
我要认证
2025-12-30
在AI圈摸爬滚打的朋友都知道,大模型现在是越来越强,但推理速度这块一直是个老大难。咱们平时用的ChatGPT、豆包、通义千问这些,背后都是自回归生成在干活。
简单说就是一个字一个字往外蹦,虽然说出来的话连贯又靠谱,但架不住慢啊,尤其是处理长文本或者复杂任务的时候,等半天才能拿到结果,硬件的并行能力也完全没发挥出来。
而另一派扩散语言模型本来想解决这个问题,能一下子处理好多个被遮住的词,理论上速度应该快很多,但实际用起来却让人失望。
为啥呢?因为它得同时看前后的内容,这就导致之前算好的结果没法存起来复用,越往后算越费劲,最后速度还不如优化过的自回归模型。
为了解决这一大难题,国内AI天团腾讯微信AI联合北大、清华重磅开源了WeDLM,不用改太多现有技术,就能让扩散模型和自回归模型的优势结合起来,复杂任务能快3倍,简单任务甚至能快10倍,关键是生成质量还没降。

WeDLM的厉害之处不在于搞了多少花里胡哨的新东西,而是把现有技术的潜力发挥到了极致。
扩散模型之前之所以要互相打听,是因为被遮住的词没法看到所有已知的信息。WeDLM想了个简单办法,把所有已知的词都挪到前面,被遮住的词放在后面,这样后面的词不用回头看,就能直接拿到所有需要的信息。
就像开会的时候,把所有知道情况的人都安排在前排,后面提问的人不用到处找人打听,直接听前排的人说就行。
而且它还保留了每个词原本的位置信息,不会因为物理位置挪了就搞混逻辑顺序,这一点真的太巧妙了,既解决了信息获取的问题,又没破坏原有的逻辑。
很多模型训练的时候表现很好,一到实际用就拉胯,主要是训练场景和实际场景不一样。WeDLM就搞了两条线来训练,一条线是干净的原始数据,另一条线是被遮住的训练数据。
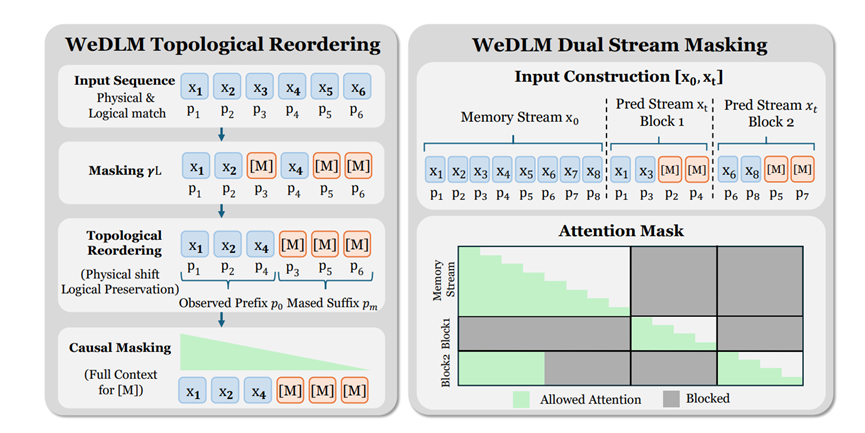
训练的时候,模型只能参考干净的数据来预测被遮住的部分,不能依赖之前预测出来的、可能不准确的内容。
这就像平时练习做题的时候,只能看课本上的知识点,不能看自己之前蒙对的答案,这样练出来的本事才扎实,到实际应用的时候才不会掉链子。
之前的块级模型得等一整块都处理完才能输出结果,中间会有很多等待时间。WeDLM就不一样了,它维护一个固定大小的窗口,里面既有已经处理好的词,也有等待处理的被遮住的位置。
每处理完一部分,就把最前面确定好的词输出出去,同时再补充新的被遮住的位置进来,一直保持窗口满负荷工作。
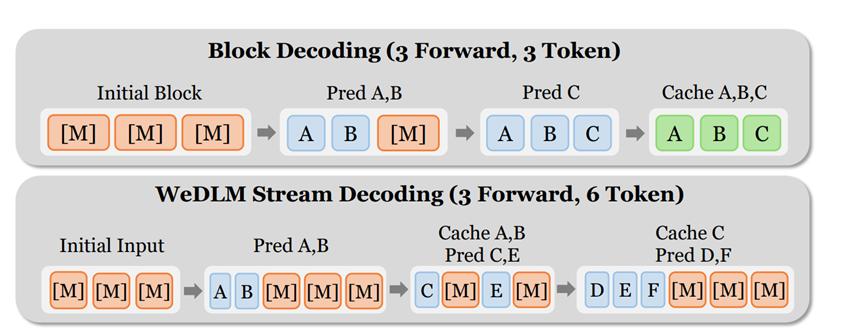
这就像工厂的流水线,不用等一批产品全做完再往下走,做完一个就送走一个,新的原材料马上补进来,效率自然就高了。
而且它还会优先处理前面的内容,保证输出的顺序是对的,不会出现后面的词先出来的情况。
最让人惊喜的是,WeDLM部署起来一点都不复杂,完全兼容现在主流的推理框架。
不用改任何内核代码,直接就能用vLLM、FlashAttention这些优化工具,对于企业来说,不用重新搭建基础设施就能升级,省了不少事。
而且它对参数也不挑剔,比如块大小不管设成4、8还是32,性能都差不多,不用花大量时间调参。开发者拿到代码后,基于自己现有的AR模型就能快速适配,不用从头训练,门槛真的很低。
登录/注册后继续阅读
立即登录/注册 >































