
我要认证
2026-06-04
说实话现在的AI越来越喜欢深度思考了,不管是解奥数题还是写复杂代码,模型都得先输出一大段推理过程才肯给答案。
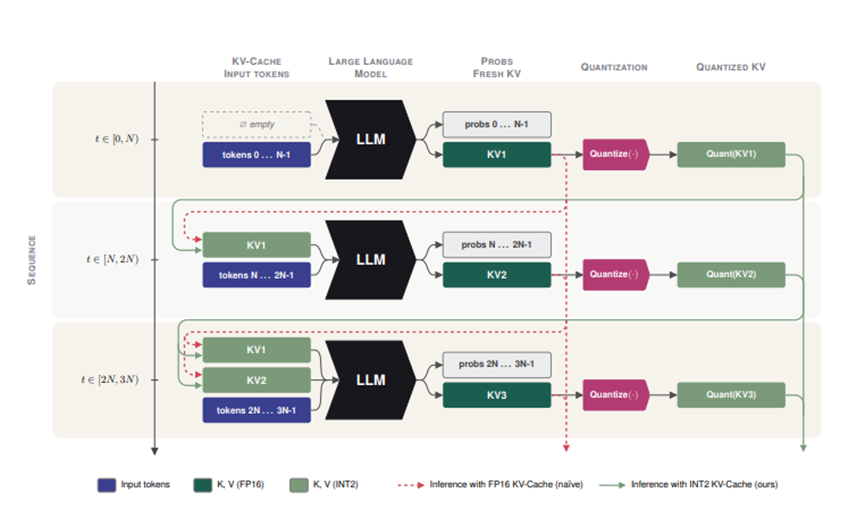
这套思路确实能明显拉高模型智商,但模型边生成内容边存储的注意力缓存会越堆越多,GPU显存会很快就被占满,想要批量部署商用就会受到限制。
所以,华为的AI研究团队刚开源了一个创新缓存量化方法KVarN,平均仅2.3比特存储KV数据,缓存压缩近7倍,就能实现几乎无损的缓存压缩效果。
并在多个高难度测试项目里直接刷新同规格压缩的最优成绩。

开源地址:https://github.com/huawei-csl/KVarN
KVarN强在哪
咱们要想看懂KVarN的厉害之处,就得先捋明白现有缓存压缩踩过的各种坑。
过往市面上主流的压缩算法做性能验证时,习惯性把整段文字一次性喂给模型再统一压缩缓存,这种环境下不存在分步生成带来的误差累积,测试数据看着全都很漂亮。
可落地到实际使用就原形毕露,现实里模型是一个字一个字往外生成新内容,攒够一小段文本才会压缩新增缓存,每一次压缩产生的微小错误,都会顺着后续每一轮推理不断放大叠加。
而研究团队在实验过程里找到了错误暴涨的核心根源,他们把压缩产生的错误拆分成两类。
一类是数据大小出现偏差带来的幅度错误,另一类是特征向量方向偏移形成的方向错误。
实测结果让人意外,占据大头的异常错误里,八成以上问题都来自数据大小失衡。
打个不太恰当的比方,有些字原本数值特别大,就像队伍里的大高个,结果压缩时发的小帽子统一尺寸,大高个被迫缩头缩脑,整个队形瞬间就散了。
而且排在前5%的极端错误,哪怕在整体误差数值里占比不高,却能直接毁掉模型最终的推理结果,修复这一小部分错误带来的收益,远胜过优化剩下绝大多数细碎偏差。
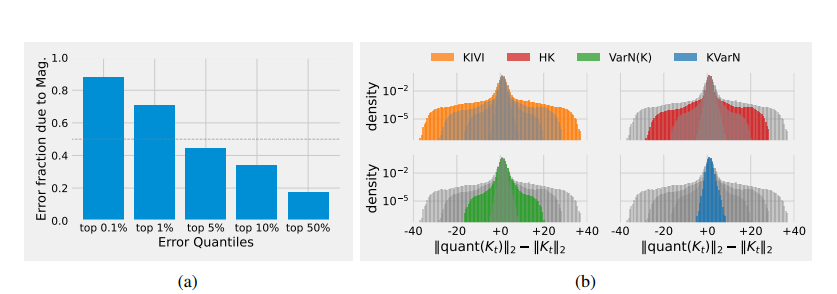
可惜老牌压缩算法大多只盯着特征通道做优化,完全忽略单个文本对应的数值缩放问题,自然拦不住误差随着上下文变长持续恶化。
现在市面上两条主流优化路线各有短板。第一种纯量化优化,有的靠矩阵旋转优化通道数据分布,管得了通道异常却控不住单条文本数值飘移。
第二种缓存删减优化,只会精简输入提示词对应的缓存,模型新生成内容全部保留原始精度,没办法解决长文本推理时缓存暴涨的问题,只能当成辅助优化手段。
所以,研究团队直接结合这两种经典优化思路,取长补短开发出了KVarN这套融合式压缩方案。
高效压缩
KVarN整套算法处理缓存分成三个连贯步骤,先做通道维度的矩阵旋转变换,再通过双方向方差均衡修正数据大小偏差,最后用就近取整完成低位量化。
日常处理数据会以128个字符为一个小分组,攒满一组数据再统一运算,全程不用提前收集样本做参数校准,完美适配模型边生成边压缩的运行模式。
最先落地的矩阵旋转步骤主要用来抹平通道维度的数据极端值,一部分运算参数能直接融合进模型原有权重,正式推理时不用额外消耗算力。
剩下跟着位置编码同步执行的实时旋转,整体运算成本极低,几乎不会拖累生成速度。
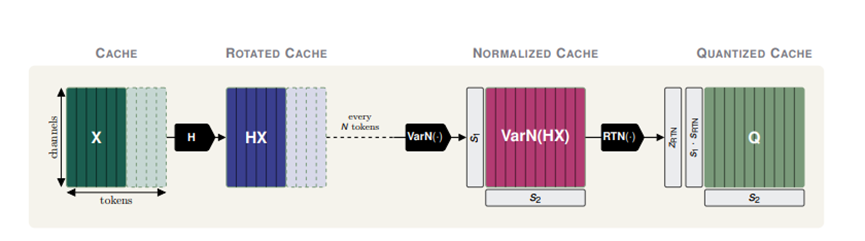
经过旋转处理后,杂乱的通道数据会变得分布均匀,从源头减少单通道数值突增引发的压缩失误。
方差归一化算是这套方案最亮眼的创新点,参考了过往权重量化里的双向缩放思路,专门适配动态生成的缓存数据。
面对每一个分组形成的二维数据块,算法会同时沿着字符方向和通道方向反复迭代调整缩放系数,迭代过程里持续监测两个维度的数据均衡程度,不断修正缩放参数范围。
登录/注册后继续阅读
立即登录/注册 >上一篇: 学完AI,然后呢?很多人卡在这里 下一篇: CAIE认证5月30日场次一级、二级考试考情结果通知































