
我要认证
2025-12-25
过去几年,人工智能模型的飞速进步几乎全靠“大力出奇迹”,模型参数越来越大,训练数据快速增长,算力需求也很高。
AI大模型能写诗、编程、推理,看起来无所不能。但只要稍微追问一句,它能在使用的过程中持续学习吗?
学了新东西会不会把旧知识忘光?面对一本10万页的法律全集,能准确找到第84231页那个关键条款吗?答案往往令人失望。
这些不是细节问题,而是当前深度学习范式的结构性缺陷。模型一旦训练完成,就被“冻结”了;它的记忆是扁平的、临时的,其优化过程像一个黑箱司机,只顾踩油门刹车,从不反思自己开得对不对。

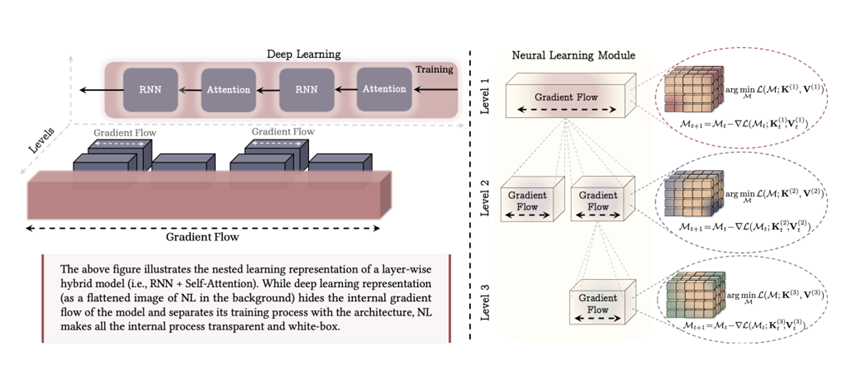
而谷歌最新发布在全球顶级AI大会NeurIPS上的最新研究“嵌套学习”(NestedLearning),正是要从根本上扭转这一局面。它不是又一个更大的模型,也不是一种调参技巧,而是把整个AI模型看作一个由多层、多节奏、可协同演化的子系统组成的有机体。
就像人脑那样,有的部分反应极快,捕捉当下细节;有的部分缓慢沉淀,构筑长期认知;有的负责执行,有的负责监督,有的甚至能修改自己的规则。
咱们先拆解一个难题,为什么现有模型越训越笨?拿Transformer举例,它像一个超速复印机:所有token一次性送进去,注意力机制快速算相关性,MLP层做非线性变换,完事。但复印机再快,也干不了边读边总结、边总结边修正的活。
因为没有真正的时间层次,所有计算在同一时钟节拍下完成;它的记忆只有两种:注意力窗口里那几千个词(短时),和MLP权重里固化住的统计规律(长时),中间一片空白。
学新知识?只能粗暴覆盖旧权重,灾难性遗忘是必然结果。这就像让一个人用同一本笔记本同时记会议纪要、写周报、存通讯录,不乱才怪!

谷歌提出的嵌套学习架构很巧妙,把整个模型拆成一套“俄罗斯套娃式”的学习系统,每个娃娃负责一个时间尺度。最外层娃娃可能每处理10万个token才更新一次,存的是世界常识:比如法律条文通常按章节编号;中间层娃娃每读完一段更新,记的是“本章主题是知识产权”;最内层娃娃每看一个词就动,盯的是“当前句子主语是‘申请人’”。
它们不是孤立的,外层娃娃的初始状态,其实是从内层娃娃的历史表现里“蒸馏”出来的;内层娃娃发现矛盾时,还能向上层打报告,触发更高层级的修正。
也可以把整个架构看成是一支交响乐团,低音提琴稳住节奏(低频知识),小提琴灵活应变(高频细节),指挥家(顶层调度)根据乐谱动态调平衡。反观传统大模型,只有一排电子节拍器在响。
最颠覆的认知在于,连优化器都是记忆体。过去我们觉得Adam就是个调参工具。嵌套学习则认为,Adam本质是个两级记忆压缩器。它的第一动量m在记梯度往哪走,是短期趋势;第二动量v在记梯度抖不抖,是不确定性估计;合起来就是在为每个参数建一个微型贝叶斯预测器。
它不是在盲目下降,而是在说:根据过去100步的走势,下一步大概率该往这儿走多少。顺着这思路,搞出了Delta梯度下降(DGD),更新权重时,不仅看当前梯度,还看当前输入x和当前权重w的状态组合。
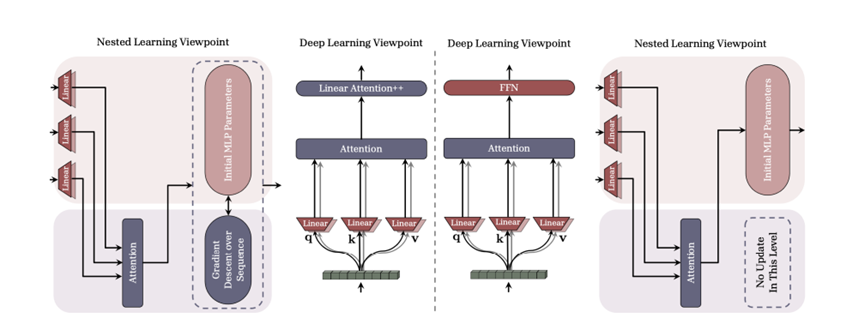
为什么重要?因为真实数据有强依赖,看到巴黎是后面大概率接法国首都,这个关联性藏在x和w的联合分布里,而不是单点梯度中。DGD等于让优化器从死记硬背错题本升级为理解错题背后的逻辑。
为了验证嵌套学习的有效性,谷歌研究团队设计了名为Hope的神经学习模块,整合了自修改Titans和连续记忆系统,形成统一强大的模型架构。
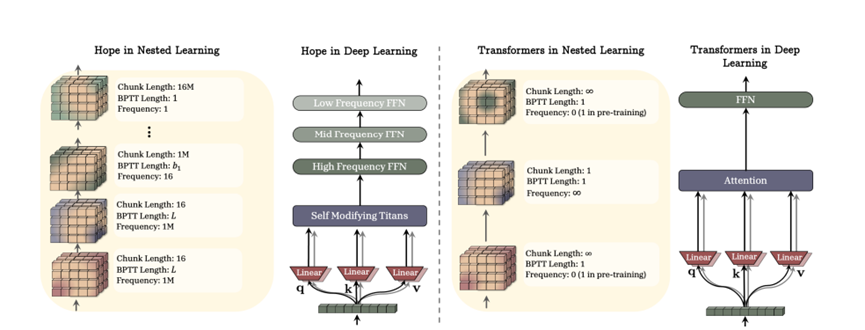
Hope的工作流程很清晰:首先,输入通过自修改Titans生成键、值、查询、学习率、遗忘门等组件的动态值;接着,自修改Titans的各组件通过Delta梯度下降更新,实现上下文自适应;最后,Titans的输出传入连续记忆系统,经过多频率MLP块处理,生成最终输出。
研究团队还提出了Hope-Attention变体,用Transformer的全局软注意力机制替代自修改Titans,以此验证连续记忆系统在传统架构上的适配性。
为了全面评估嵌套学习和Hope架构的性能,研究团队在六大类任务上进行了大规模实验,涵盖持续学习、长上下文理解、语言建模、常识推理、上下文回忆和语言识别等核心场景,对比的基线模型包括Transformer及其变体、现代循环模型、深度记忆模块等当前最先进的架构。
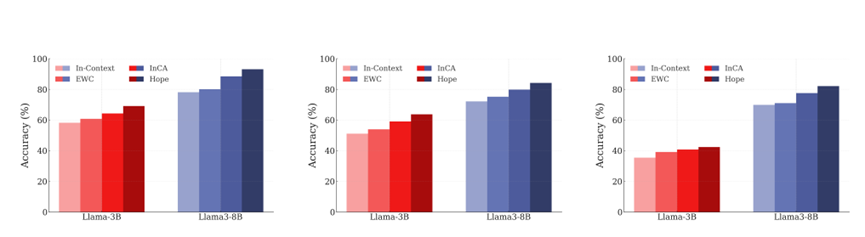
持续学习则是嵌套学习的核心目标之一,研究团队在CLINC、Banking、DBpedia三类文本分类数据集上进行了类增量学习测试,还设计了新型语言持续翻译任务。
在类增量学习中,以Llama3-8B和Llama-3B为基础模型,Hope通过将MLP块改造为多频率连续记忆系统,持续预训练15Btokens后,在三类数据集上的准确率都超过了传统的上下文学习、弹性权重巩固和外部学习者辅助的持续学习方法,充分验证了连续记忆系统在知识积累和抗遗忘方面的优势。
登录/注册后继续阅读
立即登录/注册 >































