
我要认证
2025-12-19
最近两年,AI大模型的参数规模越来越大,对数据的需求也水涨船高,早就突破了万亿token的量级。但模型架构可以开源共享,高质量数据却很难获取。OpenAI、谷歌这样的商业公司有自己的专属爬虫和数据处理流程,能做出优质的私有数据集。
而开源社区只能依赖CommonCrawl这样的公开网页快照,可这些原始数据里混着大量垃圾数据,比如重复的网站导航、弹窗广告、无意义的乱码,还有很多重复内容,直接用会严重拖垮模型性能。
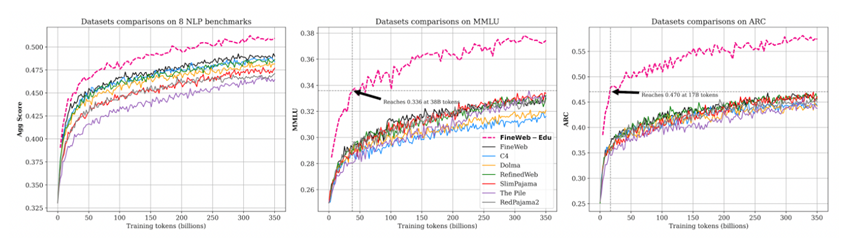
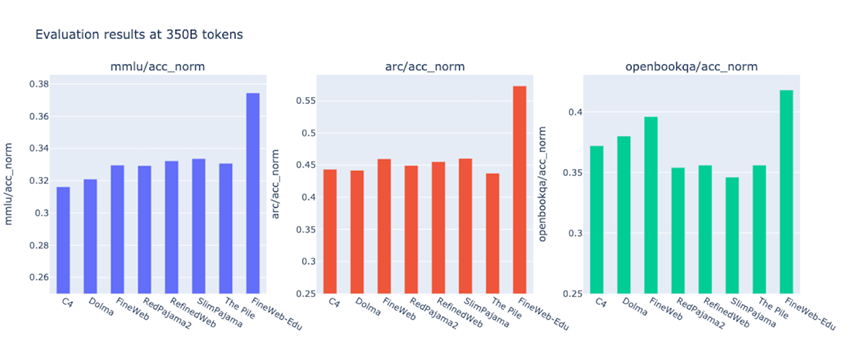
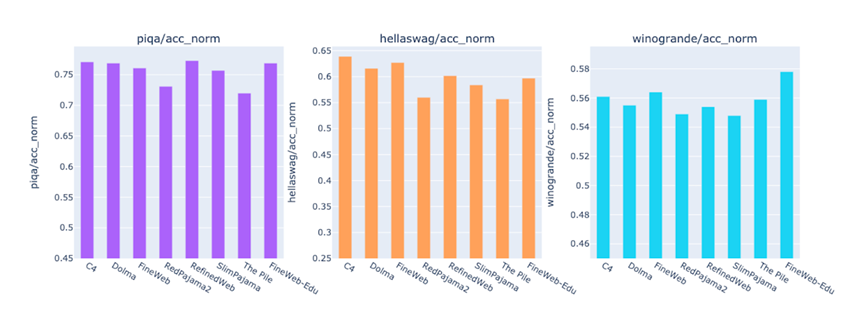
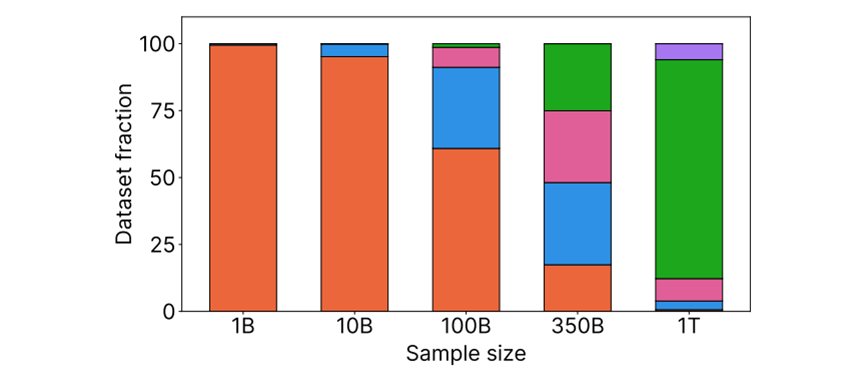
为了解决这些问题,全球著名开源平台HuggingFace花了多年时间,基于近十年的96个Common Crawl快照,打造出了高质量FineWeb数据集。不仅规模达到15万亿token,足够训练超大规模模型,还公开了从数据提取到最终发布的全部细节,连使用的工具和实验模型都一并开源,相当于给开源社区提供了一套可直接套用的数据制作说明书。

FineWeb能成为优质数据集,靠的不是运气,而是一套经过反复验证的精细化处理流程。就像制作精品食材需要经过挑选、清洗、加工等多道工序,FineWeb的处理也分五个关键步骤,每一步都在为数据质量把关。
CommonCrawl提供两种数据格式,一种是包含完整网页信息的WARC文件,另一种是只提取文本的WET文件。以前很多人图方便直接用WET文件,但HuggingFace发现,WET文件里藏着很多无效内容,比如网站导航、广告弹窗这些没用的信息,占比高达30%,会干扰模型学习。
于是研究研究团队改用Trafilatura工具从WARC文件中提取文本,这个工具就像有一双“火眼金睛”,能精准识别网页里的核心内容,把那些无关的“杂质”过滤掉。虽然这样做增加了一些计算成本,但效果很明显:用Trafilatura提取的文本训练模型,准确率比用WET文件的模型高出不少,有效内容占比从68%提升到了92%,这笔投入完全值得。
提取出文本后,首先要做的是“粗筛”,把明显的低质量数据剔除。这一步主要做三件事:首先是用URL黑名单过滤掉成人内容、恶意网站这类违规数据;
然后用专门的语言识别工具,只保留英语置信度足够高的文本,避免多语言混杂的低质量内容;最后根据文档长度、字符重复率等指标,剔除那些太短或全是重复字符的无意义文档。
经过这一轮筛选,原始数据从98万亿token精简到36万亿token,去掉了六成多的垃圾数据,形成了一个初步干净的数据池,为后续处理打下基础。
网页数据里有很多重复内容,比如同一篇文章被多个网站转载,不同时间快照里重复抓取的相同网页。这些重复数据会让模型“学废了”,不仅浪费训练资源,还会降低泛化能力。但去重也是个技术活,处理不好反而会适得其反。
研究团队一开始尝试把所有快照的data合并起来统一去重,结果发现效果很差。原来早期快照的高质量内容本身就少,统一去重后,那些没人转载的低质量内容反而被保留了下来,就像把好苹果和烂苹果放一起筛选,最后剩下的反而多是烂苹果。
后来调整策略,对每个快照单独去重,再把结果合并。这样既去掉了单个快照里的重复内容,又保留了不同快照里的独特优质内容,比如新快照里的技术博客和旧快照里的绝版书籍文本。
同时,研究团队还精准设置了去重参数,只剔除相似度极高的内容,不会误删那些相似但不重复的优质文本。调整后,数据量变成20万亿token,模型准确率也大幅提升。
在去重的基础上,还要进行“精筛”,进一步提升数据质量。他们参考了经典数据集C4的过滤规则,剔除了包含占位文本、特定关键词的低质量文档,但放弃了那些会剔除大量有效数据的规则。
同时,研究团队还自己设计了一套筛选标准。他们收集了50多种文档指标,比如每行结尾有标点的比例、重复行的占比等,通过对比高质量和低质量数据的差异,找出关键筛选阈值。
比如发现高质量数据中,大部分文档每行结尾有标点的比例都很高,于是就把这个比例太低的文档剔除。最终确定了三个核心筛选规则,既去掉了低质量内容,又保留了足够多的有效数据,让模型准确率再次提升。
为了符合数据隐私法规,研究团队还对数据进行了脱敏处理,把文本中的电子邮件地址、公开IP地址等个人敏感信息匿名化。这一步虽然只影响了极少部分数据,但确保了数据集可以安全合规地被广泛使用。
除了基础版FineWeb,研究团队还推出了教育专用版FineWeb-Edu。研究发现,教材、科普文章这类教育文本富含结构化知识和逻辑推理内容,能让模型在知识问答、推理任务上表现更好。但从海量网页中筛选教育内容并不容易,人工标注成本太高,关键词匹配又容易出错。
登录/注册后继续阅读
立即登录/注册 >































