
我要认证
2026-06-03
咱们现在用AI写代码或者跑智能体的朋友应该有这样的烦恼,随便丢几个日志文件、工具输出或者RAG检索结果进去,上下文窗口瞬间就被撑爆,Token消耗实在太快了。
同时里面好多内容其实都是重复的废话或者格式化的冗余信息,大模型根本不需要逐字逐句地读完。
今天介绍一个github每日最佳开源,超7000星的headroom,来解决这个大难题。
开源地址:https://github.com/chopratejas/headroom
你可以把headroom看成AI领域的ZIP压缩包,作为一个专门针对AI上下文优化的压缩层,Headroom能在数据送进大模型之前,自动把工具输出、日志、文件和对话历史进行极致瘦身。
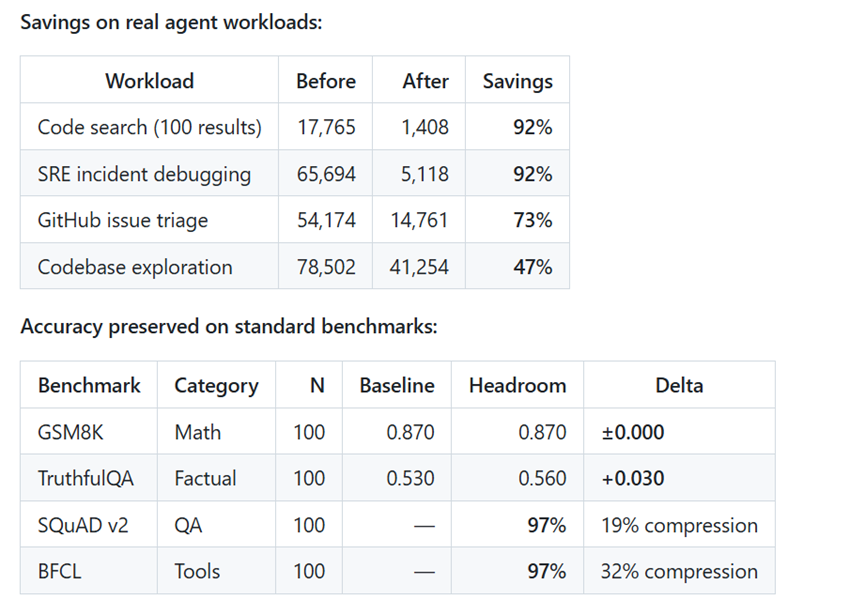
根据实测数据显示,在使用headroom之后可以节省60%—95%的token,最关键的是,回答质量几乎不受影响。

咱们先聊聊最基础的压缩能力。Headroom内置了好几种专门的算法,比如处理JSON数据的Smart Crusher,还有基于语法树分析代码的Code Compressor。
这意味着不是那种无脑的文本截断,而是真正理解了内容结构后再去精简。
对于开发者来说,这就好比请了一个懂技术的编辑帮你审稿,既删减了篇幅又保留了核心技术细节,让智能体在处理上百条搜索结果或海量报错日志时依然游刃有余。

除了压缩本身,还有个很贴心的设计叫可逆压缩机制。很多朋友不敢用压缩工具就是怕丢了原始信息导致AI产生幻觉,但Headroom会把原始数据完整保存在本地。
如果大模型在推理过程中发现压缩后的信息不够用,它可以随时通过检索工具把原件调出来看。
这种安全感是其他同类工具很难给的,让你既能享受低成本的好处,又不用担心关键线索被误删。
让我觉得惊喜的是跨智能体记忆共享功能。如果你像我一样同时用Claude、Codex或者Cursor等多个工具,Headroom能让它们共用一个压缩后的上下文存储区。
你在一个智能体里调试过的内容,换个智能体接着用时就不用重新喂一遍数据了,系统还会自动去重。
再加上那个叫headroomlearn的失败学习机制,它能从你过去的错误会话里挖掘经验,自动写到配置文件里提醒AI下次避坑,这简直就像是给AI装了个错题本。
集成方面也做得相当丝滑。不管你是想在Python或TypeScript项目里直接调用库函数,还是想0代码改动地挂个代理服务器,甚至是通过MCP协议接入,Headroom都提供了现成的方案。
登录/注册后继续阅读
立即登录/注册 >上一篇: 未来90%的职场竞争,可能会变成AI能力竞争 下一篇: 2026年,可能是学习AI最重要的一年
































