
我要认证
2025-12-18
在人工智能领域,大模型的能力一直在爆发式增长,但我们对它们内部工作机制的了解却远远跟不上。像GPT系列、Claude这些模型,在代码生成、自然语言理解等方面表现得越来越强。
但它们的内部计算过程就像一个密不透风的黑箱。神经元什么时候激活、权重之间怎么关联,都没有规律可循,我们根本没法精准知道模型是怎么做出某个决策的。这不仅让我们很难修复模型的缺陷,还给AI的安全应用埋下了不少隐患。所以,OpenAI开源了一种全新方法来解决这个大难题。
OpenAI的核心技术思路其实很简单,让模型的大部分权重都变成零,只保留少数非零连接,这样训练出来的模型,内部会形成一个个专门对应不同任务的简单电路,我们普通人也能看懂。实验数据显示,和传统模型比起来,这种稀疏模型的任务电路规模缩小了16倍,而且通过一种特殊的桥接技术,还能用来解释那些已经训练好的传统大模型。
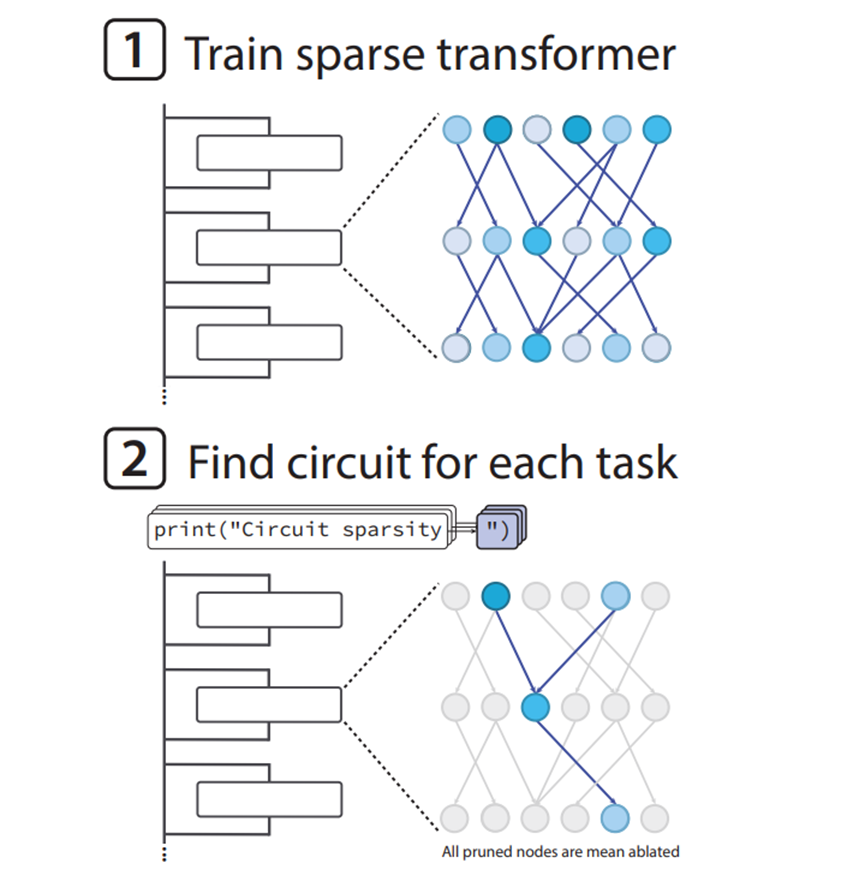
现在我们常用的语言模型,核心都是Transformer架构,主要由多头注意力机制和前馈神经网络组成。这些模型在海量数据上训练后,能学会各种复杂技能,但内部结构却越来越难拆解。
比如一个神经元,可能既对医疗术语有反应,又会对情感表达做出回应,一个组件身兼数职。再加上权重矩阵里密密麻麻的非零值,想单独搞清楚某个参数的作用,简直比大海捞针还难。
OpenAI之前提出过一个叠加态假说,很好地解释了这个问题。简单来说,传统的稠密模型就像用一个U盘同时存储多个文件,所有信息都挤在一起,想单独取出一个文件就很麻烦。
而那些看似复杂的计算,其实本质上是对一个更大、更清晰的稀疏网络的近似。之前也有研究者尝试用各种方法分离这些叠加的信息,但往往需要简化掉很多复杂计算,最后得到的结果可能掺杂了太多人为假设,不一定是模型真正的工作方式。
而这次新研究的思路,相当于直接打造一个天生就条理清晰的U盘,每个文件都有专属的存储区域,不用再费力分离。这种权重稀疏化,就是让模型里的每个神经元只和少数几个通道建立连接,这样就没法把一个概念分散到多个组件里,只能用最简洁的方式完成任务,自然也就更容易被我们理解。
OpenAI研究团队采用了类似GPT-2的解码器架构,但做了很多针对性修改。最核心的就是全层权重稀疏约束,最稀疏的模型里,每1000个权重只保留1个非零值,相当于让模型在做计算时,只能用少数几条固定路径。
为了让稀疏结构能稳定工作,OpenAI还用RMS归一化替代了常用的LayerNorm,这样能保证残差流中零值的特殊意义,不会影响对稀疏性的判断。同时在模型多个关键位置加入了特殊的激活函数,只保留激活值最大的25%,进一步让计算路径更集中。
还有一个很实用的设计是加入了二元语法表,专门存储简单的词对频率信息。这就像让模型把基础的常识性知识单独存放在一个小手册里,不用占用稀疏参数的宝贵空间,既提升了性能,又让核心电路更简洁。值得一提的是,这个模型居然没使用任何位置编码,但性能几乎没受影响,而且采用了较小的注意力头维度,让每个注意力头的功能更专一。
但训练这样的稀疏模型并不容易,就像在钢丝上走路,既要保持稀疏性,又不能让性能崩溃。研究团队为此设计了一套完整的训练策略。
研究人员采用了L₀范数退火的方法,训练初期模型还是稠密的,然后在训练前50%的步骤中,慢慢减少非零权重的数量,让模型逐渐适应稀疏约束,避免一开始就因为过于稀疏而无法学习。优化器方面,选用了AdamW,还做了专门的参数配置,并且对每个实验都单独寻找最优学习率。梯度裁剪也起到了关键作用,把梯度的根均方值限制在1以内,保证了训练过程的稳定。
学习率调度采用了鲨鱼鳍模式,先有1%的热身阶段,而且学习率会根据稀疏程度动态调整,稀疏度越高,学习率越大,这样才能让模型在稀疏约束下依然高效学习。另外,为了避免神经元变成没有任何有效连接的死神经元,他们还强制每个神经元至少保留4个非零连接,平衡了模型性能和可解释性。
模型的训练数据也很有讲究,是混合了简单重复代码和通用Python代码的数据集,总量达到350亿token,既保证了电路的可观察性,又不会让数据过于简单而失去实际意义。
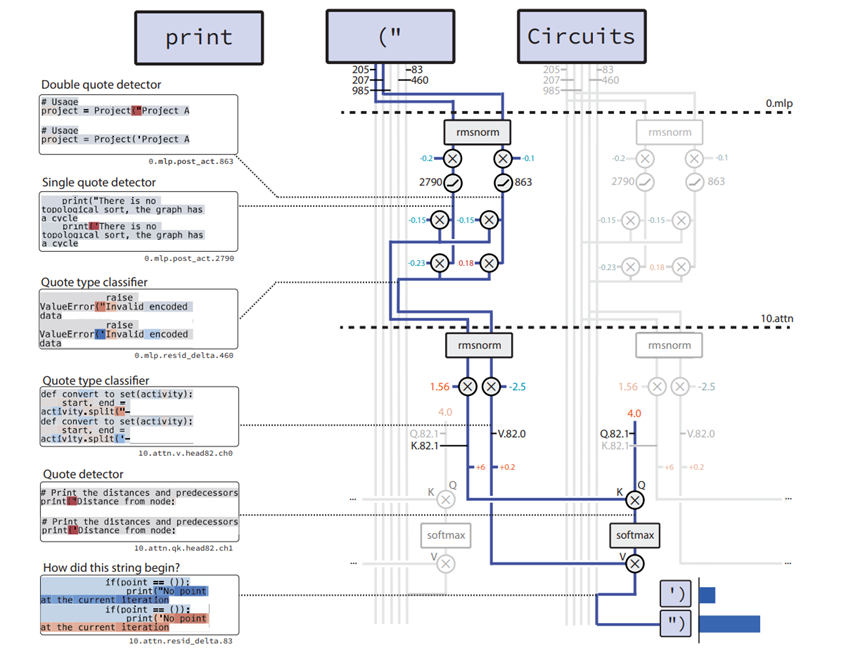
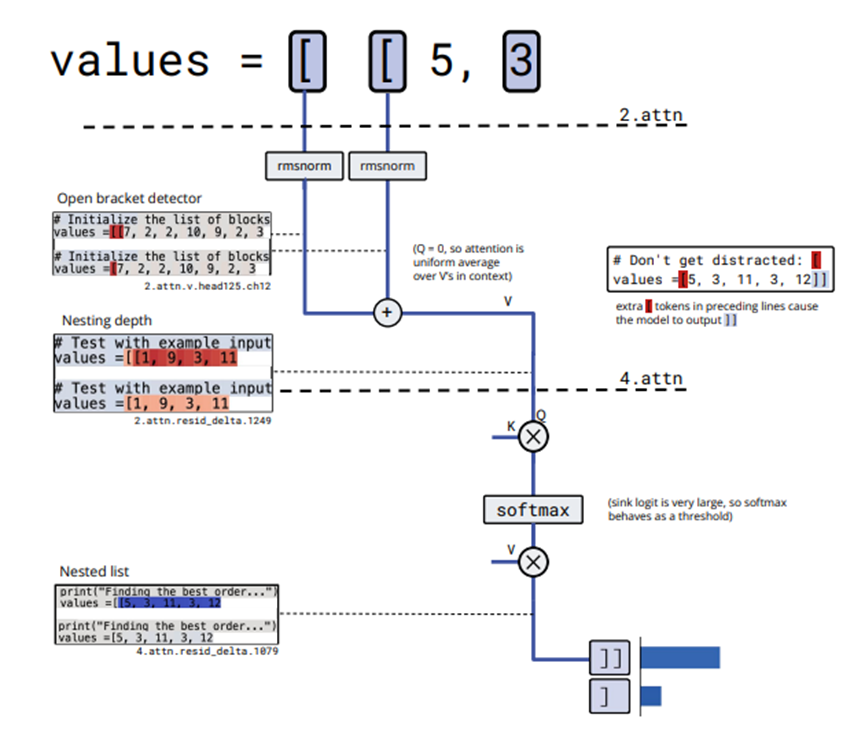
剪枝是这个研究的关键步骤,相当于从复杂的模型中,精准找出完成某个特定任务的最小电路。电路在这里被定义为一组节点和边的集合,节点包括单个神经元、注意力通道等,边就是权重矩阵中的非零项,一个最简单的电路可能只需要3个节点和2条边。
剪枝的目标是找到能达到目标损失的最小电路,被删除的节点会被均值消融,也就是把它们的激活值固定在预训练分布的平均值。这个过程就像在一堆复杂的线路中,找出点亮一盏灯所必需的最少线路,多余的线路都可以断开。
剪枝算法采用梯度下降来优化掩码参数,为每个节点分配一个可学习的参数,通过这个参数决定节点是否被保留。优化过程中,会同时考虑任务损失和电路规模,确保找到的电路既小又能完成任务。超参数调优则采用了专门的算法,每个模型和任务的组合都会进行32轮迭代,每轮包含8个并行剪枝任务,保证了剪枝结果的可靠性。
研究团队还手动构建了20个简单的Python代码下一个token预测任务,比如根据开头的引号类型预测闭合引号,根据列表嵌套层数预测闭合符号等。这些任务逻辑清晰,非常适合验证电路的正确性。
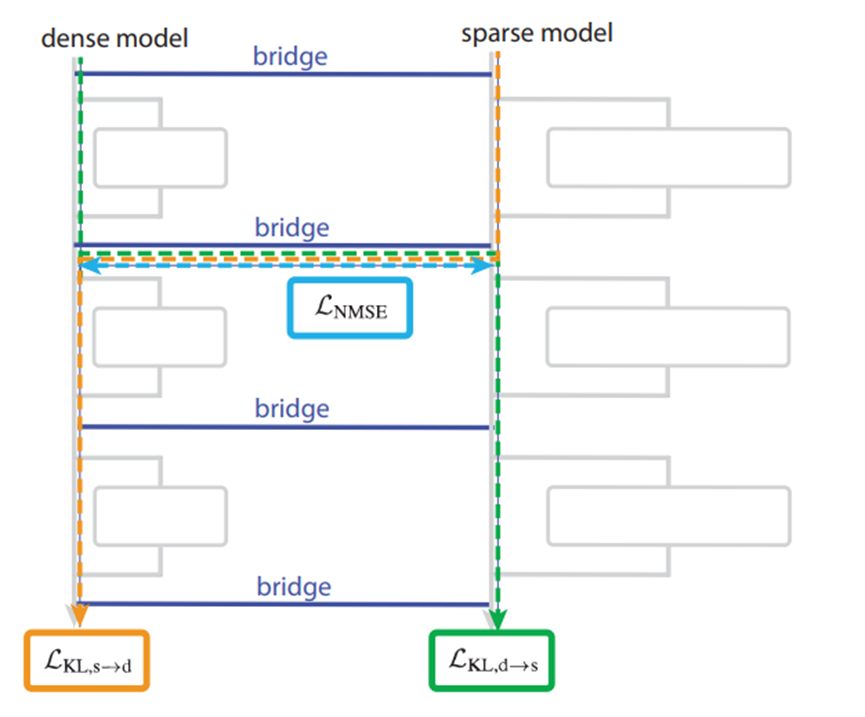
直接训练的稀疏模型虽然可解释性强,但训练效率低,性能也很难达到前沿水平。为了让稀疏模型的优势能惠及现有的传统稠密模型,研究团队提出了桥接技术。
登录/注册后继续阅读
立即登录/注册 >































