
我要认证
2025-12-28
2025年末,字节跳动智能创作团队扔出了个重磅技术DreaMontage,直接把AI视频生成的玩法给升级了。
之前想做个专业的一镜到底视频,要么得砸大价钱搭场景、请团队,要么用现有AI模型做出来全是拼接痕迹,画面跳来跳去根本没法看。
现在有了这个框架,不管是零散的图片、短视频片段,都能轻松变成无缝衔接的长镜头视频,影视、广告、游戏这些行业估计要迎来大变化了。

话不多说,咱直接先看下效果。
零帧起手一键生成1分钟的超长视频镜头,相当的丝滑震撼。
喜欢看电影的朋友肯定知道,一镜到底的长镜头有多惊艳,那种沉浸式的连贯感,普通剪辑根本比不了。但现实里拍这种镜头也太折腾了,场景、调度、后期哪样都得花大价钱,还受物理空间限制,想拍点天马行空的画面基本不可能。
后来AI视频生成火了,像Sora、Kling这些模型确实能做视频,但用起来总觉得不得劲。
它们大多只能靠开头和结尾两帧来生成,中间的内容全靠模型瞎猜,经常出现画面断层,前一秒还是这个场景,下一秒突然跳转到别的地方,特别生硬。
而且想在视频中间加个特定画面、调整下节奏,根本做不到,完全没有创作的掌控感。
从技术角度说,不是这些模型不想做好,而是有三个绕不开的难题。一是中间的参考画面没法被模型精准识别,就像看书少了关键页码,自然接不上;二是不同画面之间的风格、内容差异太大,模型不知道怎么自然过渡;三是长视频生成特别吃电脑性能,普通设备根本扛不住。
字节跳动这次就是瞄准这些痛点,才搞出了DreaMontage。说直白点,就是想让咱们普通人也能拥有专业导演的创作能力,不用再被成本和技术门槛卡住。
DreaMontage本质上是在DiT架构上做了优化,核心就是三个关键点,咱们用大白话慢慢说。
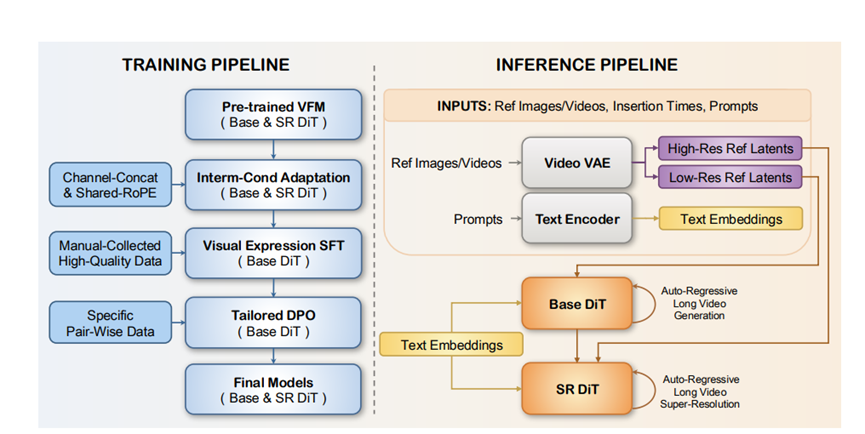
1.中间条件适配想加啥画面都能精准插入
这个功能就像给视频加了个精准导航,不管你想在哪个时间点插入图片或者短视频片段,模型都能精准接住,还不影响整体流畅度。
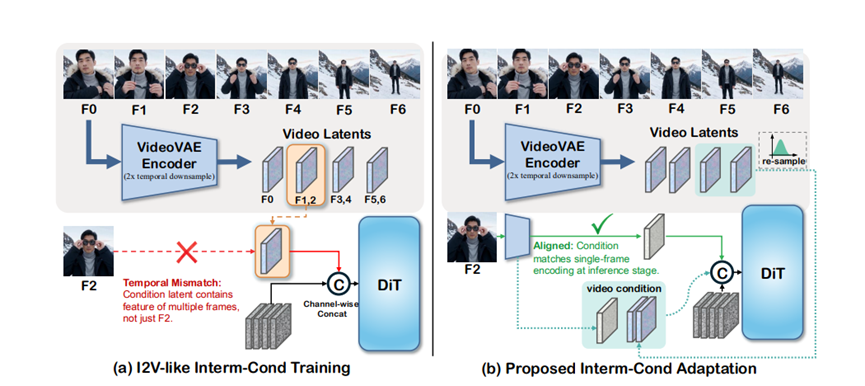
基础模型部分,它是把参考画面的核心信息和生成视频的信息拼在一起,有点像拼图时先找到关键拼块。不过一开始会出现画面对不上的问题,就像你想插的是第5秒的画面,结果模型接到了第4-6秒的信息。
后来团队筛选了一批优质的一镜到底视频来训练,慢慢就解决了这个错位问题,而且没增加多少计算成本,普通电脑也能跑。
超分模型更有意思,专门解决高清视频的闪烁、色彩跑偏问题。它搞了个Shared-RoPE策略,简单说就是让参考画面和生成画面“对齐步调”,参考画面的关键信息不仅拼进去,还保持和目标画面一致的定位,这样放大到高清后,画面也不会忽明忽暗、颜色乱飘。
如果插入的是视频片段,就只对开头一帧做这个处理,既保证效果又不费劲儿。
训练的时候也很讲究,不是随便找视频来练。团队先筛掉多镜头的视频,只留一镜到底的,再挑那些视觉变化大、运动感强、画面好看的,还会给每个动作做详细标注。
训练时把每个动作的关键帧、随机中间帧都当参考,视频片段则是重新处理后再用,这样模型就能熟练应对各种插入需求了。
2.视觉表达优化画面和动作都更自然
光能精准插入还不够,生成的画面得有电影感,动作还得符合常理才行。DreaMontage用了两步优化,一步步把效果拉满。
第一步是视觉表达SFT,相当于给模型做专项训练。团队先找出模型之前做得不好的场景,比如镜头运动、视觉特效、体育场景这些,再细分出具体类别,像推镜、第一人称视角、动物变形这些。
然后收集了一批高质量视频,专门针对这些场景训练模型,而且这些视频时长更长,最多能到20秒,转场也更丝滑。
训练完之后效果很明显,模型生成的动作更带感了,也更能听懂指令。比如让它做一个“缓慢推镜+人物转身”的效果,之前可能动作僵硬、镜头乱晃,现在就流畅多了。
数据也能证明,运动效果的评分提升了24.58%,指令理解能力也涨了5.93%,整体观感好了不少。
第二步是定制化DPO,主要解决两个头疼问题:画面突然跳转和动作不合理。比如有时候模型会突然从草原切到城市,或者人物手臂扭成不可能的角度。
针对画面跳转,团队先训练了一个专门的识别模型,能区分视频有没有生硬跳转,再让模型生成一批视频,挑出跳转严重和流畅的做对比训练,让模型知道哪种效果更好。
针对动作不合理,就专门收集常见的问题动作,比如跑步姿势不对、车辆行驶轨迹奇怪,再通过人工标注筛选出好的案例来训练。
这么一优化,画面跳转的问题改善了12.59%,动作不合理的情况也好转了13.44%,生成的视频终于看着正常了。
3.分段自回归生成长视频也能轻松搞定
一镜到底视频往往需要很长时间,但之前的模型生成几分钟的视频就会卡顿、画面变差。DreaMontage的分段生成策略,完美解决了这个问题。
它的思路很简单,就像写文章先分段写,再整合起来。模型会把长视频分成一个个小片段,每个片段生成时都参考上一个片段的结尾,这样衔接起来就不会断层。而且分段是在latent空间进行的,不是直接拼画面,过渡会更自然。
举个例子,想生成60秒的视频,模型可能分成4个15秒的片段,第一个片段生成完,第二个片段就照着第一个的结尾来延续,以此类推。最后再把这些片段融合起来,就成了完整的长视频。
登录/注册后继续阅读
立即登录/注册 >































