
我要认证
2026-05-29
今天英伟达又搞了个大动静,开源了一个很强的视觉模型LocateAnything,可以快速定位任何物体。
目前,这个论文还被CVPR 2026收录了,并且在huggingface上排名第一,你就知道这个模型有多强悍了。
最离谱的是推理效率,在一张H100显卡上,使用混合模式每秒能检测12.7 BPS的框,比以前那种串行解码的模型快了10倍不止,完全是断层领先。

开源地址:https://huggingface.co/nvidia/LocateAnything-3B
说实话,刚看到这个模型我心里还犯嘀咕,觉得这是不是有点吹牛,什么叫什么都能定位啊。
但耐着性子把论文读完,我发现这货确实有点东西,尤其是那个核心的并行框解码技术。
直接打破了以前视觉语言模型那种慢吞吞逐个字符解码的节奏,把速度和精度都给拉上去了。
突破性技术
咱们玩AI的都知道,现在视觉模型虽然越来越火,但在视觉定位这块其实一直挺纠结的。
以前的主流办法很笨,把一个框的坐标拆成一串数字或者字符,模型得像打字员一样,一个字一个字地把坐标敲出来。
这种方式有个特别要命的问题,框的四个坐标点其实在空间上是紧紧挨着的,有很强的几何关联,你把它们拆散了硬生生一个个往外蹦,很容易就把这种关联给弄丢了,导致定位不准。
虽然也有人想过并行预测方案,但往往因为处理不好框的结构,容易把坐标搞混,就像是把张三的左手和李四的右手拼在了一起,看着别扭还不实用。
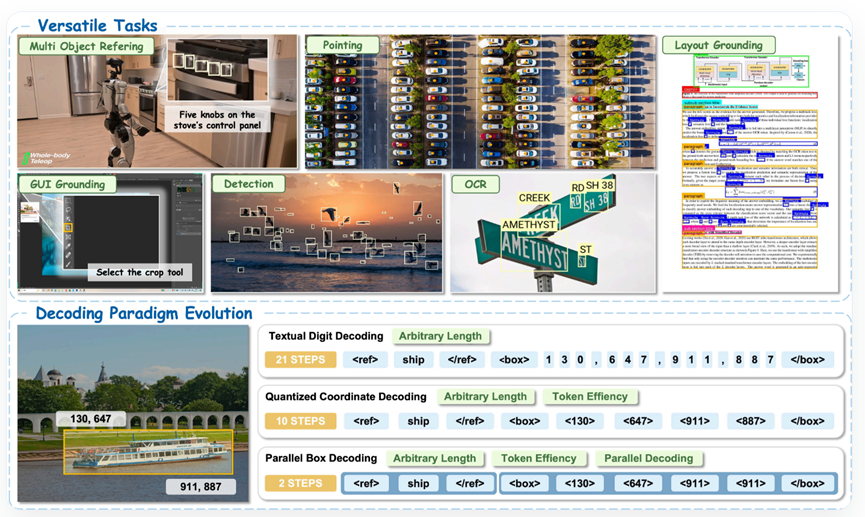
而LocateAnything这次就想通了,不再死磕一个个单独的字符,而是把整个边界框看成一个不可分割的原子单元。
搞出来的并行框解码技术,只需要两步就能把一个完整的框给解码出来,四个坐标值作为一个整体直接输出。
这就好比以前让你报电话号码,你必须一位位念,现在直接让你发一张写好号码的名片,又快又准。
为了做到这一点,他们专门设计了一套聪明的机制叫框对齐分块原则,坚决不随意拆解框的结构,同一个框里的坐标可以互相通气,但框与框之间又是井水不犯河水,从根源上避免了逻辑混乱。
三种解码模式
为了适应不同场合的需求,这个模型还贴心地准备了三种模式。慢速模式就是咱们熟悉的传统模式,虽然慢点但是特别稳,适合那种离线的、对精度要求极高的精修工作。
快速模式则是火力全开,主打一个快,特别适合装在机器人或者实时交互系统里,哪怕环境稍微乱一点也能反应过来。
最有意思的是混合模式,这简直就是为了咱们日常生产环境量身定做的。平时它都用最快的并行模式跑,一旦发现有点不对劲,比如坐标概率太低或者算出来的框离谱,会立马自动切回慢速模式重新算一遍那个局部。

再来说说LocateAnything的技术底座,用了一个挺经典的模块化架构,视觉部分负责看图,语言部分负责理解指令,中间通过投影层把这两者连起来。把连续的坐标归一化处理后,变成了固定长度的块级序列。
这里面设计了四种基础块,有管语义的,有管框的,还有专门处理没目标场景的负块,以及结束块。
就像给模型发了一套标准化的积木,不管是目标检测、文档分析还是GUI识别,本质上都是搭积木的过程,统一了格式也就统一了逻辑,一套模型就能干好多以前需要专用模型才能干的活。
登录/注册后继续阅读
立即登录/注册 >































