
我要认证
2026-05-19
字节跳动研究院刚刚开源了多模态全能模型 Lance。
这次字节完全没走堆参数堆算力的老路,只用了 30 亿激活参数,在不超过 128 张GPU 的训练预算下,就把图像和视频的理解、生成、编辑三大能力全部打通。
在各大公开评测榜单上直接冲到前排,性能对标比它参数大几倍的模型,甚至在不少任务上更强。

开源地址:https://huggingface.co/bytedance-research/Lance
https://github.com/bytedance/Lance
老规矩咱们先直接看效果吧。Lance可以直接完美移除小姐姐脸上的贴纸
也可以为视频直接添加场景,比如为长颈鹿的周围添加一些气球。
把视频里的男孩换成穿黑衬衫的女孩。
Lance除了可以编辑视频之外,也支持文生视频,比如输入提示词:一段精美的动画电影镜头展现了一个铜管机器人在灯笼照亮的城市广场上演奏小提琴,一只小狗静静地坐在旁边,沐浴在温暖的晚光中。
机器人占据了画面至少三分之二的面积,始终是视觉焦点。场景充满奇思妙想,画面优美,细节丰富,人物刻画鲜明,氛围优雅。镜头固定。机器人拉弓的弧线流畅优美,小狗则安静地聆听。
Lance之所以性能这么强,主要靠的是一套非常讨巧的协同技术思路。不是硬把理解和生成塞进一套参数里乱炖,而是搞了个统一上下文加上解耦能力通路的玩法。
简单来说就是大家都在同一个大教室里上课,能互相借笔记交流,但考试的时候各有各的专属答题卡。
Lance把文本图像视频全塞进一个交错序列里,不管你是要理解还是要生成,都在同一个上下文空间里转悠。
为了不让大家抢资源,还用了个双流混合专家架构,理解任务有理解专家负责,用预测下一个词的思路来练,生成任务有生成专家负责,用流匹配的思路来练。这样共享了信息又保住了各自的专业性,确实高明。
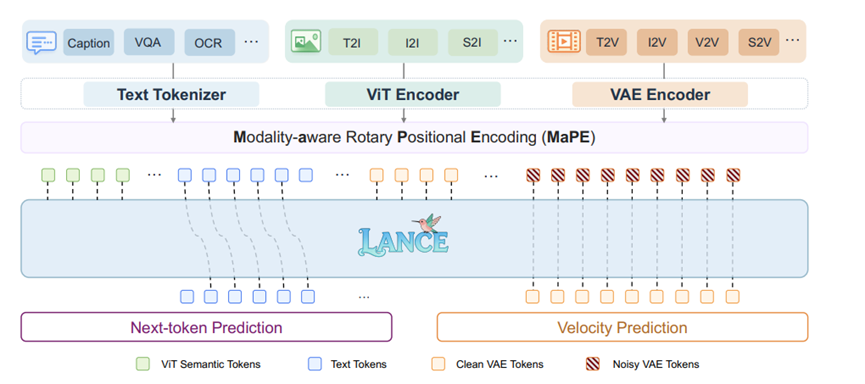
不过把一堆乱七八糟的视觉token塞进同一个序列肯定要出乱子。
你想啊,序列里既有提取出来的语义特征,又有用来做条件的干净隐层特征,还有加了噪的目标特征,这要是不加区分,模型自己都懵到底谁是谁。
Lance这里用了个特别精妙的招数叫模态感知旋转位置编码。它没有改变原有的空间位置排布,而是在时间维度上给不同类型的特征加上了专属的偏移量。
这就好给不同部门员工挂上不同颜色的工牌,虽然都在一个办公区流转,但一看工牌就知道你是哪个部门来的。
训练策略上Lance也是个十足的稳健派,玩了把分阶段通关。先搞预训练建立基本功,用海量图文视频对让模型把基础的世界观建起来,这时候还特意把编码器冻住省点算力。
接着进入持续训练阶段,开始加入交错多模态和各种复杂的编辑主体驱动数据,慢慢把专业任务能力拉上来。

登录/注册后继续阅读
立即登录/注册 >






























