
我要认证
2025-12-27
知名开源平台LiquidAl开源了最新纯强化学习的小模型LFM2-2.6B-Exp。
在指令遵循、知识问答和数学基准测试上超过目前市面上所有的同类模型,特别是在LFBench基准测试中的得分,甚至超过了规模比它大263倍的DeepSeekR1-0528成为目前最强开源小模型。

对于LFM2-2.6B-Exp超强性能,网友表示,30 亿参数的模型击败 263 倍规模的大模型,这简直疯了,但也在某种程度上证明,当更聪明的训练方法就能奏效时,我们一直在把算力浪费在更大的模型上。
在指令遵循任务上击败参数规模是其200倍的大模型,这对一个小模型来说是效率的惊人展示。
参数规模正式沦为 “虚荣指标”。智能密度才是新的王道。
击败参数规模是其 263 倍的模型,证明现代 AI 的关键在于架构效率,而不只是把更多算力砸向问题。我们终于从蛮力参数堆砌迈向了精准工程。
哇塞,一个 30 亿参数的模型,性能居然超过了比它大263倍的模型?这简直是强化学习的黑魔法,太离谱了!
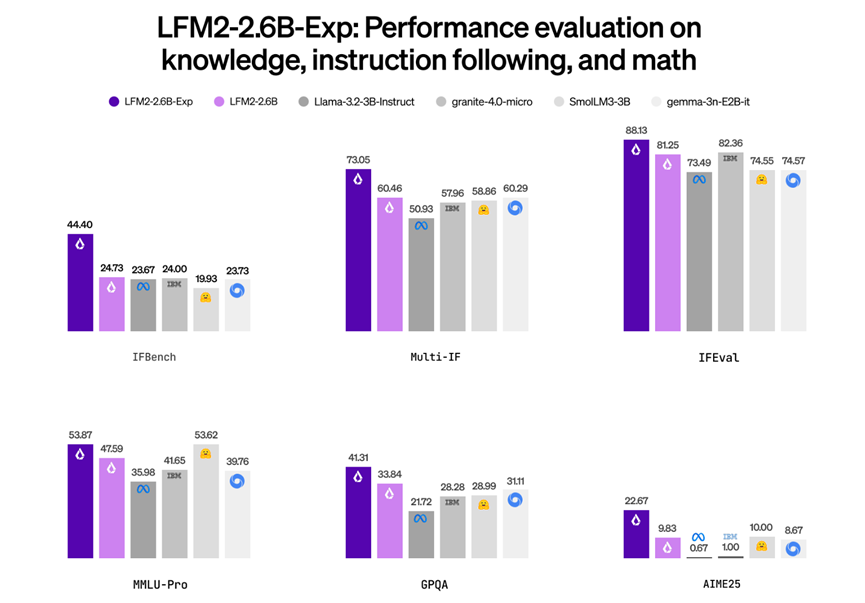
LiquidAl对LFM2-2.6B-Exp做了详细的性能测试,覆盖了指令遵循、知识、数学好几个领域,咱们直接看数据就知道有多能打。
在IFBench上,LFM2-2.6B-Exp拿到了73.05的高分,比同系列的LFM2-2.6B高出一大截,更是把Llama-3.2-3B-Instruct、granite-4.0-micro这些同级别模型甩在身后。MuLti-IF测试里它冲到了88.13分,指令理解和执行能力直接拉满。
知识类测试也不弱,MMLU-Pro拿到41.31分,比Llama-3.2-3B-Instruct的21.72分翻了快一倍;GPQA测试里更是从LFM2-2.6B的9.83分暴涨到22.67分,知识储备明显扎实了很多。
IFEval测试里53.87分的表现,也比同参数级模型高出不少,足以见得它在指令遵循上的硬实力。
LFM2-2.6B-Exp参数小性能强,所以特别适合做智能体任务、数据提取、检索增强生成、创意写作还有多轮对话,日常用起来灵活又高效。
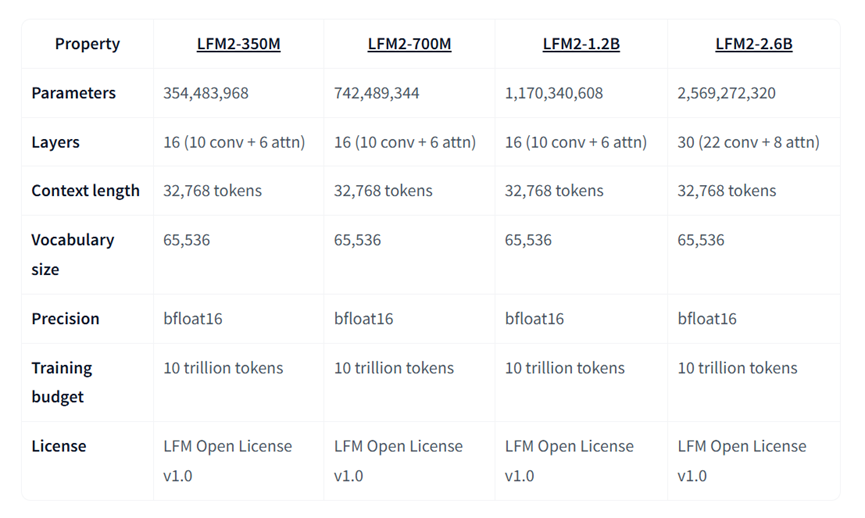
顺便跟大家梳理下LFM2全系列的关键信息,方便大家根据需求选择。不管是3.5亿、7亿、12亿还是30亿参数的版本,上下文长度都能到32768个token,处理长文本完全没问题,词汇表大小也都是65536,支持英语、阿拉伯语、中文等8种语言,通用性很强。
不同的是网络层数,小参数版本是16层,30亿参数的LFM2-2.6B加到了30层,卷积层和注意力层的数量也相应增加,性能自然更上一层楼。
而且全系列都用了bfloat16精度,训练数据量都是10万亿个token,基础打得很牢,还都是LFM开源许可证v1.0,使用起来也放心。
官方给了推荐的生成参数配置,照着设基本不会出错。温度调到0.3,既能保证输出稳定又不会太死板;min_p设为0.15,能过滤掉那些低概率的无效令牌;
重复惩罚系数1.05,刚好能减少重复内容,又不会影响表达流畅度。按这个配置来,生成的内容质量会高很多。
不管你是想快速体验还是深入使用,官方给出了三种运行方式,操作起来都不复杂。
1.Transformers框架:这是最常用的方式,先安装HuggingFace的transformers库,要v4.55及以上版本,用pip命令就能装。然后加载模型和分词器,设置好生成参数,输入问题就能得到回复。
登录/注册后继续阅读
立即登录/注册 >































