
我要认证
2026-06-15
5分钟测出你真实AI能力、点击下方小程序
免费领取AI入门学习资料、全套题库

咱们聊到大模型部署,总有两个绕不过去的坎就是推理速度和成本。
你把模型辛辛苦苦训好了,往服务器上一放,用户一多,好家伙,响应慢得像蜗牛,算力账单倒是快得像火箭。
尤其是遇到那种长文本对话或者大规模文档检索的场景,每一轮提问模型都得从头把前面的话再算一遍,同样的话翻来覆去地算。
今天就给大家安利一个能大幅缓解这个痛点的开源项目LMCache,目前已经快9000星了。

开源地址:https://github.com/LMCache/LMCache
简单来说,LMCache就是一个给大模型推理加速的键值缓存管理层,专门用来存取和调度模型推理过程中产生的中间结果,好让后续请求能直接复用,省下大量重复计算。
咱打个比方,你读书时做的课堂笔记就是缓存,下次复习直接翻笔记就行,不用重新听一遍课。LMCache 就是帮你把大模型的课堂笔记管起来,随用随取,省时省力。
接着来聊聊LMCache具体能干什么。先说提示词缓存。咱们跟大模型聊天,每次发过去的上下文里其实有很大一部分是重复的,比如系统提示词和历史对话。
正常情况下模型每次都要重新处理这些内容,特别浪费算力。LMCache 会把处理过的键值向量缓存起来,下次遇到相同前缀直接复用。
带来的好处很明显,首轮之后的响应速度能提升好几倍,用户体验直接拉满,算力开销也跟着降下来了。
做检索增强生成也就是 RAG 场景的朋友应该深有体会。用户问一个问题,系统要从一堆文档里召回相关段落拼进提示词,这些段落动不动就好几千词。如果每次都要从头算,首字延迟高得让人抓狂。
LMCache的高明之处在于,可以预先把各个文档片段的键值缓存都算好存起来,查询的时候动态拼装,就像搭积木一样。首字延迟能降四到十倍,用户几乎感觉不到等待。
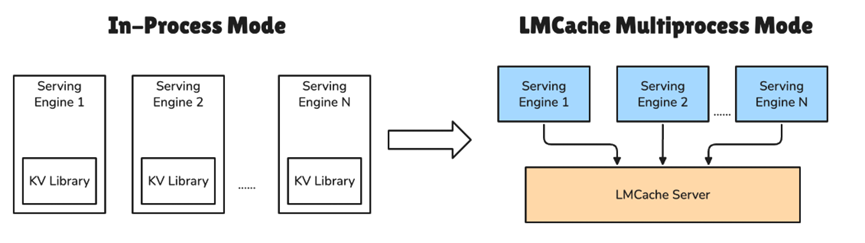
接下来这个功能我觉得特别亮眼,叫跨实例前缀共享。假设你有多个推理服务实例在跑,可能不同用户问不同问题,但系统提示词是一样的。
以前每个实例各算各的,纯属重复劳动。现在 LMCache 可以搭一个中央缓存服务器,让多个推理实例共享同一份前缀缓存。
就像多个部门共用一个资料室,谁需要谁去查,不用每个部门都自己复印一份。对集群部署的团队来说,这招能显著降低整体显存占用,省钱又高效。
登录/注册后继续阅读
立即登录/注册 >






























