
我要认证
2025-12-20
咱们日常用的AI不管是办公处理文档、刷视频时的图像解读,还是学外语时的跨语言沟通,其实都有一个核心需求,就是希望AI既能看懂文字,又能认得出图像,还能hold住超长的内容不断片。以前很多大模型要么只能处理文本,要么需要超大参数才能兼顾多任务,普通开发者和中小企业想用上都难。
而谷歌刚开源的T5Gemma 2算是把轻量和全能给焊死了。作为T5Gemma家族的最新模型,支持140种语言+多模态+超长上下文,关键是参数规模没暴涨,手机、平板、电脑等普通设备都能部署在本地,这波操作确实让人眼前一亮。
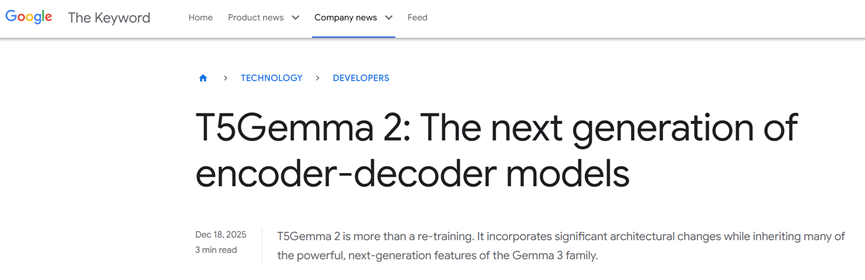
T5Gemma 2的底子是Gemma3,就是那个在文本理解和推理上已经很能打的模型。研究团队没想着从头训练,而是用了个特别聪明的办法,把原本只能输出内容的仅解码器模型,改成了能读能写的编码器-解码器架构。
简单说,这就像给一个只会说话的人,专门配上了灵敏的耳朵和高清的眼睛,既能听清别人说的话,又能看清眼前的东西,回应起来自然又准又快。
而且这个改造不是瞎折腾,是沿用了之前T5Gemma的成熟方案,再加上UL2训练目标做优化,相当于站在巨人的肩膀上升级,稳得很。更厉害的是,它把纯文本模型的改造思路,直接用到了多模态上,就像给老电脑装了个新插件,兼容性好还不卡,效果直接拉满。
T5Gemma 2技术亮点
以前很多轻量模型真的就是睁眼瞎,只能处理文字,遇到图片就彻底歇菜,想让它解读个图表、识别个产品图,还得额外调用其他工具,麻烦得不行。
T5Gemma 2就不一样了,它直接复用了Gemma3里的视觉编码器,这个编码器是基于SigLIP做的,有4亿参数,相当于给模型装了双高清眼睛,看图片清楚得很。
它处理图片的逻辑特别简单,先把一张图片转换成256个信息小块,然后把这些小块和文字一起传给编码器。而且这些图像和文字信息在模型里是互通的,就像我们看书时一边看文字一边看插图,能自然而然地联系起来,不用额外费劲。
T5Gemma 2训练的时候这个视觉编码器是固定不动的,不会额外增加计算负担,就算是轻量版本的模型,也能轻松扛住,不用非得高性能设备才能跑。
现在用它做图像描述、识别文档里的图表,甚至回答图片里的文字问题,一个模型就能搞定,再也不用来回切换工具,对经常处理图文混合内容的人来说,简直是救星。

谁没遇到过AI读长文档断片的情况?以前很多模型最多只能处理几万字,超过这个长度就记不住前面的内容,看一篇几万字的学术论文、一份长篇合同,都得手动分段,一段一段喂给AI,麻烦不说,还容易丢失上下文逻辑,真的特别影响效率。
T5Gemma 2用了个创新技术,虽然它训练的时候只学了16K长度的内容,但实际用的时候,直接能冲到128K。
这是什么概念?大概就是能一口气读完一本几十万字的小说,还能准确回答里面的细节,比如某个人物在第几章说了什么话,前后的因果关系都能理得明明白白,完全不会糊涂。
为了让长文本处理更稳,还优化了位置编码,局部注意力用10k基频,全局注意力用1M基频,就像我们看书时,既能关注当前段落的细节,又能记住整本书的结构,不会读了后面忘了前面。
而且还保留了Gemma3里5:1的局部和全局注意力比例,处理速度没降,理解精度反而提上去了,真的特别实用。
轻量模型最让人担心的就是,为了省参数牺牲效果,用起来磕磕绊绊的。但T5Gemma 2的两个优化思路,真的堪称教科书级别,完全不用有这个顾虑。
第一个是绑定词嵌入,以前编码器和解码器各有一套独立的词库,就像两个人各背一本字典,很多内容都是重复的,既占地方又没用。
现在研究团队把它们的词库合并成一本,编码器输入、解码器输入、解码器输出三个地方共用,一下子就省了10.5%的参数。
实际测试下来,性能几乎没变化,就像把两本重复的书合成一本,重量轻了,里面的内容一点没少,特别划算。
第二个是融合注意力,以前解码器里有两个独立的注意力模块,一个管自己的输出逻辑,一个管关联编码器的输入信息。研究团队发现这俩功能其实很像,都是从一堆信息里找重点,就把它们合并成了一个模块。
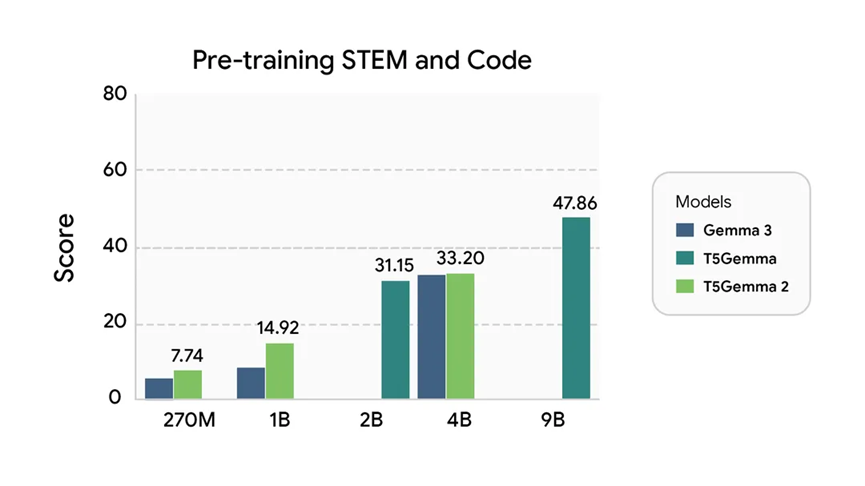 这样一来,参数又省了6.5%,性能只降了0.3个点,完全在可接受范围内,几乎感觉不到差别。
这样一来,参数又省了6.5%,性能只降了0.3个点,完全在可接受范围内,几乎感觉不到差别。
简单说,这两个操作就像给模型瘦身不瘦脸,去掉的都是冗余的部分,留下的都是核心功能,普通电脑跑起来都不费劲,不用非得配置高端GPU。
目前,T5Gemma 2提供了三个版本,参数都是编码器和解码器对等分配的,平衡得很好,大家可以根据自己的需求选,完全不用浪费资源。
270M-270M是最轻便的版本,适合嵌入到手机、边缘设备里,处理一些简单的图文任务,比如手机上的图片识别、短文本问答,完全够用。
登录/注册后继续阅读
立即登录/注册 >































