
我要认证
2026-06-02
大家平时用手机自带的修图,如果平时光线好、风景简单的照片,修修确实挺像样。
可一旦碰到大雾天拍的一片白茫茫,晚上黑灯瞎火拍的噪点图,或者家里翻出来的那种发黄模糊的老照片,这帮AI就开始掉链子了。
最近香港理工大学联手OPPO开源了一个很强的大模型数据集GGT-100K,很多FLUX.2、GPT-Image-2、Nano-Banana-Pro等开闭源模型,使用这个数据集之后修复照片的效果大涨。

开源地址:https://github.com/PolyU-VCLab/GGT-100K
https://huggingface.co/datasets/VCLab-PolyU/GGT-100K
为啥修复图片很难
要说这图像修复为啥这么难,还得从它是怎么学做饭的说起。你想啊,AI想要学会修图,就得给它看大量的作业本,也就是那种左边是模糊的烂图,右边是清晰的标准答案,照着模仿才能学会。
以前咱们搞这些作业本主要有两条路,但这两条路走起来都特别费劲。
第一条路就是让算法自己在电脑里瞎编合成劣质图片。这好处是量大管饱,不用出门拍照,但问题是这就像是在照着课本模拟炒菜,跟真正下厨完全是两码事。
电脑模拟出来的模糊、噪点,跟咱们现实中拍照遇到的复杂光线、镜头误差、压缩损耗根本不是一回事。
所以AI在实验室里考满分,一拿到真实照片上直接翻车,死活认不出。
第二条路倒是靠谱,就是真人实地去拍。同一个场景,先拍一张高清的作为标准答案,再人为制造模糊或者拍烂一张当考题。
这效果肯定是真材实料,但成本高到离谱。还得看老天爷脸色,想拍个大雾天还得等天气,想拍个雨夜也得碰运气,根本没法大规模收集,场景也特别窄。
就是因为这两条死胡同,这么多年咱们的修图技术才一直卡在那儿,看着参数漂亮,实际用起来bug一大堆。
既然老路走不通,这回研究团队就想了个绝招,直接利用现在火得一塌糊涂的多模态大模型来帮忙。
现在的这些大模型早就今非昔比了,既能看懂图片,又能根据文字指令生成画面。
那咱们能不能直接拿现实里那些模糊、烂糟糟的照片,扔给大模型,让它凭着本事给咱们画一张高清的标准答案出来呢?

这思路一打开,事就好办了。这就是他们提出的全新玩法,叫生成式基准范式。咱们也不用人工去模拟退化,也不用辛苦去实地拍摄配对。
直接去网上找各种真实场景的低质照片,不管是大雾天还是暗光夜拍,只要没标准答案的都拿来,然后交给顶尖的大模型。
让它智能还原出一张细节饱满的高清图。这样一来,一张模糊图配上AI生成的高清图,就是一组完美的训练数据。
说白了,这就像是找了个懂摄影、懂画质的超级AI专家,咱们给它一堆模糊老照片,让它帮咱们一张张手动修出完美版本。
而且它不嫌累,能修个10万张,做成一个超大题库供所有修复模型学习。
打造高质量数据集GGT-100K
当然,也不是随便找个大模型生成图片就完事的,要是生成的一塌糊涂,那不就把AI教偏了吗。
团队这次特别严谨,老老实实做了一套四层完整流水线,一步步筛选、测评、质控,最终才打磨出这套叫GGT-100K的数据集。
第一步他们先是大海捞针搜罗了一百多万张真实低质照片。一半左右来自全球各地的开源图库,什么雨雪雾霾老照片都有。
还有四成是从公开的视觉数据集里专门挑出来的画质差、有自然退化的素材。
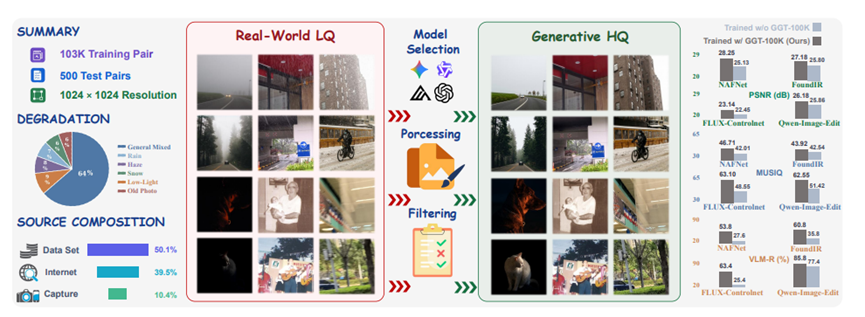
剩下的一成是团队自己用不同手机相机专门去拍的,刻意制造模糊、高噪点、暗光这些真实拍照时的缺陷。所有图片统一切成1024乘1024的大小,底子打得特别扎实。
第二步也是最关键的,就是选个靠谱的大模型当老师。团队横向测评了九款主流的大模型,有开源的也有不公开的,还设计了四种不同的文字提示方式。
就像面试一样,从画面保真度、视觉观感、语义判断、还有真人主观喜好四个维度全方位打分。
第三步批量生成之后,团队也没有直接入库,而是加了三道质量把关。先是用机器指标自动筛选,把修完还不如原图的劣质样本直接删掉。
登录/注册后继续阅读
立即登录/注册 >































