
我要认证
2026-06-19
5分钟测出你真实AI能力、点击下方小程序
免费领取AI入门学习资料、全套题库

经常关注多模态技术的朋友应该都有同感,现在不管是闭源大模型还是开源视觉大模型,看图说话已经做得有模有样,但只要牵扯到真实空间判断就很容易翻车。
比如一张图里远近两个物体看着大小差不多,AI分不清谁实际尺寸更大,视频里物体来回移动被遮挡后,模型也记不住东西原本的位置,更别说计算物体之间精确距离和方位了。
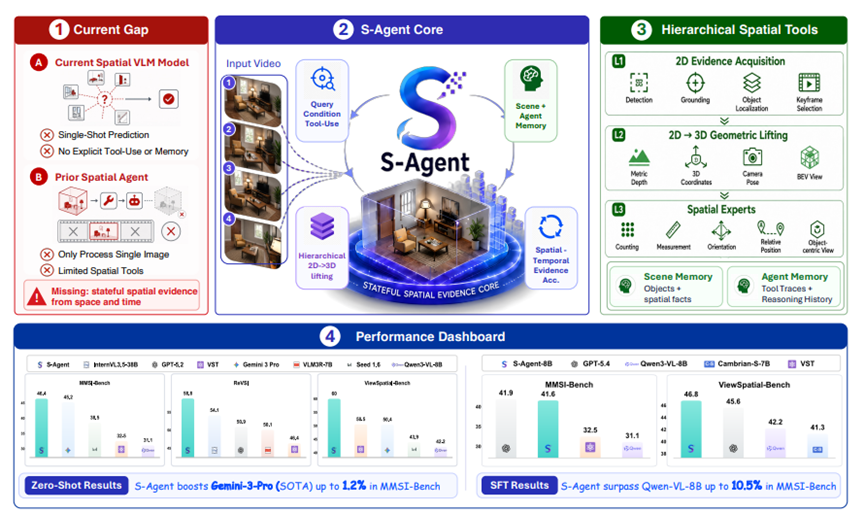
而清华大学、字节跳动等联合开发的创新智能体S-Agent专门根治AI空间推理能力薄弱的问题,并且很快就会开源。
论文:https://arxiv.org/pdf/2606.20515
现有视觉模型短板
先跟大家捋明白当下所有视觉模型的通病,就能看懂这套新框架到底强在哪。
绝大多数视觉语言模型的训练素材,都是单张二维图片搭配文本描述,模型只能学到画面表层的文字语义,没办法自主构建完整的三维空间认知。
就算前两年出现过一些搭配几何工具的AI方案,也只能单独处理单张静态图片,完全没办法连贯解析连续视频、多视角同场景图像。
我们真实生活的世界本身持续动态变化,相机移动、物体遮挡、画面信息碎片化都是常态,单张图片能提供的视觉线索永远残缺不全。
传统AI不会整合前后画面的信息,每一次识别画面都等于从头判断,不存在记忆环境、持续收集空间线索的能力。
打个通俗的比方,人类走进一间房间,就算视线被家具遮挡,心里也清楚沙发、桌子的大致方位;但过去的AI完全做不到这种带记忆的空间思考。
而S-Agent核心补齐两大关键能力,分层空间工具体系、双记忆存储机制。
像侦探一样循环推理
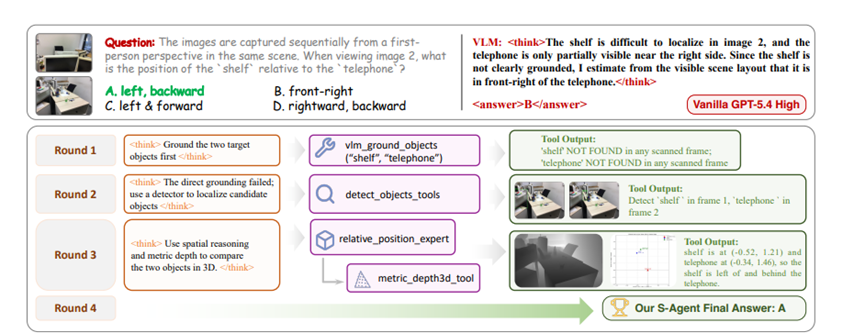
很多人会疑惑,为什么不能直接让大模型自己推算空间关系,非要额外搭配一套工具流水线。
其实道理很简单,大模型擅长语言逻辑梳理,却不擅长精准几何计算,就像擅长写文章的人未必能精准测算房间长宽,分开分工效率和准确率都会高很多。
整套工具分成三层,一层一层递进处理画面信息,每一层都有自己专属任务,不会出现信息混乱或者算力浪费的情况。
第一层负责原始画面信息筛选和物体定位,相当于整个流程的原料分拣员。一段视频里几十上百帧画面大部分内容重复,这一层工具会自动挑出包含问题目标的关键画面,再把画面里用户关心的物体框选出来。
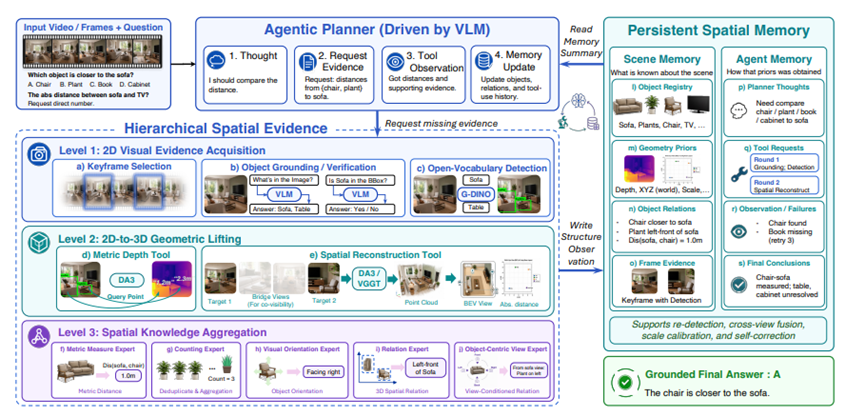
如果目标物体在多段画面里时隐时现,工具还会对比所有画面,选出物体看得最完整的那一帧锁定位置,给后续三维计算打下可靠基础。
这一层产出的信息足够回答简单问题,比如画面里有什么东西,一共有几件物品,复杂空间测算就需要交给下一层工具处理。
第二层专门做二维画面转三维空间换算,算是整套方案里的几何计算核心。依托成熟的深度重建模型,工具能把第一层框出来的物体,统一换算到一套标准三维空间坐标系里,算出物体真实长宽尺寸、距离镜头的远近,还有相机拍摄时的摆放角度。
这一步能完美解决二维画面带来的视觉欺骗,远处的大树和近处的小凳子在图里看着差不多大,经过三维换算就能立刻区分真实体积差距。
这里要提一句,一层只会输出原始几何数据,密密麻麻的坐标数值直接丢给大模型只会造成信息过载,所有计算结果都会输送到第三层做简化整理。
第三层是整套工具链的信息翻译官,也是提升模型效果最关键的一环。研究团队设计了五类专用工具,分别对应日常最常遇到的空间问题,把杂乱的坐标深度数据转化成直白结论。
测试数据
登录/注册后继续阅读
立即登录/注册 >





























