
我要认证
2025-12-26
在VR、沉浸式通话还有创意内容制作这些领域,有个老大难问题一直没解决。就靠一张图,想生成能看很久、而且画面里的3D结构还不跑偏的视频,之前真的太难了。
要么是遇到遮挡就露馅,复杂点的相机移动轨迹根本扛不住;要么是越生成误差越大,到后面画面直接崩掉。
为了解决这些难题,新加坡国立大学等研究团队联合开发了WorldWarp的框架把3D结构当骨架,再用2D生成模型做皮肤细化,直接把这个技术瓶颈给破了。
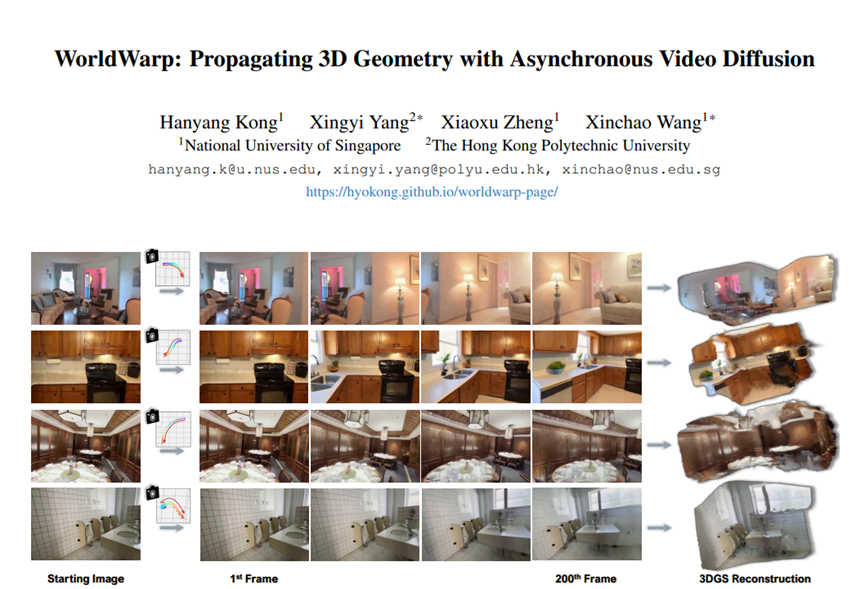
咱们先看看WorldWarp生成的效果。
怎么样效果还不错吧,是不是很稳。
咱首先得明白一个核心概念,新颖视图合成,简单说就是让电脑根据现有图像,生成从没见过的视角画面。
这事儿分两种,一种是视图插值,就是在已有相机角度范围内生成新画面,这活儿现在技术挺成熟了,哪怕原图少点、有遮挡也能应付。
另一种是视图外推,这就难了,得生成远超原图范围的连续画面,相当于让电脑凭空创造新内容,还要保持3D结构一致,比如从正面视角一直转到背面,物体的位置、大小、遮挡关系都不能乱。
这就像让画家只看一张人物照片,画出绕着人物走一圈的动画,还得保证人物的五官、肢体比例全程不歪,难度可想而知。
之前行业里有两种主流解法,但都有坑。一种是给相机参数做编码,把相机怎么动的变成模型能懂的信号,但这方法特别依赖训练数据,遇到没见过的相机角度就歇菜,而且没法告诉模型画面里的3D结构到底是啥。
另一种是直接建3D模型当参考,比如点云、网格这些,但初始建模的误差会越传越大,后面画面全是bug,而且特别费算力。

再加上视频生成本身的问题,有的模型是逐帧按顺序生成,没法利用未来视角的信息;有的能并行处理,但又搞不定相机控制。所以之前想找个既能保证3D不跑偏,又能让画面好看、还能生成很久的框架,真的比登天还难。
而WorldWarp的技术亮点就是打破了之前的思维定式,不纠结于单一的生成方式,而是用三个核心模块配合,逐块生成视频,既保证了3D结构不歪,又让画面细节拉满。
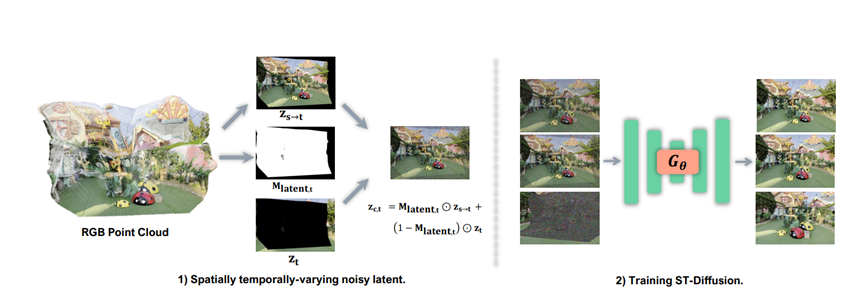
ST-Diff是整个框架的核心大脑,专门解决补空白、修歪处的问题。它跟之前那些按顺序生成的模型不一样,能同时参考前后画面的信息,就像有上帝视角,知道哪里该补、哪里该修。
它的关键技巧是空时变噪声调度,听着玄乎,其实特别好理解。
就像给画面不同区域开不同强度的美颜:已经有3D结构参考的区域,比如从之前画面扭曲过来的部分,就少加点噪声,只做轻微修正,保证结构不变;而那些遮挡住的空白区域,就加满噪声,让模型自由发挥生成新内容。
举个例子,你拍了一张房间门口的照片,想生成绕着房间走一圈的视频。当相机转到门后面时,门挡住的区域就是空白,ST-Diff就会自动生成门后的场景;
而门框、墙壁这些已有结构的部分,只会做细节优化,不会让门框突然变歪、墙壁凹凸不平。这样一来,补出来的内容既合理,又不会破坏整体3D结构。
之前的3D模型都是固定的,一开始建错了,后面越生成越歪。WorldWarp就不一样,它搞了个动态3D缓存,用的是3D高斯Splatting技术,简单说就是每生成一段视频,就重新优化一次3D模型。
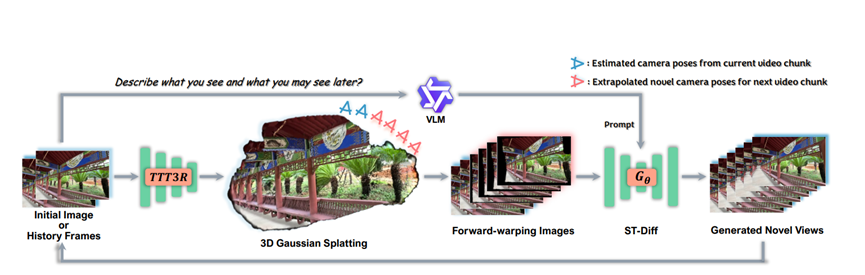
比如生成第一段49帧视频后,模型会根据这49帧的画面,重新调整3D结构,修正之前的小误差;再用优化后的3D模型生成下一段,相当于每一步都在校准骨架。而且这个优化过程特别快,几百步迭代就搞定,不会额外增加多少算力。
这就像盖房子,不是一次性把骨架搭好就不管了,而是每盖一层就检查一下,调整一下骨架的垂直度、牢固度,后面盖得越高,反而越稳,从根源上避免了误差越传越大的问题。
WorldWarp不是一口气生成完整视频,而是像搭积木一样,一块一块来,每块49帧,生成完一块就用它当基础,再写下一块。
为了不让块与块之间脱节,它还设置了5帧的重叠区域,就像拼图的咬合处,保证前后画面过渡自然。如果要生成的视角超出了原图范围,它会根据之前的相机移动速度,自动推算接下来的移动轨迹,不会突然出现视角跳跃。
登录/注册后继续阅读
立即登录/注册 >































