
我要认证
2025-12-23
现在大语言模型在处理复杂任务时总卡两个坎,要么脑子不够用,深层推理绕不明白;要么花钱如流水,计算成本高得吓人。
就拿那些跨学科的难题来说,比如号称人类终极考试的测试,传统大模型要么做不对,要么做对了但费用能让人倒吸一口凉气。
英伟达和香港大学的联合团队最近搞的ToolOrchestra技术,直接把这两个坎儿给平了。核心就是训练一个小个子协调模型,让它当“总指挥”,智能调度各种工具和专业模型。
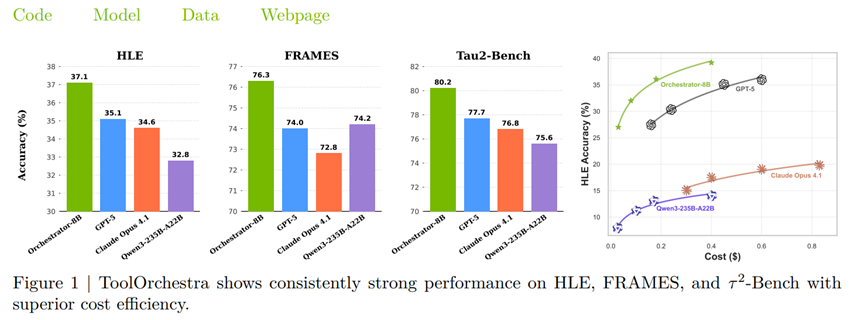
结果80亿参数的模型,居然在人类终极考试里干过了GPT-5,准确率37.1%比GPT-5的35.1%还高,关键是效率提升了2.5倍,成本才是传统方案的三成左右。

近几年大模型确实牛,像GPT-5、Claude这些顶尖选手,有时候表现得比人类专家还靠谱。但你真让它们啃硬骨头,问题就暴露了。首先是能力有上限,哪怕是千亿参数的大家伙,遇到需要跨领域协作、一步一步慢慢推理的任务,也容易犯糊涂,要么瞎编答案,要么推理到一半就断片。
人类终极考试里,GPT-5在纯文本部分的准确率也就35.1%,那些没工具帮忙的小模型更惨,准确率连5%都不到。其次是花钱太狠,跑一次复杂任务可能要花几十美元,还得等几十分钟才能出结果,这要是想大规模商用,根本不现实。
更关键的是,以前的工具使用方式太浪费了。以前大家都觉得,给一个强模型配点搜索、计算器之类的基础工具就行,但这就像让一个全能选手自己干所有活,明明可以找专业帮手,偏要自己硬扛。
咱们人类解决复杂问题,不也会找医生、律师这些领域专家,或者用专业软件帮忙吗?AI系统也该这么干啊。而且现有模型用工具还特别偏心,要么总找自己的亲戚模型,比如Qwen3-8B当总指挥时,73%的活儿都交给GPT-5;
要么不管成本高低,一股脑全找最强的工具,GPT-5当总指挥时,98%的调用都给自己或者自家的小模型,完全不考虑性价比。结果就是要么活儿没干好,要么钱花超了,根本没法兼顾。
ToolOrchestra就不一样了,提出了个“协调范式”,说白了就是不让一个模型独断专行,而是让一堆不同的工具和模型协同作战。
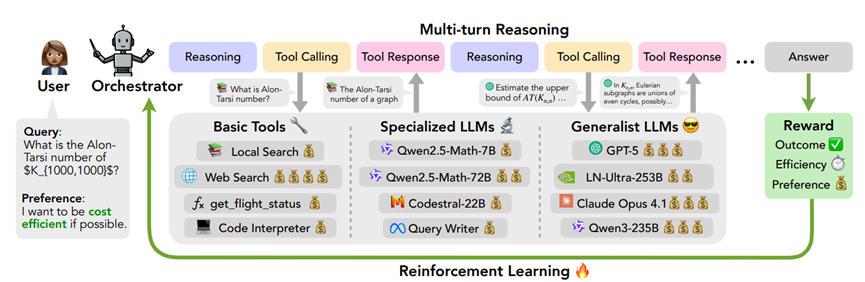
训练一个轻量级的协调模型当大脑,根据任务需求选最合适的工具,按最优顺序调用,既能突破单个模型的能力上限,又能省着点用资源。这思路一下子就把AI系统的构建逻辑给变了,复杂任务终于有了更靠谱的解法。
ToolOrchestra能成功,可不是瞎猫碰上死耗子,背后是一整套创新。首先是工具接口统一,以前各种工具五花八门,模型根本没法高效适配,现在它把工具分成了三类:基础工具比如网页搜索、本地搜索、代码运行工具,还有查航班状态这种专用功能;
专业模型比如专门写代码、做数学题的模型;还有GPT-5这种通用大模型。而且所有工具都用统一的接口,模型不用管工具底层怎么工作,只要知道它能干嘛就行。
为了让协调模型摸清每个工具的底细,团队还会让工具先完成一些任务,再根据表现生成说明,比如明确告诉协调模型,某个模型数学厉害但化学命名不行,这样调度起来就不会出错。就像给每个工具贴了标签,协调模型一看就知道该叫谁上场。
然后是训练方法,用的是端到端强化学习,核心是三个奖励机制,让模型知道怎么选工具才对。第一个是结果奖励,任务完成了就给满分,没完成就零分,还让GPT-5当裁判判断答案对不对,确保模型先把活儿干好。
第二个是效率奖励,要是模型调用工具花太多钱、等太久,就扣奖励,逼着它选经济实惠的组合。比如调用GPT-5很贵,模型就会先试试便宜的数学专用模型,能解决就不麻烦GPT-5。
第三个是偏好奖励,比如用户想保护隐私,不想用外部搜索,模型就会多调用本地工具,用户想追求极致准确,不在乎钱,模型就敢直接上最强工具。为了让训练稳定,团队还加了过滤机制,比如有些任务奖励都差不多,说明没什么训练价值,就直接剔除,这样模型学得更快更准。
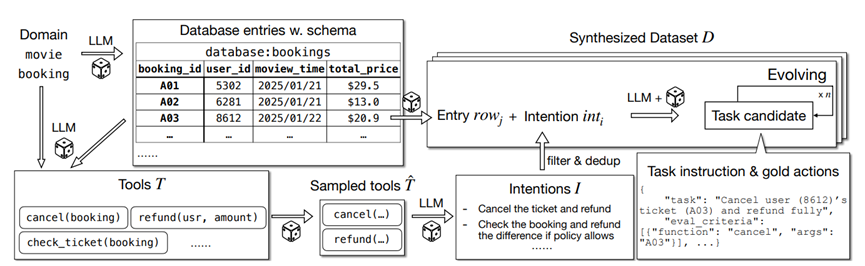
还有个关键是数据,强化学习需要大量高质量数据,但工具调用的相关数据特别少,还不好验证。
团队就自己造了个ToolScale数据集,涵盖10个领域,先模拟真实环境,比如生成电影预订的数据库和相关工具,再生成各种用户任务和正确的工具调用步骤,还会给任务加难度,确保模型能学到真东西。
而且数据质量把控很严,工具调用出错的、模型搞不定的、太简单不用工具的,全给删掉,最后剩下的都是高质量样本。还专门做了用户偏好数据集,比如用户说“我有机密信息,不想调用外部工具”,就对应一套工具选择规则,让模型能适配不同需求。
实际测试结果才叫惊艳,团队在三个权威基准测试里都试了,Orchestrator-8B表现全是顶尖水平。先看人类终极考试,这可是博士级别的题目,传统模型就算配了工具,准确率也难超35%,Orchestrator-8B直接干到37.1%,比GPT-5还高2个百分点。
更离谱的是成本,它每次任务才花9.2美分,耗时8.2分钟,而GPT-5要花30.2美分,等19.8分钟,成本省了快七成,效率提升了两倍多。这都是因为协调模型调度聪明,数学题找数学模型,跨领域任务组合用工具,不像GPT-5总依赖自己人,又贵又不一定好用。
再看FRAMES测试,全是需要查资料、多步推理的题目,Orchestrator-8B准确率76.3%,比GPT-5还高,成本却只有Claude的八分之一,速度也快很多。
登录/注册后继续阅读
立即登录/注册 >































