
我要认证
2025-12-24
现在 AI 生成内容真的太火了,不管是拍图片、剪视频,还是写歌做音效,AI 都能插一手。但有个痛点一直没解决好,就是给一首完整的歌自动做 MV。
之前那些工具要么只能出几个零散的短片段,要么画面和歌词、节拍完全对不上,角色还一会一个样,看着特别出戏。
最近,北京邮电大学、南京大学还有伦敦玛丽女王大学的团队联手开源了一个突破性项目 AutoMV。仅需10—20美元,大约消耗30分钟的时间,就能制作一整部连贯又专业的MV。
下面这个就是由AI生成的MV,相当惊艳了。
咱们先聊聊行业里的老问题。首先是传统 MV 制作太烧钱了,一首稍微像样点的 MV,制作成本就得过万美元,还得花几十上百个小时,从写剧本到拍再到剪,每个环节都得专业人来,普通人根本扛不住。
再看那些 AI 工具,比如 Revid.ai、OpenArt这些,看着能生成视频,但对付完整歌曲就露怯了。要么是镜头碎得厉害,没有完整的故事线;要么是画面和音乐完全脱节,歌词唱着 开心,画面却一片伤感;
最让人难受的是角色老变,上一个镜头是短发,下一个就成长发了,有时候连性别都能变。而且没有个靠谱的评价标准,到底好不好看、对不对味,全凭感觉说。
AutoMV就是冲着这些问题来的,它把音乐解析、剧本创作、视频生成、质量检查捏成了一个完整的流程,就像一个全自动的 MV 制片厂,不用人操心就能出成品。
AutoMV的核心就是四个模块协同工作,一步接着一步,把一首歌从音频变成视频,逻辑特别清晰,咱们一个个说。
第一步,给音乐做全身扫描,提取所有关键信息。
要让画面跟着音乐走,首先得把音乐摸透。AutoMV 就像个音乐分析师,用专门的工具把歌曲拆解开。它能识别歌曲的风格、情绪,比如是摇滚还是抒情,是开心还是伤感,还能猜出歌手的性别,这些信息能帮着定 MV 的整体调性。
然后它会把歌曲分成前奏、主歌、副歌、间奏这些部分,就像给电影分章节一样,每个章节对应不同的画面。
最关键的是,它能把人声和伴奏分开,这样后续做唇同步的时候更精准,还能把歌词准确地转录出来,并且标上时间戳,比如哪句歌词在第几秒开始唱,确保画面和歌词对上。
简单说,这一步就是把一首抽象的歌,变成一堆看得见、用得上的 “素材包”,为后续创作打基础。
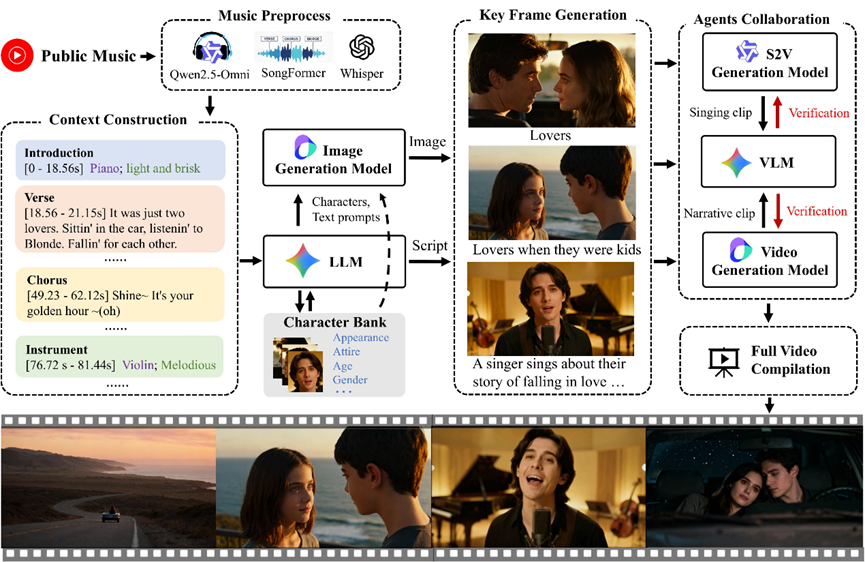
第二步,AI当编剧+导演,给MV画好蓝图
有了素材包,接下来就该创作了。AutoMV 里有两个核心 AI 角色:编剧和导演。编剧是 Gemini 大模型,它根据前面拆出来的音乐结构和歌词,把整首歌分成 3-15 秒的小片段,每个片段都写好场景描述、角色动作。
比如歌词唱 “在海边相遇”,编剧就会设计出 “夕阳下的海边,男女主角偶然擦肩而过” 这样的场景。
同时编剧还会建一个 “角色库”,把 MV 里的角色写得明明白白,比如身高、发型、穿什么衣服、是什么性格,这样不管哪个镜头,角色都不会变。
导演则是豆包,它会把编剧的想法变成具体的拍摄指令,比如这个镜头用远景还是特写,角色该做什么动作,还会生成关键帧的提示词,让 AI 知道该画什么样的开头画面。
更贴心的是,为了让镜头连贯,后面片段的开头画面会直接用前面片段的结尾画面,就像拍电影一样,不会有跳跃感。
第三步,选对相机拍视频,该抒情该演唱都拿捏
剧本和指令都有了,接下来就是生成视频了。AutoMV 不会死磕一个工具,而是根据场景选最合适的模型。比如拍普通的叙事场景,就用豆包生成电影质感的画面;
如果是副歌部分,需要突出歌手演唱,就用 Qwen-Wan-2.2 专门做唇同步,确保歌手的嘴型和歌词完全对上。
遇到长一点的片段,它会分成几个短片段来拍,然后再无缝拼接起来,保证画面流畅。而且会把之前分离出来的人声轨道用上,就算歌词发音模糊,唇同步效果也不会差。

第四步,AI 当导演,不好的画面直接重拍
生成完不是直接输出,还有一道质量检查关。AutoMV 里的 Gemini 验证智能体就像个严格的质检员,先看关键帧合不合格,角色姿态自然不自然,有没有违背物理规律,比如人飘在空中这种离谱的画面。
再看视频片段,动作流畅不流畅,角色是不是和角色库里的一致,画面和歌词、音乐对不对得上。
如果不合格,就会让前面的模块重新生成,直到满意为止。有了这一步,就能避免很多离谱的错误,保证 MV 的质量。
之前评价 MV 全凭感觉,所以,开发团队还专门做了个评价体系,从四个维度打分:技术、后期、内容、艺术,每个维度下面还有具体的小指标,比如技术看角色是否一致、唇同步准不准;内容看画面和歌曲主题对不对味、有没有故事性。
登录/注册后继续阅读
立即登录/注册 >































