。
之后再把数据标准化,统一调成30帧每秒,超过12秒的动作就切成小段,每个动作的起始位置、朝向都统一好。
最后足足得到了3000小时的运动数据,其中400小时是精挑细选的高质量数据,这体量放在行业里也是相当能打的。
给动作加描述也很讲究,不是随便写写就行。视频来源的动作就用原视频,3D动作就先渲染成视频,然后用视觉语言模型自动生成描述,之后再人工检查修正,把错的改过来,漏的补上。
还会用大语言模型把描述统一格式,再生成几种不同的说法,让模型能适应更多表达方式。
为了让模型学得有条理,团队还把动作分了类,总共六大类,像移动、体育田径、日常活动这些,每大类下面再细分,最后足足有200多种具体动作,模型学起来就能分门别类,不容易混淆。
HY-Motion1.0的核心是HY-MotionDiT模型,简单来说就是你输入动作描述和想让动作持续多久,它就能输出对应的3D人体动作。
另外还有个独立的大语言模型模块,专门负责理解你的输入,比如你说“快速跑两步”,它能判断出这个动作大概要多久,还能把你的口语化描述转换成模型更容易理解的格式,相当于一个翻译加预判助手。
团队用了22个关节的骨骼定义,每个动作帧都包含了身体的位置、朝向、关节旋转这些信息,总共201个数据点。
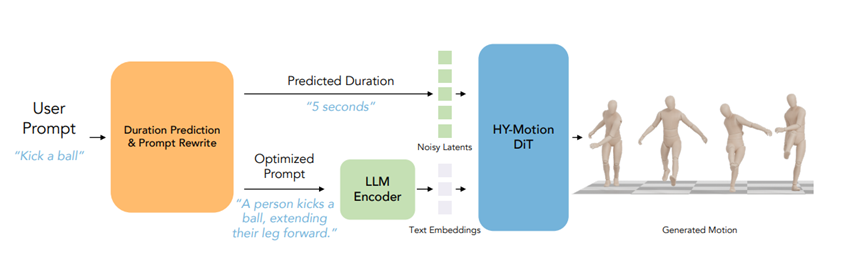
特别聪明的是,他们把旋转相关的信息用一种连续的6D格式表示,这种格式和动画制作流程很契合,不像以前有些表示方法,做出来的动作衔接不自然。
而且他们发现,去掉一些不必要的信息后,模型学得更快,所以最终的表示方案里就把那些冗余数据删掉了,效率更高。
HY-Motion1.0模型的架构很有特点,结合了双流和单流处理的优点。一开始动作数据和文本描述是分开处理的,各自有专门的处理模块,但中间会通过注意力机制互相交流,动作数据会主动去文本里找关键信息,
比如文本说“抬左手”,动作数据就会重点关注左臂相关的部分。处理到后面,两者就合并成一个序列,再通过专门的模块深度融合,这样模型就能更好地把文字和动作对应起来。
文本处理方面也下了功夫,用了两种方式提取文本信息。一种是用Qwen3-8B提取详细的语义,还解决了大语言模型只能单向理解的问题,让模型能全面把握文本意思。
另一种是用CLIP-L提取整体信息,再结合时间信息注入到模型里,让模型知道动作在不同时间点该怎么做。
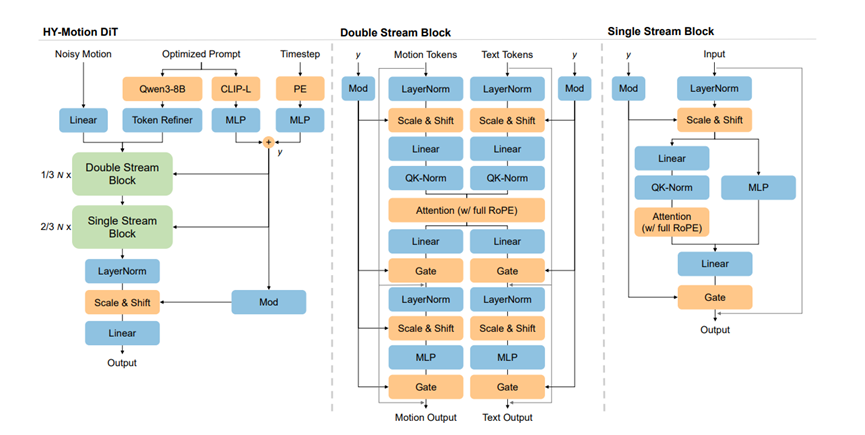
注意力机制和位置编码的设计也很用心。跨模态交互的时候,动作能看文本,但文本不会受动作的噪声影响,这样文本的意思就不会被打乱。
处理动作的时间序列时,模型只关注附近121帧的动作,因为人体动作大多是连贯的,最近的动作最有参考价值,这样既保证了效果又节省了计算资源。位置编码用了旋转位置嵌入,把文本和动作的位置信息统一处理,让模型能清楚知道哪个文字对应哪个动作片段。
训练目标方面,用了流匹配的方法,简单理解就是让模型学习从随机噪声慢慢变成真实动作的过程,就像雕刻家从一块石头慢慢雕出成品,这样训练出来的模型,生成的动作会更流畅自然。
HY-Motion1.0之所以这么强,训练方法功不可没,它用了三步走的策略,先打基础,再精修,最后对齐人类偏好,一步步把模型练到顶级水平。
第一步是大规模预训练,用的是那3000小时的完整数据集,这个阶段的目标是让模型先学会各种基本动作,建立起动作和文字的基本对应关系。就像小朋友学走路,先不管走得多标准,先学会各种移动姿势再说。
训练过程中,模型的损失函数下降得很快,说明它很快就掌握了人体运动的基本规律,能响应各种动作描述。
但因为数据里有一些质量不高的噪声数据,这个阶段生成的动作虽然语义对得上,但会有一些小问题,比如轻微的抖动或者脚滑,不过这都在预期之内,这个阶段主要是打基础,把各种动作的大致框架学会。
登录/注册后继续阅读
立即登录/注册 >































