
我要认证
2026-06-20
5分钟测出你真实AI能力、点击下方小程序
免费领取AI入门学习资料、全套题库

做文档处理这件事听起来简单,实际做过的朋友都知道里面有多少坑。
平时拿到一堆排版花里胡哨的PDF发票或者超长合同,想把里面的关键金额和明细提取出来变成结构化数据,传统方案真的能让人崩溃。
你要么靠正则表达式写到手抽筋,要么搞个OCR识别完文字,再自己写一堆逻辑去拼凑上下文,碰上跨页的表格基本就直接放弃挣扎了。
Datalab的创始人刚刚宣布开源了一个王炸模型Lift。参数只有90亿,单卡就能跑起来,但在文档提取方面效率奇高!

开源地址:https://github.com/datalab-to/lift
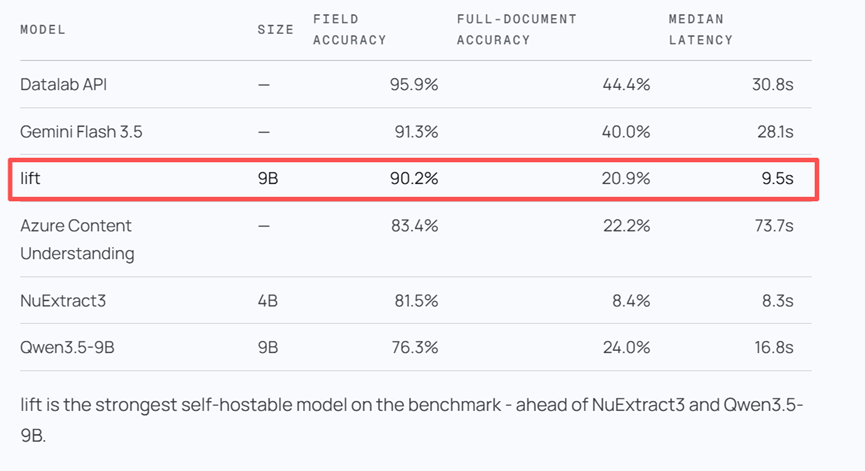
咱们先看最硬核的跑分数据。在他们搞的那个相当刁钻的测试集里,总共225篇文档每篇页数从6到64页不等,加起来大约有11000个待提取的字段。
Lift直接拿到了90.2%的字段准确率。这个成绩在同体量能自己部署的模型里属于断层领先,甚至能跟那些体积庞大收费昂贵的闭源大模型掰掰手腕。
离谱的是它的速度,处理一篇文档的中位数时间只要不到10秒的时间,比那些准确率差不多的模型快了整整三四倍。可以说是又快又准,单卡跑起来毫无压力。
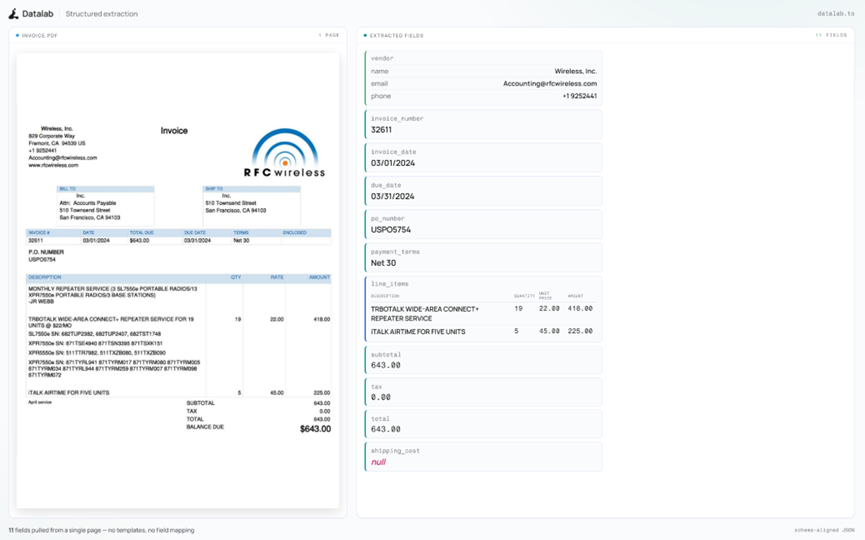
说到它的用法其实非常干净利落。你写一个标准的结构定义,把发票号或者总金额这些需求列出来,然后把文档丢给它就行。
Lift会非常老实逐字段地从页面上读取内容,最后返回的数据格式永远合规不会出什么幺蛾子。
这里有一个设计细节我真的想夸一句,被训练成在文档里确实找不到某个字段的时候会直接返回空值,而不是在那瞎编乱造。
这太关键了。你想想如果一个模型文档里压根没有税号这个字段,非要给你编一个出来,这种沉默的错误你根本排查不到。Lift这种克制的老实态度反而让它在实际业务里极其可靠。
再看看同行衬托的对比测试就更明显了。同场竞技的微软Azure内容理解工具准确率只有83.4%,而且慢得要命处理一份要花73.7秒。
同体量的通义千问Qwen3.5只有76.3%的准确率,另一个叫NuExtract3的模型也就81.5%。
Lift在这个区间里真的是神挡杀神。就算对比那些闭源巨头比如Gemini Flash拿到91.3%的准确率但需要28.1秒,Lift用微小的准确率牺牲换来了成倍的速度提升。
登录/注册后继续阅读
立即登录/注册 >





























