
我要认证
2026-05-25
最近上海人工智能实验室联合几家高校开源了一个创新框架Code-as-Room。
只要给它一张室内的俯视图,它就能全自动吐出一套完整的3D场景代码,直接扔进Blender里就能跑能编辑。

开源地址:https://github.com/YxuanAr/Code-as-Room
咱们以前想做个像样一点的3D房间模型,那是相当麻烦的。你得懂建模懂材质,还得一点点调光影摆家具,费时费力不说,没点专业功底根本摸不着门道。
后来大家就想招,用规则和约束让电脑自动摆家具,但这招太死板,全靠人工预设的条条框框,遇到稍微复杂点个性化点的房间就抓瞎。
再后来多模态AI大模型火了,有人尝试根据文字描述来生成场景,但文字这东西描述空间位置实在太含糊。
你说把桌子放中间偏左一点,模型理解的中间和你的中间可能差了十万八千里,最后生成的房间往往牛头不对马嘴。
于是大家发现,还是直接给模型看俯视图最靠谱,这跟我们现实中看户型图是一个道理,一眼就能看清哪是墙哪是窗家具怎么摆。
之前也有像VIGA这样的先锋研究尝试让智能体写代码来建场景,但一到俯视图这个领域就水土不服了,细节根本还原不出来,要命的是模型动不动就陷入死循环改来改去,最后直接罢工。
而Code-as-Room突破了这些难题,抛弃了那种一口气吃成胖子的端到端生成方式,转而用了一种由粗到细循序渐进的策略。
这套框架最让我觉得精妙的地方,是给整个流程装上了记忆系统。
以前那些智能体经常犯的毛病就是记性差,前面刚分析出门在左边,后面放家具的时候就把门给堵上了。
Code-as-Room弄了个跨阶段记忆模块,每一步干完活都会把结果带个标签存进全局记忆库,下一步干活只能看该看的部分。
既不会忘了前面的设定,也不会被乱七八糟的幻觉信息干扰,这个设计真的太贴合我们人类做事的逻辑了。
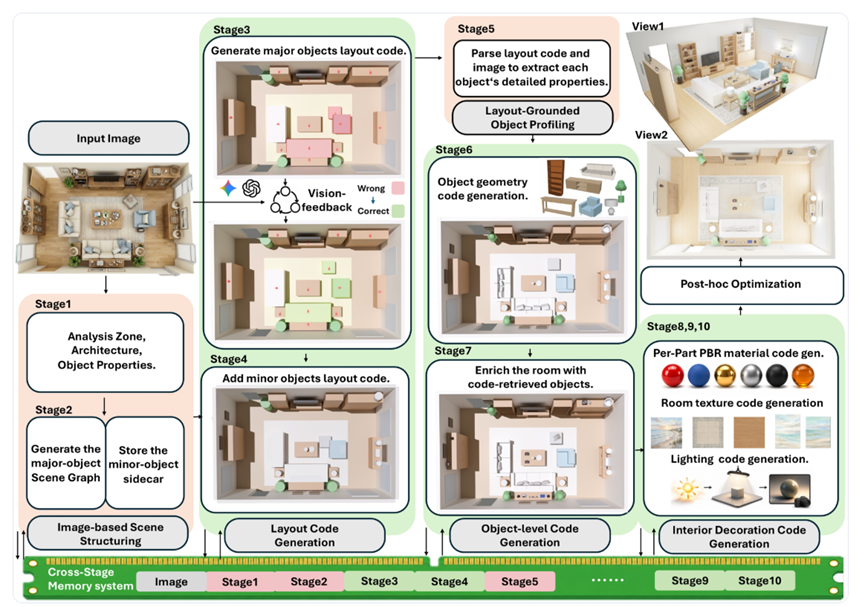
也是分步策略来拆解的,第一步是图像结构化,大模型先看图说话,把房间里的功能区理清楚,墙角门窗这些固定结构先定位好,给每个物体发个身份证,顺便建个场景图,谁挨着谁谁靠着墙都安排得明明白白。
接下来是布局代码生成,先把大件家具的位置用代码写出来,这时候特别好玩的一个机制出现了,叫渲染评估修正闭环。
简单说就是代码写完先在Blender里渲染成图,然后大模型自己对比原图找茬,看看是不是家具放重叠了或者越界了,再动手改代码。
实验证明这个找茬环节最多来五次效果最好,少了改不到位,多了模型容易想太多反而把布局搞乱。
大件搞定后,就该往墙上挂东西和摆地毯绿植这些醒目的小物件了,至于桌上的水杯书本这种微型物件则留到后面再处理,免得一开始画面太乱。
登录/注册后继续阅读
立即登录/注册 >































